 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Transformation and Analysis of Timelines through Learning via Surprisability
Paper and Code
Mar 06, 2025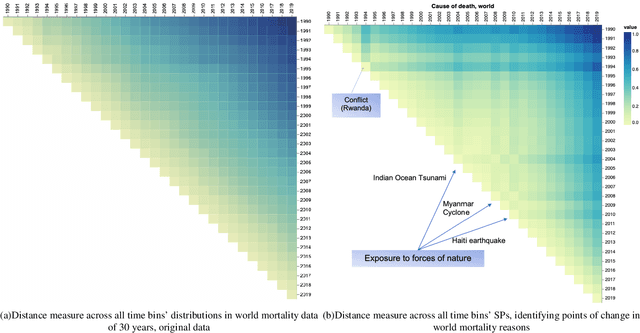
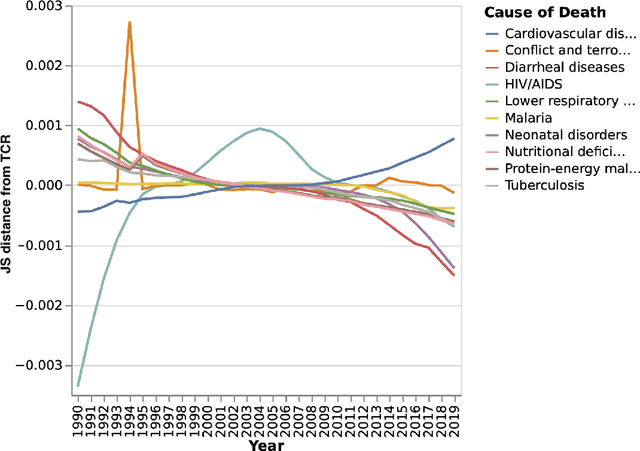
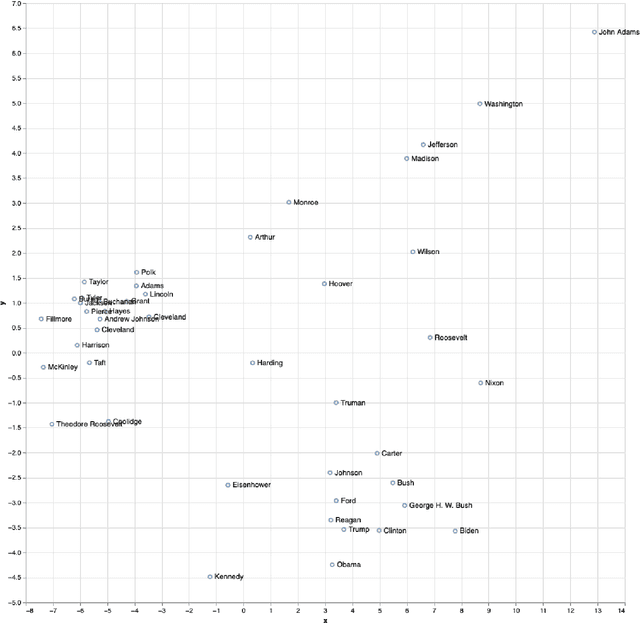
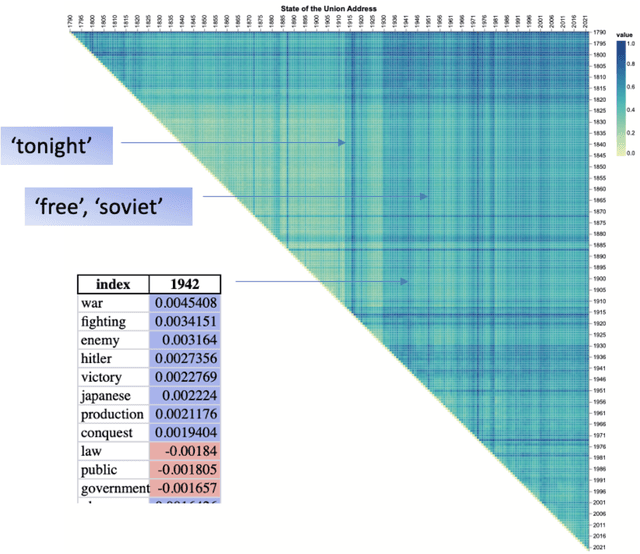
The analysis of high-dimensional timeline data and the identification of outliers and anomalies is critical across diverse domains, including sensor readings, biological and medical data, historical records, and global statistics. However, conventional analysis techniques often struggle with challenges such as high dimensionality, complex distributions, and sparsity. These limitations hinder the ability to extract meaningful insights from complex temporal datasets, making it difficult to identify trending features, outliers, and anomalies effectively. Inspired by surprisability -- a cognitive science concept describing how humans instinctively focus on unexpected deviations - we propose Learning via Surprisability (LvS), a novel approach for transforming high-dimensional timeline data. LvS quantifies and prioritizes anomalies in time-series data by formalizing deviations from expected behavior. LvS bridges cognitive theories of attention with computational methods, enabling the detection of anomalies and shifts in a way that preserves critical context, offering a new lens for interpreting complex datasets. We demonstrate the usefulness of LvS on three high-dimensional timeline use cases: a time series of sensor data, a global dataset of mortality causes over multiple years, and a textual corpus containing over two centuries of State of the Union Addresses by U.S. presidents. Our results show that the LvS transformation enables efficient and interpretable identification of outliers, anomalies, and the most variable features along the timeline.