 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Effective Ensembles for Sentiment Analysis
Feb 26, 2024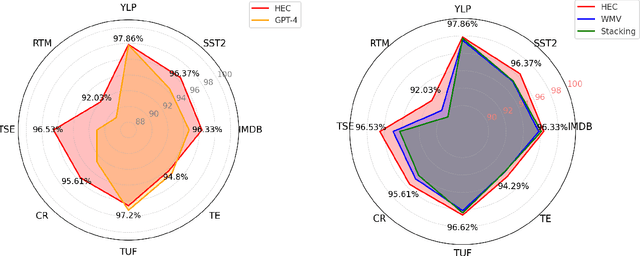
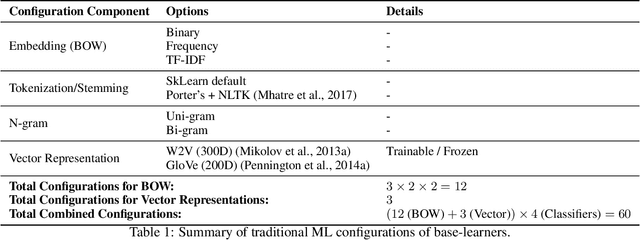

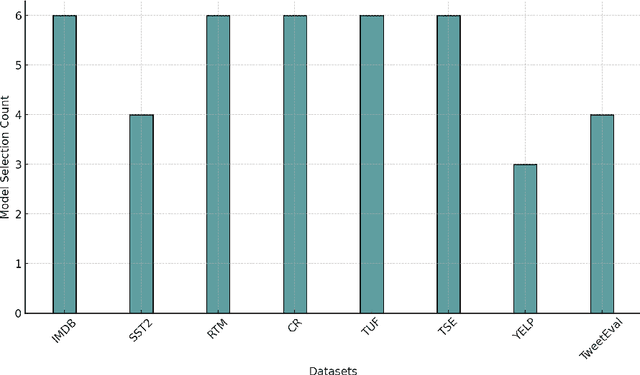
In recent years, transformer models have revolutionized Natural Language Processing (NLP), achieving exceptional results across various tasks, including Sentiment Analysis (SA). As such, current state-of-the-art approaches for SA predominantly rely on transformer models alone, achieving impressive accuracy levels on benchmark datasets. In this paper, we show that the key for further improving the accuracy of such ensembles for SA is to include not only transformers, but also traditional NLP models, despite the inferiority of the latter compared to transformer models. However, as we empirically show, this necessitates a change in how the ensemble is constructed, specifically relying on the Hierarchical Ensemble Construction (HEC) algorithm we present. Our empirical studies across eight canonical SA datasets reveal that ensembles incorporating a mix of model types, structured via HEC, significantly outperform traditional ensembles. Finally, we provide a comparative analysis of the performance of the HEC and GPT-4, demonstrating that while GPT-4 closely approaches state-of-the-art SA methods, it remains outperformed by our proposed ensemble strategy.
Explainability in Human-Agent Systems
Apr 17, 2019
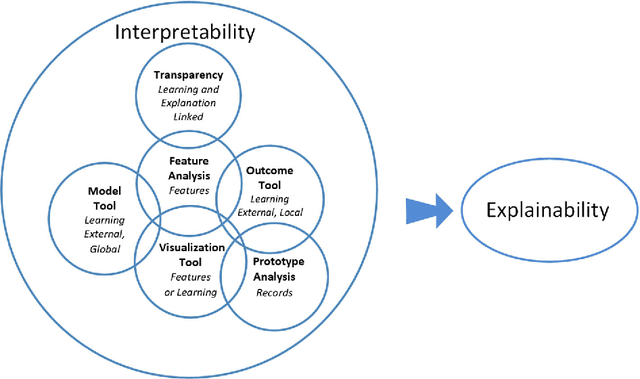
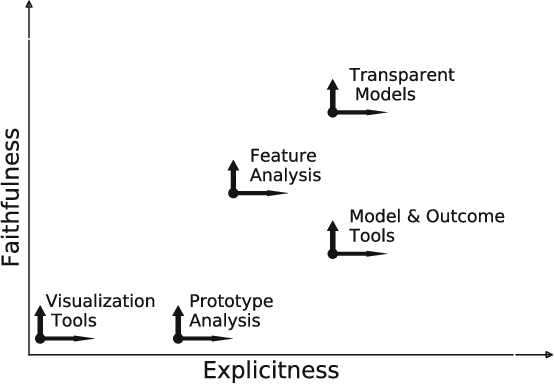
This paper presents a taxonomy of explainability in Human-Agent Systems. We consider fundamental questions about the Why, Who, What, When and How of explainability. First, we define explainability, and its relationship to the related terms of interpretability, transparency, explicitness, and faithfulness. These definitions allow us to answer why explainability is needed in the system, whom it is geared to and what explanations can be generated to meet this need. We then consider when the user should be presented with this information. Last, we consider how objective and subjective measures can be used to evaluate the entire system. This last question is the most encompassing as it will need to evaluate all other issues regarding explainability.
Using Discretization for Extending the Set of Predictive Features
Feb 09, 2018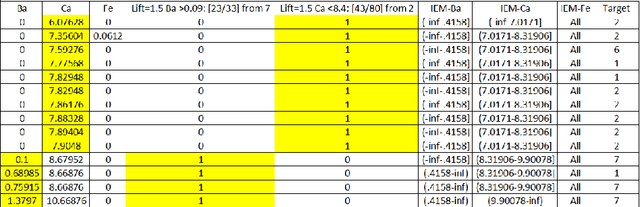
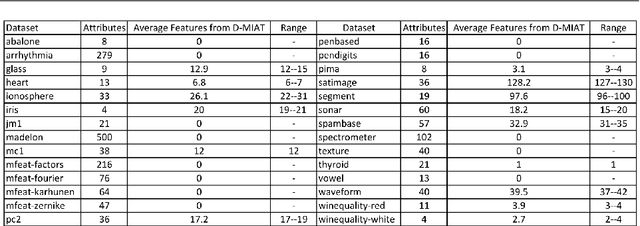

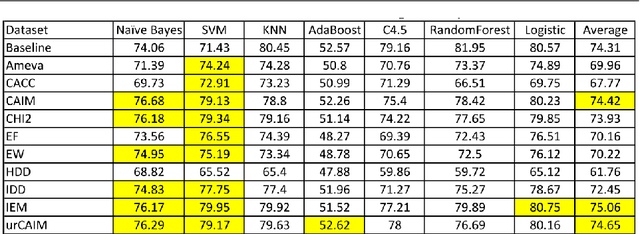
To date, attribute discretization is typically performed by replacing the original set of continuous features with a transposed set of discrete ones. This paper provides support for a new idea that discretized features should often be used in addition to existing features and as such, datasets should be extended, and not replaced, by discretization. We also claim that discretization algorithms should be developed with the explicit purpose of enriching a non-discretized dataset with discretized values. We present such an algorithm, D-MIAT, a supervised algorithm that discretizes data based on Minority Interesting Attribute Thresholds. D-MIAT only generates new features when strong indications exist for one of the target values needing to be learned and thus is intended to be used in addition to the original data. We present extensive empirical results demonstrating the success of using D-MIAT on $ 28 $ benchmark datasets. We also demonstrate that $ 10 $ other discretization algorithms can also be used to generate features that yield improved performance when used in combination with the original non-discretized data. Our results show that the best predictive performance is attained using a combination of the original dataset with added features from a "standard" supervised discretization algorithm and D-MIAT.
* 14 pages
Using the Crowd to Generate Content for Scenario-Based Serious-Games
Feb 20, 2014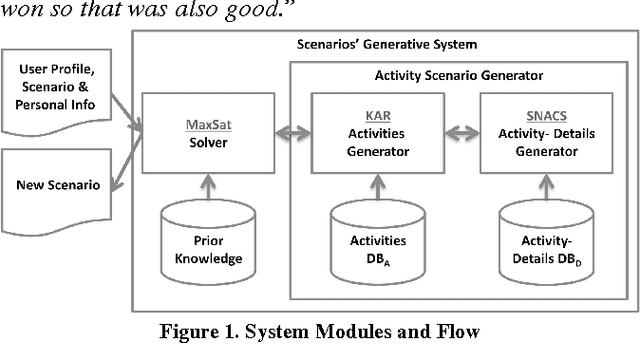


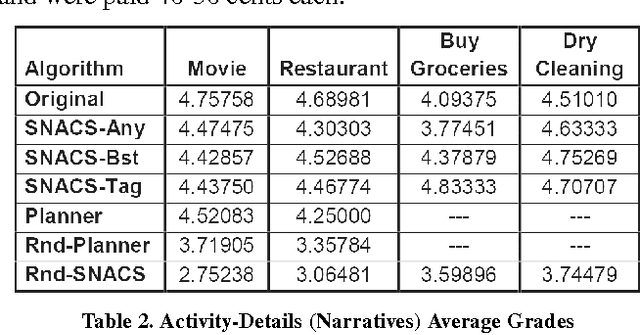
In the last decade, scenario-based serious-games have become a main tool for learning new skills and capabilities. An important factor in the development of such systems is the overhead in time, cost and human resources to manually create the content for these scenarios. We focus on how to create content for scenarios in medical, military, commerce and gaming applications where maintaining the integrity and coherence of the content is integral for the system's success. To do so, we present an automatic method for generating content about everyday activities through combining computer science techniques with the crowd. We use the crowd in three basic ways: to capture a database of scenarios of everyday activities, to generate a database of likely replacements for specific events within that scenario, and to evaluate the resulting scenarios. We found that the generated scenarios were rated as reliable and consistent by the crowd when compared to the scenarios that were originally captured. We also compared the generated scenarios to those created by traditional planning techniques. We found that both methods were equally effective in generated reliable and consistent scenarios, yet the main advantages of our approach is that the content we generate is more varied and much easier to create. We have begun integrating this approach within a scenario-based training application for novice investigators within the law enforcement departments to improve their questioning skills.