 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronic Stress, Immune Suppression, and Cancer Occurrence: Unveiling the Connection using Survey Data and Predictive Models
Sep 26, 2025Chronic stress was implicated in cancer occurrence, but a direct causal connection has not been consistently established. Machine learning and causal modeling offer opportunities to explore complex causal interactions between psychological chronic stress and cancer occurrences. We developed predictive models employing variables from stress indicators, cancer history, and demographic data from self-reported surveys, unveiling the direct and immune suppression mitigated connection between chronic stress and cancer occurrence. The models were corroborated by traditional statistical methods. Our findings indicated significant causal correlations between stress frequency, stress level and perceived health impact, and cancer incidence. Although stress alone showed limited predictive power, integrating socio-demographic and familial cancer history data significantly enhanced model accuracy. These results highlight the multidimensional nature of cancer risk, with stress emerging as a notable factor alongside genetic predisposition. These findings strengthen the case for addressing chronic stress as a modifiable cancer risk factor, supporting its integration into personalized prevention strategies and public health interventions to reduce cancer incidence.
Accelerating Reinforcement Learning Algorithms Convergence using Pre-trained Large Language Models as Tutors With Advice Reusing
Sep 10, 2025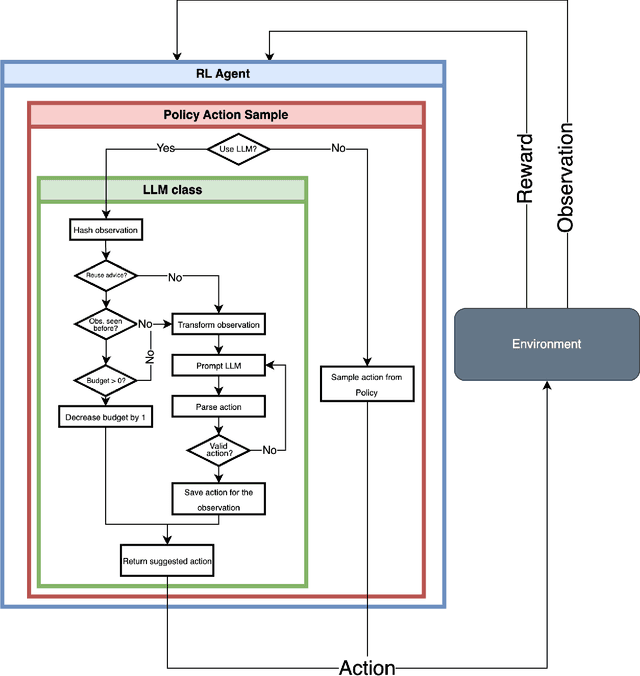
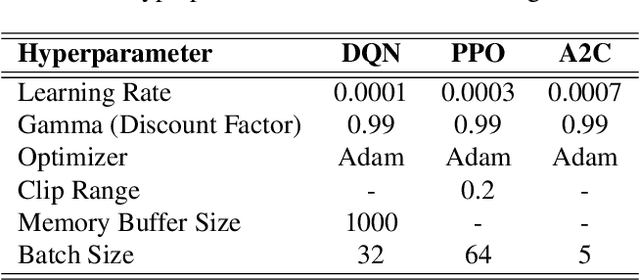
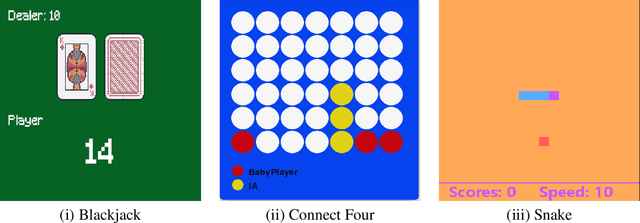
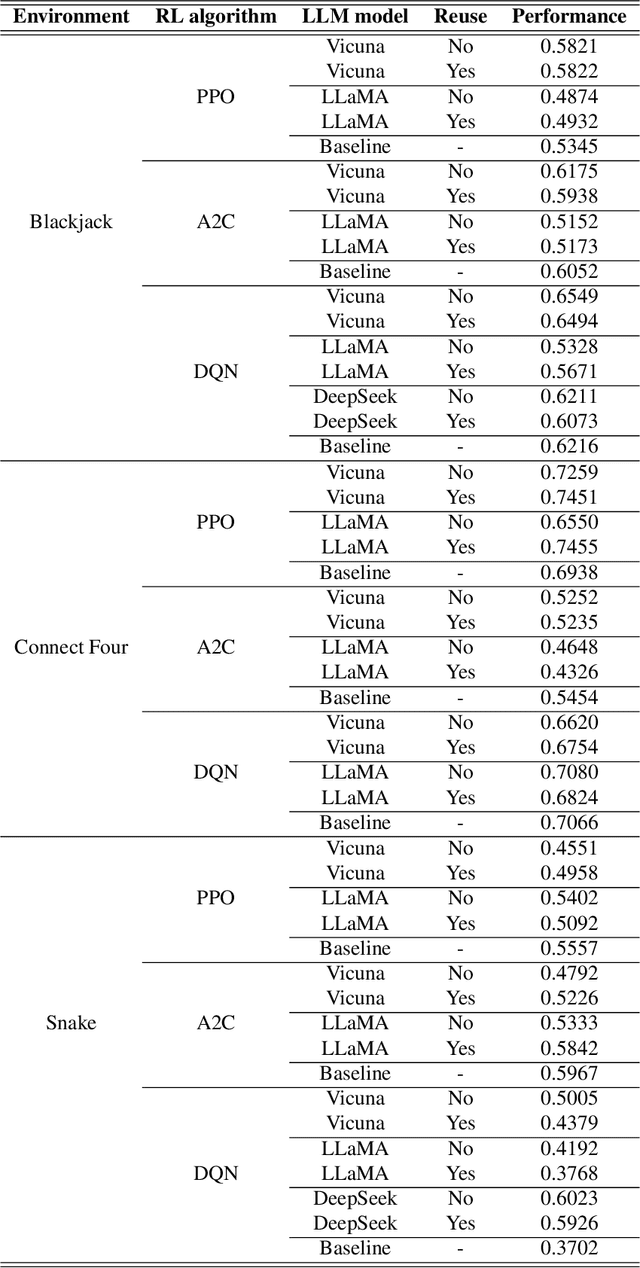
Reinforcement Learning (RL) algorithms often require long training to become useful, especially in complex environments with sparse rewards. While techniques like reward shaping and curriculum learning exist to accelerate training, these are often extremely specific and require the developer's professionalism and dedicated expertise in the problem's domain. Tackling this challenge, in this study, we explore the effectiveness of pre-trained Large Language Models (LLMs) as tutors in a student-teacher architecture with RL algorithms, hypothesizing that LLM-generated guidance allows for faster convergence. In particular, we explore the effectiveness of reusing the LLM's advice on the RL's convergence dynamics. Through an extensive empirical examination, which included 54 configurations, varying the RL algorithm (DQN, PPO, A2C), LLM tutor (Llama, Vicuna, DeepSeek), and environment (Blackjack, Snake, Connect Four), our results demonstrate that LLM tutoring significantly accelerates RL convergence while maintaining comparable optimal performance. Furthermore, the advice reuse mechanism shows a further improvement in training duration but also results in less stable convergence dynamics. Our findings suggest that LLM tutoring generally improves convergence, and its effectiveness is sensitive to the specific task, RL algorithm, and LLM model combination.
Interpretable Transformation and Analysis of Timelines through Learning via Surprisability
Mar 06, 2025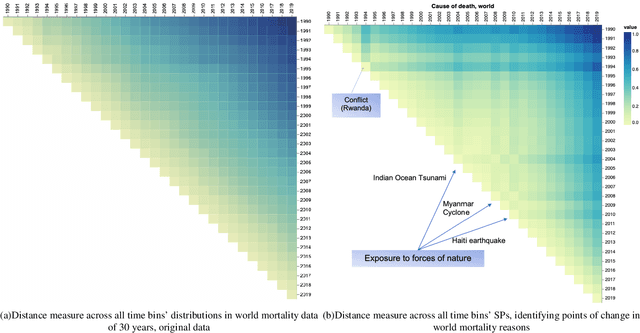
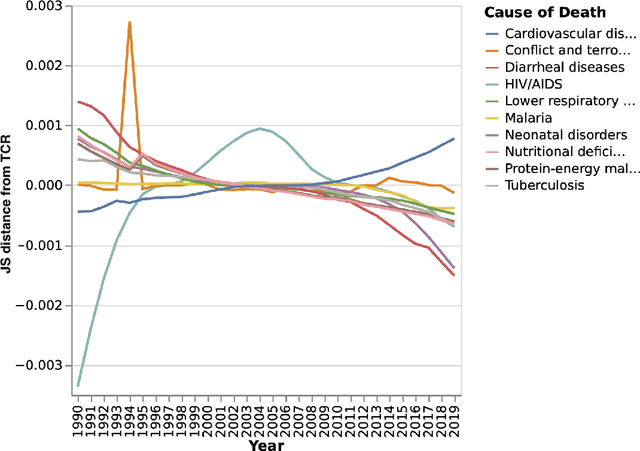
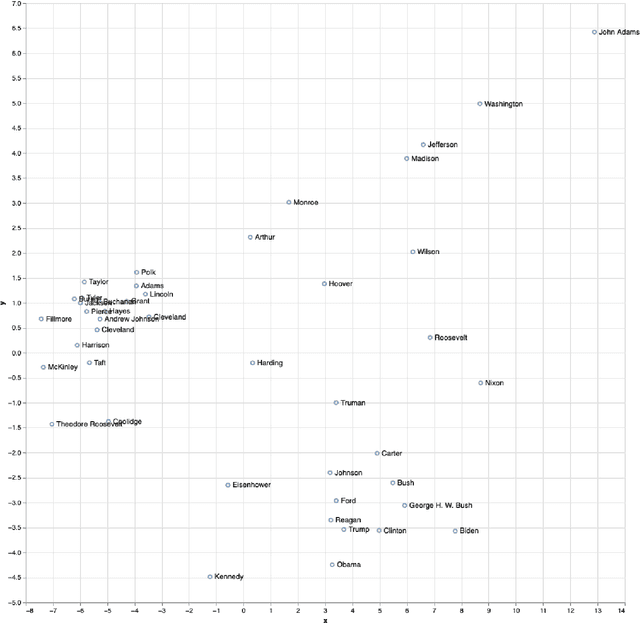
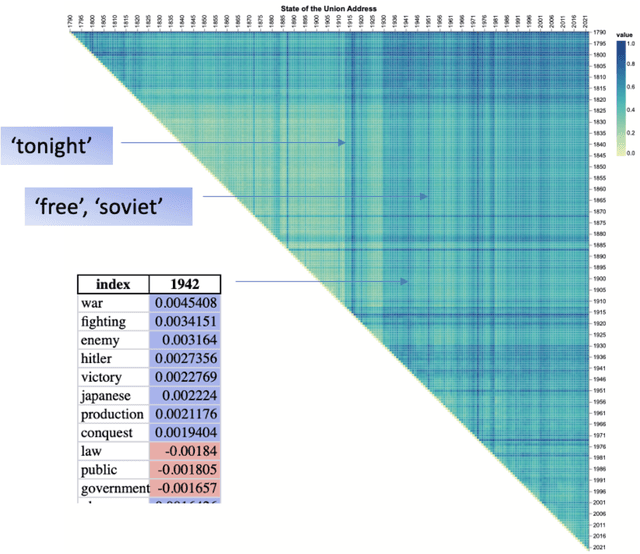
The analysis of high-dimensional timeline data and the identification of outliers and anomalies is critical across diverse domains, including sensor readings, biological and medical data, historical records, and global statistics. However, conventional analysis techniques often struggle with challenges such as high dimensionality, complex distributions, and sparsity. These limitations hinder the ability to extract meaningful insights from complex temporal datasets, making it difficult to identify trending features, outliers, and anomalies effectively. Inspired by surprisability -- a cognitive science concept describing how humans instinctively focus on unexpected deviations - we propose Learning via Surprisability (LvS), a novel approach for transforming high-dimensional timeline data. LvS quantifies and prioritizes anomalies in time-series data by formalizing deviations from expected behavior. LvS bridges cognitive theories of attention with computational methods, enabling the detection of anomalies and shifts in a way that preserves critical context, offering a new lens for interpreting complex datasets. We demonstrate the usefulness of LvS on three high-dimensional timeline use cases: a time series of sensor data, a global dataset of mortality causes over multiple years, and a textual corpus containing over two centuries of State of the Union Addresses by U.S. presidents. Our results show that the LvS transformation enables efficient and interpretable identification of outliers, anomalies, and the most variable features along the timeline.
Tighten The Lasso: A Convex Hull Volume-based Anomaly Detection Method
Feb 25, 2025The rapid advancements in data-driven methodologies have underscored the critical importance of ensuring data quality. Consequently, detecting out-of-distribution (OOD) data has emerged as an essential task to maintain the reliability and robustness of data-driven models, in general, and machine and deep learning models, in particular. In this study, we leveraged the convex hull property of a dataset and the fact that anomalies highly contribute to the increase of the CH's volume to propose a novel anomaly detection algorithm. Our algorithm computes the CH's volume as an increasing number of data points are removed from the dataset to define a decision line between OOD and in-distribution data points. We compared the proposed algorithm to seven widely used anomaly detection algorithms over ten datasets, showing comparable results for state-of-the-art (SOTA) algorithms. Moreover, we show that with a computationally cheap and simple check, one can detect datasets that are well-suited for the proposed algorithm which outperforms the SOTA anomaly detection algorithms.
Investigating Tax Evasion Emergence Using Dual Large Language Model and Deep Reinforcement Learning Powered Agent-based Simulation
Jan 30, 2025



Tax evasion, usually the largest component of an informal economy, is a persistent challenge over history with significant socio-economic implications. Many socio-economic studies investigate its dynamics, including influencing factors, the role and influence of taxation policies, and the prediction of the tax evasion volume over time. These studies assumed such behavior is given, as observed in the real world, neglecting the "big bang" of such activity in a population. To this end, computational economy studies adopted developments in computer simulations, in general, and recent innovations in artificial intelligence (AI), in particular, to simulate and study informal economy appearance in various socio-economic settings. This study presents a novel computational framework to examine the dynamics of tax evasion and the emergence of informal economic activity. Employing an agent-based simulation powered by Large Language Models and Deep Reinforcement Learning, the framework is uniquely designed to allow informal economic behaviors to emerge organically, without presupposing their existence or explicitly signaling agents about the possibility of evasion. This provides a rigorous approach for exploring the socio-economic determinants of compliance behavior. The experimental design, comprising model validation and exploratory phases, demonstrates the framework's robustness in replicating theoretical economic behaviors. Findings indicate that individual personality traits, external narratives, enforcement probabilities, and the perceived efficiency of public goods provision significantly influence both the timing and extent of informal economic activity. The results underscore that efficient public goods provision and robust enforcement mechanisms are complementary; neither alone is sufficient to curtail informal activity effectively.
An Empirically-parametrized Spatio-Temporal Extended-SIR Model for Combined Dilution and Vaccination Mitigation for Rabies Outbreaks in Wild Jackals
Jan 26, 2025
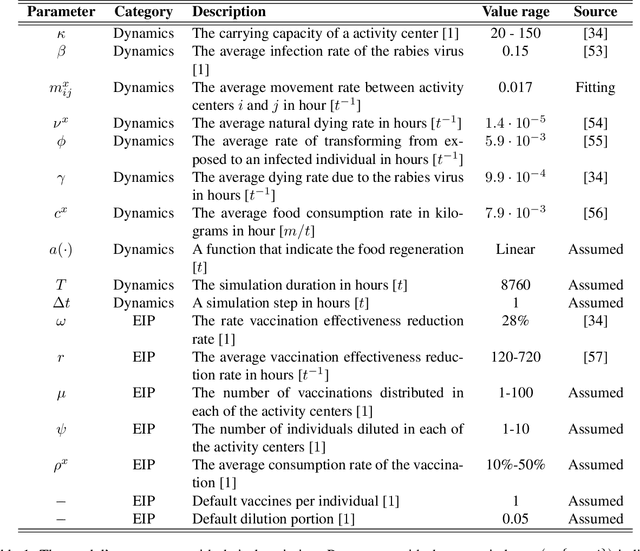


The transmission of zoonotic diseases between animals and humans poses an increasing threat. Rabies is a prominent example with various instances globally, facilitated by a surplus of meso-predators (commonly, facultative synanthropic species e.g., golden jackals [Canis aureus, hereafter jackals]) thanks to the abundance of anthropogenic resources leading to dense populations close to human establishments. To mitigate rabies outbreaks and prevent human infections, authorities target the jackal which is the main rabies vector in many regions, through the dissemination of oral vaccines in known jackals' activity centers, as well as opportunistic culling to reduce population density. Because dilution (i.e., culling) is not selective towards sick or un-vaccinated individuals, these two complementary epizootic intervention policies (EIPs) can interfere with each other. Nonetheless, there is only limited examination of the interactive effectiveness of these EIPs and their potential influence on rabies epizootic spread dynamics, highlighting the need to understand these measures and the spread of rabies in wild jackals. In this study, we introduce a novel spatio-temporal extended-SIR (susceptible-infected-recovered) model with a graph-based spatial framework for evaluating mitigation efficiency. We implement the model in a case study using a jackal population in northern Israel, and using spatial and movement data collected by Advanced Tracking and Localization of Animals in real-life Systems (ATLAS) telemetry. An agent-based simulation approach allows us to explore various biologically-realistic scenarios, and assess the impact of different EIPs configurations. Our model suggests that under biologically-realistic underlying assumptions and scenarios, the effectiveness of both EIPs is not influenced much by the jackal population size but is sensitive to their dispersal between activity centers.
Data Augmentation for Deep Learning Regression Tasks by Machine Learning Models
Jan 07, 2025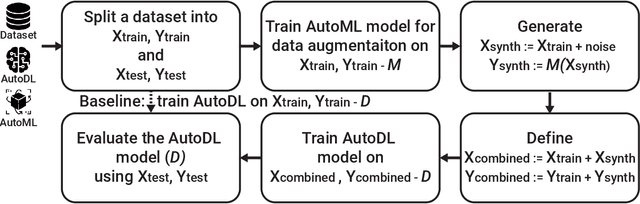
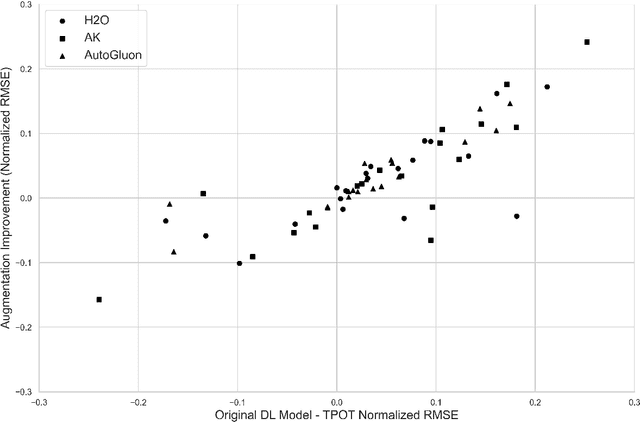
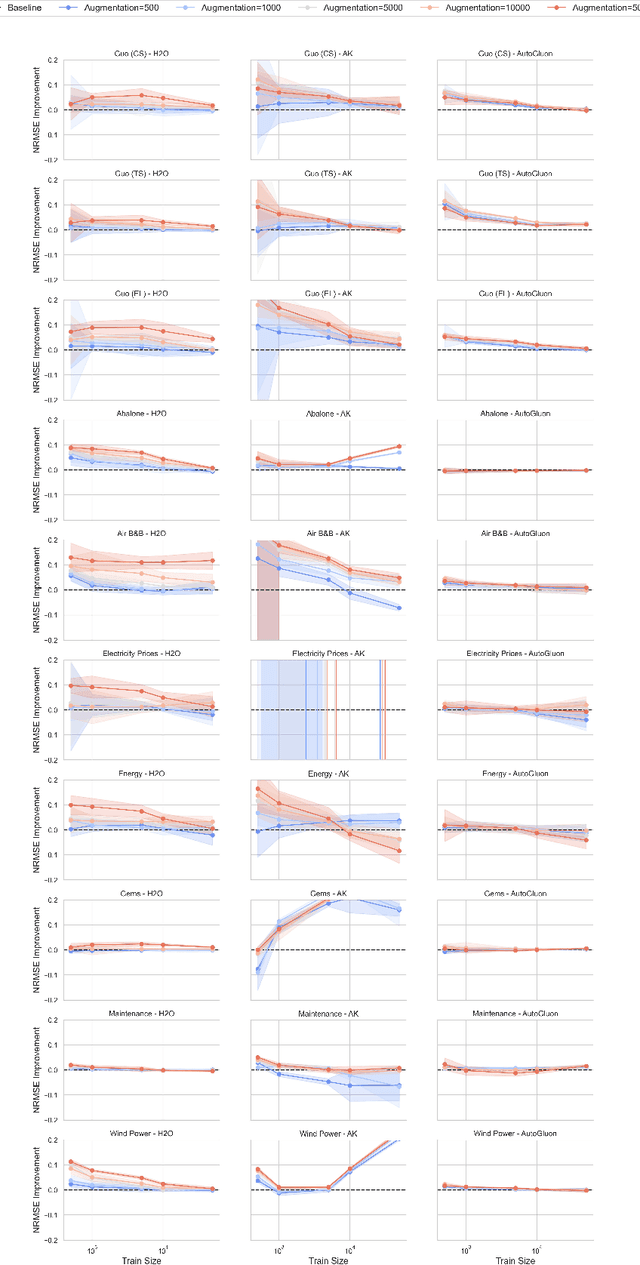
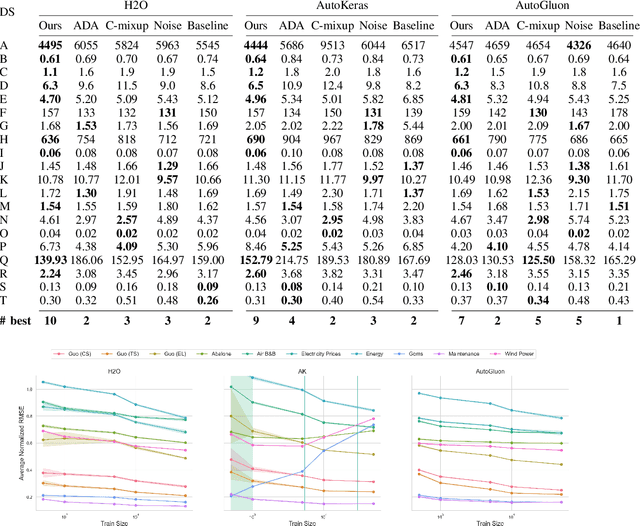
Deep learning (DL) models have gained prominence in domains such as computer vision and natural language processing but remain underutilized for regression tasks involving tabular data. In these cases, traditional machine learning (ML) models often outperform DL models. In this study, we propose and evaluate various data augmentation (DA) techniques to improve the performance of DL models for tabular data regression tasks. We compare the performance gain of Neural Networks by different DA strategies ranging from a naive method of duplicating existing observations and adding noise to a more sophisticated DA strategy that preserves the underlying statistical relationship in the data. Our analysis demonstrates that the advanced DA method significantly improves DL model performance across multiple datasets and regression tasks, resulting in an average performance increase of over 10\% compared to baseline models without augmentation. The efficacy of these DA strategies was rigorously validated across 30 distinct datasets, with multiple iterations and evaluations using three different automated deep learning (AutoDL) frameworks: AutoKeras, H2O, and AutoGluon. This study demonstrates that by leveraging advanced DA techniques, DL models can realize their full potential in regression tasks, thereby contributing to broader adoption and enhanced performance in practical applications.
Spatio-Temporal SIR Model of Pandemic Spread During Warfare with Optimal Dual-use Healthcare System Administration using Deep Reinforcement Learning
Dec 18, 2024Large-scale crises, including wars and pandemics, have repeatedly shaped human history, and their simultaneous occurrence presents profound challenges to societies. Understanding the dynamics of epidemic spread during warfare is essential for developing effective containment strategies in complex conflict zones. While research has explored epidemic models in various settings, the impact of warfare on epidemic dynamics remains underexplored. In this study, we proposed a novel mathematical model that integrates the epidemiological SIR (susceptible-infected-recovered) model with the war dynamics Lanchester model to explore the dual influence of war and pandemic on a population's mortality. Moreover, we consider a dual-use military and civil healthcare system that aims to reduce the overall mortality rate which can use different administration policies. Using an agent-based simulation to generate in silico data, we trained a deep reinforcement learning model for healthcare administration policy and conducted an intensive investigation on its performance. Our results show that a pandemic during war conduces chaotic dynamics where the healthcare system should either prioritize war-injured soldiers or pandemic-infected civilians based on the immediate amount of mortality from each option, ignoring long-term objectives. Our findings highlight the importance of integrating conflict-related factors into epidemic modeling to enhance preparedness and response strategies in conflict-affected areas.
Pulling the Carpet Below the Learner's Feet: Genetic Algorithm To Learn Ensemble Machine Learning Model During Concept Drift
Dec 12, 2024Data-driven models, in general, and machine learning (ML) models, in particular, have gained popularity over recent years with an increased usage of such models across the scientific and engineering domains. When using ML models in realistic and dynamic environments, users need to often handle the challenge of concept drift (CD). In this study, we explore the application of genetic algorithms (GAs) to address the challenges posed by CD in such settings. We propose a novel two-level ensemble ML model, which combines a global ML model with a CD detector, operating as an aggregator for a population of ML pipeline models, each one with an adjusted CD detector by itself responsible for re-training its ML model. In addition, we show one can further improve the proposed model by utilizing off-the-shelf automatic ML methods. Through extensive synthetic dataset analysis, we show that the proposed model outperforms a single ML pipeline with a CD algorithm, particularly in scenarios with unknown CD characteristics. Overall, this study highlights the potential of ensemble ML and CD models obtained through a heuristic and adaptive optimization process such as the GA one to handle complex CD events.
Global Lightning-Ignited Wildfires Prediction and Climate Change Projections based on Explainable Machine Learning Models
Sep 16, 2024Wildfires pose a significant natural disaster risk to populations and contribute to accelerated climate change. As wildfires are also affected by climate change, extreme wildfires are becoming increasingly frequent. Although they occur less frequently globally than those sparked by human activities, lightning-ignited wildfires play a substantial role in carbon emissions and account for the majority of burned areas in certain regions. While existing computational models, especially those based on machine learning, aim to predict lightning-ignited wildfires, they are typically tailored to specific regions with unique characteristics, limiting their global applicability. In this study, we present machine learning models designed to characterize and predict lightning-ignited wildfires on a global scale. Our approach involves classifying lightning-ignited versus anthropogenic wildfires, and estimating with high accuracy the probability of lightning to ignite a fire based on a wide spectrum of factors such as meteorological conditions and vegetation. Utilizing these models, we analyze seasonal and spatial trends in lightning-ignited wildfires shedding light on the impact of climate change on this phenomenon. We analyze the influence of various features on the models using eXplainable Artificial Intelligence (XAI) frameworks. Our findings highlight significant global differences between anthropogenic and lightning-ignited wildfires. Moreover, we demonstrate that, even over a short time span of less than a decade, climate changes have steadily increased the global risk of lightning-ignited wildfires. This distinction underscores the imperative need for dedicated predictive models and fire weather indices tailored specifically to each type of wildfire.