Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquiring Lexical Paraphrases from a Single Corpus
Paper and Code
Dec 25, 2003

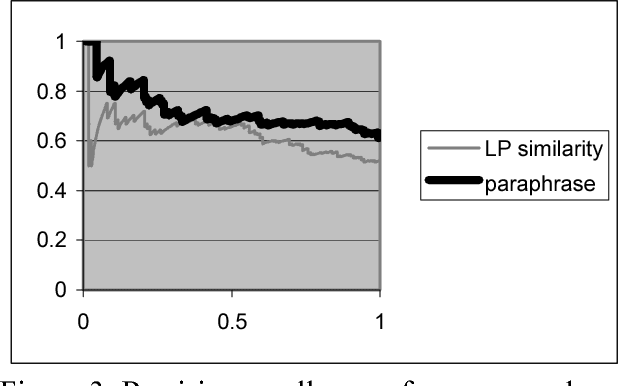
This paper studies the potential of identifying lexical paraphrases within a single corpus, focusing on the extraction of verb paraphrases. Most previous approaches detect individual paraphrase instances within a pair (or set) of comparable corpora, each of them containing roughly the same information, and rely on the substantial level of correspondence of such corpora. We present a novel method that successfully detects isolated paraphrase instances within a single corpus without relying on any a-priori structure and information. A comparison suggests that an instance-based approach may be combined with a vector based approach in order to assess better the paraphrase likelihood for many verb pairs.
View paper on