 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Decision Transformers (QDT): Synergistic Entanglement and Interference for Offline Reinforcement Learning
Dec 09, 2025



Offline reinforcement learning enables policy learning from pre-collected datasets without environment interaction, but existing Decision Transformer (DT) architectures struggle with long-horizon credit assignment and complex state-action dependencies. We introduce the Quantum Decision Transformer (QDT), a novel architecture incorporating quantum-inspired computational mechanisms to address these challenges. Our approach integrates two core components: Quantum-Inspired Attention with entanglement operations that capture non-local feature correlations, and Quantum Feedforward Networks with multi-path processing and learnable interference for adaptive computation. Through comprehensive experiments on continuous control tasks, we demonstrate over 2,000\% performance improvement compared to standard DTs, with superior generalization across varying data qualities. Critically, our ablation studies reveal strong synergistic effects between quantum-inspired components: neither alone achieves competitive performance, yet their combination produces dramatic improvements far exceeding individual contributions. This synergy demonstrates that effective quantum-inspired architecture design requires holistic co-design of interdependent mechanisms rather than modular component adoption. Our analysis identifies three key computational advantages: enhanced credit assignment through non-local correlations, implicit ensemble behavior via parallel processing, and adaptive resource allocation through learnable interference. These findings establish quantum-inspired design principles as a promising direction for advancing transformer architectures in sequential decision-making, with implications extending beyond reinforcement learning to neural architecture design more broadly.
Human-Oriented Image Retrieval System (HORSE): A Neuro-Symbolic Approach to Optimizing Retrieval of Previewed Images
Apr 09, 2025Image retrieval remains a challenging task due to the complex interaction between human visual perception, memory, and computational processes. Current image search engines often struggle to efficiently retrieve images based on natural language descriptions, as they rely on time-consuming preprocessing, tagging, and machine learning pipelines. This paper introduces the Human-Oriented Retrieval Search Engine for Images (HORSE), a novel approach that leverages neuro-symbolic indexing to improve image retrieval by focusing on human-oriented indexing. By integrating cognitive science insights with advanced computational techniques, HORSE enhances the retrieval process, making it more aligned with how humans perceive, store, and recall visual information. The neuro-symbolic framework combines the strengths of neural networks and symbolic reasoning, mitigating their individual limitations. The proposed system optimizes image retrieval, offering a more intuitive and efficient solution for users. We discuss the design and implementation of HORSE, highlight its potential applications in fields such as design error detection and knowledge management, and suggest future directions for research to further refine the system's metrics and capabilities.
Transforming Triple-Entry Accounting with Machine Learning: A Path to Enhanced Transparency Through Analytics
Nov 19, 2024Triple Entry (TE) is an accounting method that utilizes three accounts or 'entries' to record each transaction, rather than the conventional double-entry bookkeeping system. Existing studies have found that TE accounting, with its additional layer of verification and disclosure of inter-organizational relationships, could help improve transparency in complex financial and supply chain transactions such as blockchain. Machine learning (ML) presents a promising avenue to augment the transparency advantages of TE accounting. By automating some of the data collection and analysis needed for TE bookkeeping, ML techniques have the potential to make this more transparent accounting method scalable for large organizations with complex international supply chains, further enhancing the visibility and trustworthiness of financial reporting. By leveraging ML algorithms, anomalies within distributed ledger data can be swiftly identified, flagging potential instances of fraud or errors. Furthermore, by delving into transaction relationships over time, ML can untangle intricate webs of transactions, shedding light on obscured dealings and adding an investigative dimension. This paper aims to demonstrate the interaction between TE and ML and how they can leverage transparency levels.
The Role and Applications of Airport Digital Twin in Cyberattack Protection during the Generative AI Era
Aug 08, 2024In recent years, the threat facing airports from growing and increasingly sophisticated cyberattacks has become evident. Airports are considered a strategic national asset, so protecting them from attacks, specifically cyberattacks, is a crucial mission. One way to increase airports' security is by using Digital Twins (DTs). This paper shows and demonstrates how DTs can enhance the security mission. The integration of DTs with Generative AI (GenAI) algorithms can lead to synergy and new frontiers in fighting cyberattacks. The paper exemplifies ways to model cyberattack scenarios using simulations and generate synthetic data for testing defenses. It also discusses how DTs can be used as a crucial tool for vulnerability assessment by identifying weaknesses, prioritizing, and accelerating remediations in case of cyberattacks. Moreover, the paper demonstrates approaches for anomaly detection and threat hunting using Machine Learning (ML) and GenAI algorithms. Additionally, the paper provides impact prediction and recovery coordination methods that can be used by DT operators and stakeholders. It also introduces ways to harness the human factor by integrating training and simulation algorithms with Explainable AI (XAI) into the DT platforms. Lastly, the paper offers future applications and technologies that can be utilized in DT environments.
Quantum Algorithms: A New Frontier in Financial Crime Prevention
Mar 27, 2024Financial crimes fast proliferation and sophistication require novel approaches that provide robust and effective solutions. This paper explores the potential of quantum algorithms in combating financial crimes. It highlights the advantages of quantum computing by examining traditional and Machine Learning (ML) techniques alongside quantum approaches. The study showcases advanced methodologies such as Quantum Machine Learning (QML) and Quantum Artificial Intelligence (QAI) as powerful solutions for detecting and preventing financial crimes, including money laundering, financial crime detection, cryptocurrency attacks, and market manipulation. These quantum approaches leverage the inherent computational capabilities of quantum computers to overcome limitations faced by classical methods. Furthermore, the paper illustrates how quantum computing can support enhanced financial risk management analysis. Financial institutions can improve their ability to identify and mitigate risks, leading to more robust risk management strategies by exploiting the quantum advantage. This research underscores the transformative impact of quantum algorithms on financial risk management. By embracing quantum technologies, organisations can enhance their capabilities to combat evolving threats and ensure the integrity and stability of financial systems.
Causality from Bottom to Top: A Survey
Mar 17, 2024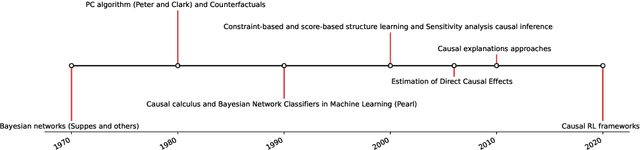



Causality has become a fundamental approach for explaining the relationships between events, phenomena, and outcomes in various fields of study. It has invaded various fields and applications, such as medicine, healthcare, economics, finance, fraud detection, cybersecurity, education, public policy, recommender systems, anomaly detection, robotics, control, sociology, marketing, and advertising. In this paper, we survey its development over the past five decades, shedding light on the differences between causality and other approaches, as well as the preconditions for using it. Furthermore, the paper illustrates how causality interacts with new approaches such as Artificial Intelligence (AI), Generative AI (GAI), Machine and Deep Learning, Reinforcement Learning (RL), and Fuzzy Logic. We study the impact of causality on various fields, its contribution, and its interaction with state-of-the-art approaches. Additionally, the paper exemplifies the trustworthiness and explainability of causality models. We offer several ways to evaluate causality models and discuss future directions.
Generating Effective Ensembles for Sentiment Analysis
Feb 26, 2024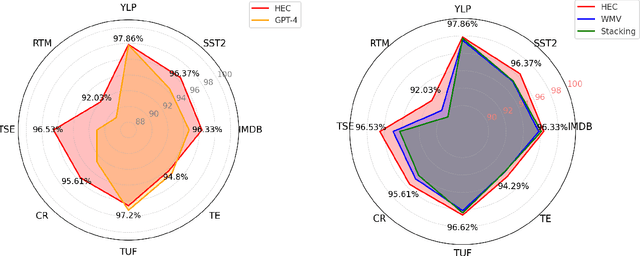
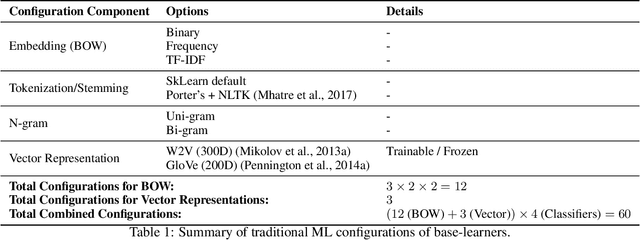

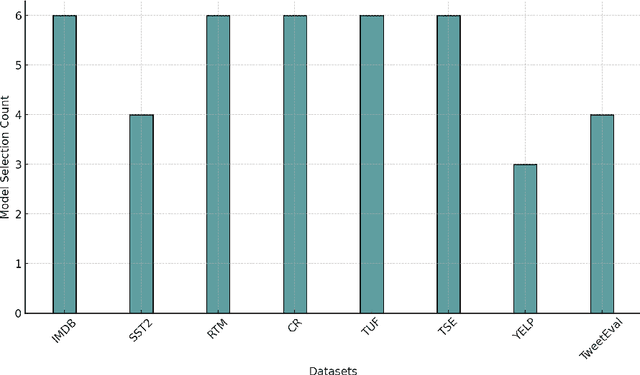
In recent years, transformer models have revolutionized Natural Language Processing (NLP), achieving exceptional results across various tasks, including Sentiment Analysis (SA). As such, current state-of-the-art approaches for SA predominantly rely on transformer models alone, achieving impressive accuracy levels on benchmark datasets. In this paper, we show that the key for further improving the accuracy of such ensembles for SA is to include not only transformers, but also traditional NLP models, despite the inferiority of the latter compared to transformer models. However, as we empirically show, this necessitates a change in how the ensemble is constructed, specifically relying on the Hierarchical Ensemble Construction (HEC) algorithm we present. Our empirical studies across eight canonical SA datasets reveal that ensembles incorporating a mix of model types, structured via HEC, significantly outperform traditional ensembles. Finally, we provide a comparative analysis of the performance of the HEC and GPT-4, demonstrating that while GPT-4 closely approaches state-of-the-art SA methods, it remains outperformed by our proposed ensemble strategy.
Survey of Learning Approaches for Robotic In-Hand Manipulation
Jan 15, 2024Human dexterity is an invaluable capability for precise manipulation of objects in complex tasks. The capability of robots to similarly grasp and perform in-hand manipulation of objects is critical for their use in the ever changing human environment, and for their ability to replace manpower. In recent decades, significant effort has been put in order to enable in-hand manipulation capabilities to robotic systems. Initial robotic manipulators followed carefully programmed paths, while later attempts provided a solution based on analytical modeling of motion and contact. However, these have failed to provide practical solutions due to inability to cope with complex environments and uncertainties. Therefore, the effort has shifted to learning-based approaches where data is collected from the real world or through a simulation, during repeated attempts to complete various tasks. The vast majority of learning approaches focused on learning data-based models that describe the system to some extent or Reinforcement Learning (RL). RL, in particular, has seen growing interest due to the remarkable ability to generate solutions to problems with minimal human guidance. In this survey paper, we track the developments of learning approaches for in-hand manipulations and, explore the challenges and opportunities. This survey is designed both as an introduction for novices in the field with a glossary of terms as well as a guide of novel advances for advanced practitioners.
SubStrat: A Subset-Based Strategy for Faster AutoML
Jun 07, 2022



Automated machine learning (AutoML) frameworks have become important tools in the data scientists' arsenal, as they dramatically reduce the manual work devoted to the construction of ML pipelines. Such frameworks intelligently search among millions of possible ML pipelines - typically containing feature engineering, model selection and hyper parameters tuning steps - and finally output an optimal pipeline in terms of predictive accuracy. However, when the dataset is large, each individual configuration takes longer to execute, therefore the overall AutoML running times become increasingly high. To this end, we present SubStrat, an AutoML optimization strategy that tackles the data size, rather than configuration space. It wraps existing AutoML tools, and instead of executing them directly on the entire dataset, SubStrat uses a genetic-based algorithm to find a small yet representative data subset which preserves a particular characteristic of the full data. It then employs the AutoML tool on the small subset, and finally, it refines the resulted pipeline by executing a restricted, much shorter, AutoML process on the large dataset. Our experimental results, performed on two popular AutoML frameworks, Auto-Sklearn and TPOT, show that SubStrat reduces their running times by 79% (on average), with less than 2% average loss in the accuracy of the resulted ML pipeline.