 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Discretization for Extending the Set of Predictive Features
Feb 09, 2018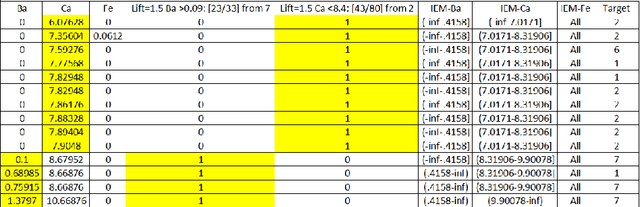
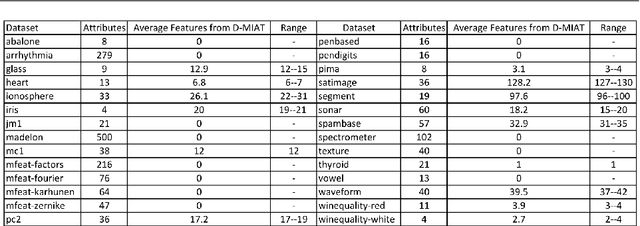

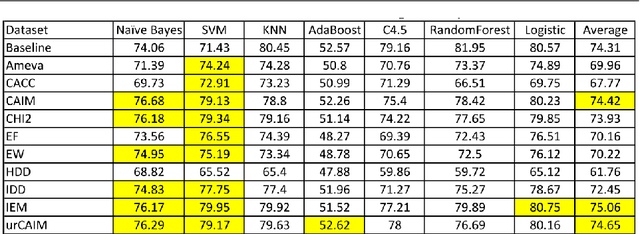
To date, attribute discretization is typically performed by replacing the original set of continuous features with a transposed set of discrete ones. This paper provides support for a new idea that discretized features should often be used in addition to existing features and as such, datasets should be extended, and not replaced, by discretization. We also claim that discretization algorithms should be developed with the explicit purpose of enriching a non-discretized dataset with discretized values. We present such an algorithm, D-MIAT, a supervised algorithm that discretizes data based on Minority Interesting Attribute Thresholds. D-MIAT only generates new features when strong indications exist for one of the target values needing to be learned and thus is intended to be used in addition to the original data. We present extensive empirical results demonstrating the success of using D-MIAT on $ 28 $ benchmark datasets. We also demonstrate that $ 10 $ other discretization algorithms can also be used to generate features that yield improved performance when used in combination with the original non-discretized data. Our results show that the best predictive performance is attained using a combination of the original dataset with added features from a "standard" supervised discretization algorithm and D-MIAT.
* 14 pages