 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Making Absence Visible in Intelligent Summarization Interfaces
Jan 12, 2026Intelligent interfaces increasingly use large language models to summarize user-generated content, yet these summaries emphasize what is mentioned while overlooking what is missing. This presence bias can mislead users who rely on summaries to make decisions. We present Domain Informed Summarization through Contrast (DiSCo), an expectation-based computational approach that makes absences visible by comparing each entity's content with domain topical expectations captured in reference distributions of aspects typically discussed in comparable accommodations. This comparison identifies aspects that are either unusually emphasized or missing relative to domain norms and integrates them into the generated text. In a user study across three accommodation domains, namely ski, beach, and city center, DiSCo summaries were rated as more detailed and useful for decision making than baseline large language model summaries, although slightly harder to read. The findings show that modeling expectations reduces presence bias and improves both transparency and decision support in intelligent summarization interfaces.
Making Absence Visible: The Roles of Reference and Prompting in Recognizing Missing Information
Jan 12, 2026Interactive systems that explain data, or support decision making often emphasize what is present while overlooking what is expected but missing. This presence bias limits users' ability to form complete mental models of a dataset or situation. Detecting absence depends on expectations about what should be there, yet interfaces rarely help users form such expectations. We present an experimental study examining how reference framing and prompting influence people's ability to recognize expected but missing categories in datasets. Participants compared distributions across three domains (energy, wealth, and regime) under two reference conditions: Global, presenting a unified population baseline, and Partial, showing several concrete exemplars. Results indicate that absence detection was higher with Partial reference than with Global reference, suggesting that partial, samples-based framing can support expectation formation and absence detection. When participants were prompted to look for what was missing, absence detection rose sharply. We discuss implications for interactive user interfaces and expectation-based visualization design, while considering cognitive trade-offs of reference structures and guided attention.
Interpretable Transformation and Analysis of Timelines through Learning via Surprisability
Mar 06, 2025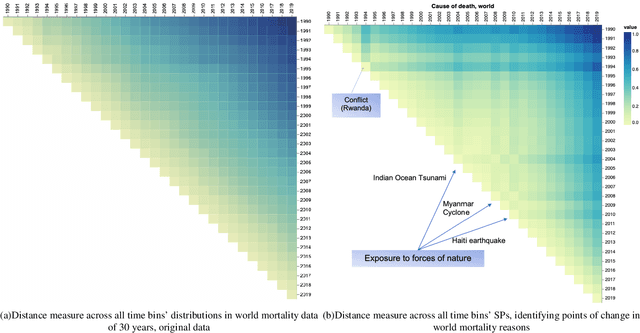
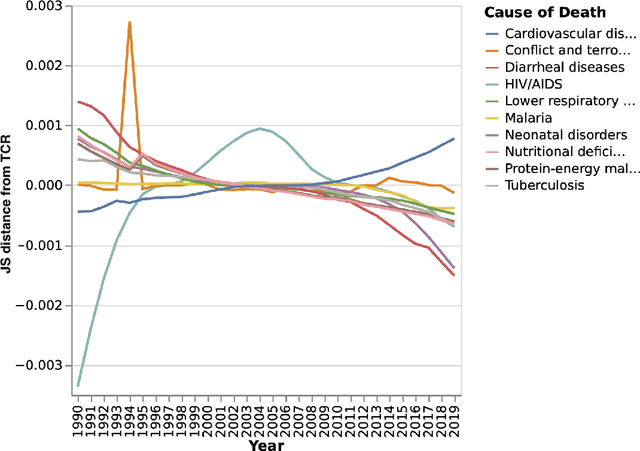
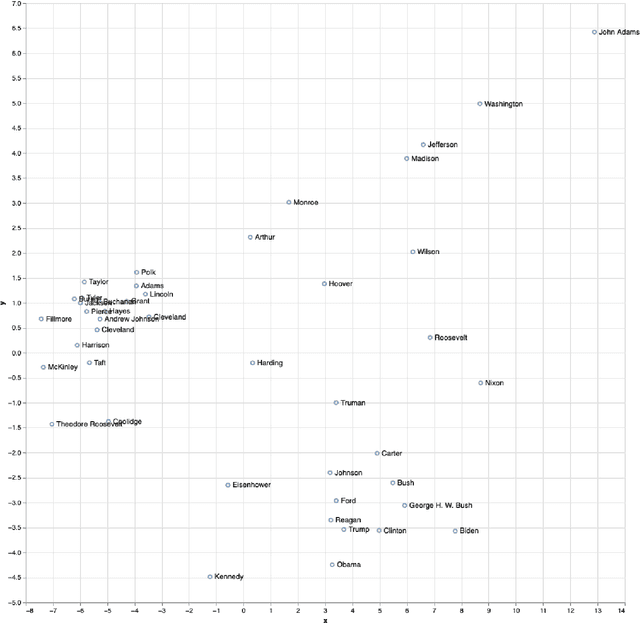
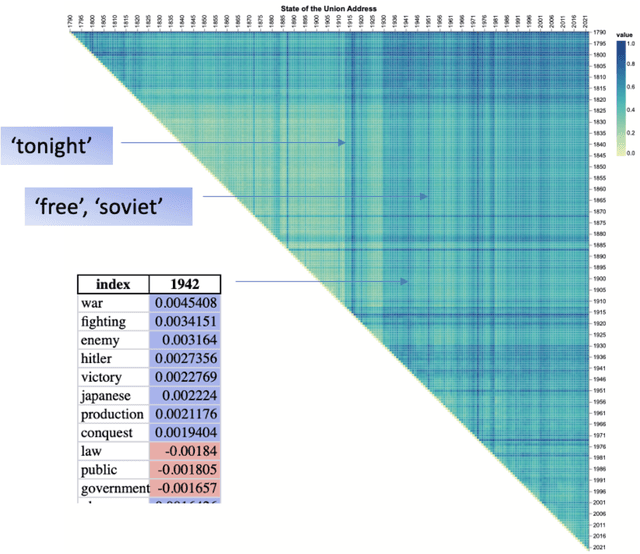
The analysis of high-dimensional timeline data and the identification of outliers and anomalies is critical across diverse domains, including sensor readings, biological and medical data, historical records, and global statistics. However, conventional analysis techniques often struggle with challenges such as high dimensionality, complex distributions, and sparsity. These limitations hinder the ability to extract meaningful insights from complex temporal datasets, making it difficult to identify trending features, outliers, and anomalies effectively. Inspired by surprisability -- a cognitive science concept describing how humans instinctively focus on unexpected deviations - we propose Learning via Surprisability (LvS), a novel approach for transforming high-dimensional timeline data. LvS quantifies and prioritizes anomalies in time-series data by formalizing deviations from expected behavior. LvS bridges cognitive theories of attention with computational methods, enabling the detection of anomalies and shifts in a way that preserves critical context, offering a new lens for interpreting complex datasets. We demonstrate the usefulness of LvS on three high-dimensional timeline use cases: a time series of sensor data, a global dataset of mortality causes over multiple years, and a textual corpus containing over two centuries of State of the Union Addresses by U.S. presidents. Our results show that the LvS transformation enables efficient and interpretable identification of outliers, anomalies, and the most variable features along the timeline.
AI-Augmented Brainwriting: Investigating the use of LLMs in group ideation
Feb 29, 2024



The growing availability of generative AI technologies such as large language models (LLMs) has significant implications for creative work. This paper explores twofold aspects of integrating LLMs into the creative process - the divergence stage of idea generation, and the convergence stage of evaluation and selection of ideas. We devised a collaborative group-AI Brainwriting ideation framework, which incorporated an LLM as an enhancement into the group ideation process, and evaluated the idea generation process and the resulted solution space. To assess the potential of using LLMs in the idea evaluation process, we design an evaluation engine and compared it to idea ratings assigned by three expert and six novice evaluators. Our findings suggest that integrating LLM in Brainwriting could enhance both the ideation process and its outcome. We also provide evidence that LLMs can support idea evaluation. We conclude by discussing implications for HCI education and practice.
Domain-based Latent Personal Analysis and its use for impersonation detection in social media
Apr 05, 2020
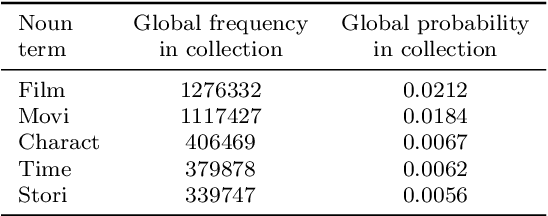


Zipf's law defines an inverse proportion between a word's ranking in a given corpus and its frequency in it, roughly dividing the vocabulary to frequent (popular) words and infrequent ones. Here, we stipulate that within a domain an author's signature can be derived from, in loose terms, the author's missing popular words and frequently used infrequent-words. We devise a method, termed Latent Personal Analysis (LPA), for finding such domain-based personal signatures. LPA determines what words most contributed to the distance between a user's vocabulary from the domain's. We identify the most suitable distance metric for the method among several and construct a personal signature for authors. We validate the correctness and power of the signatures in identifying authors and utilize LPA to identify two types of impersonation in social media: (1) authors with sockpuppets (multiple) accounts; (2) front-user accounts, operated by several authors. We validate the algorithms and employ them over a large scale dataset obtained from a social media site with over 4000 accounts, and corroborate the results employing temporal rate analysis. LPA can be used to devise personal signatures in a wide range of scientific domains in which the constituents have a long-tail distribution of elements.