 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Recognition in Vital Signs Using Spectrograms
Sep 02, 2021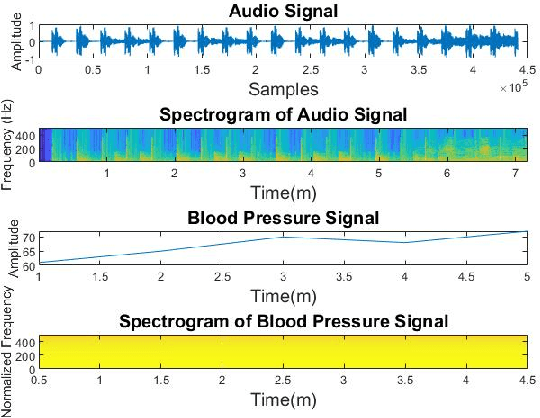
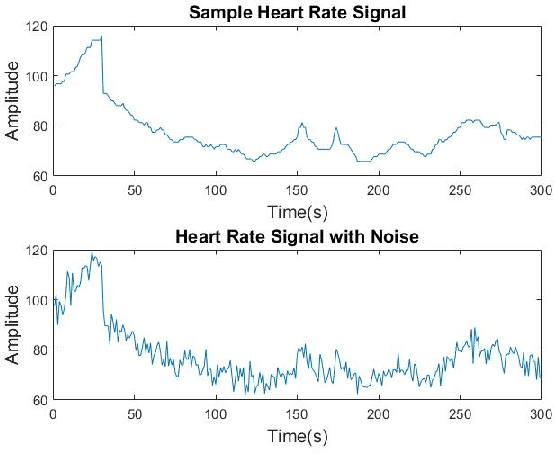
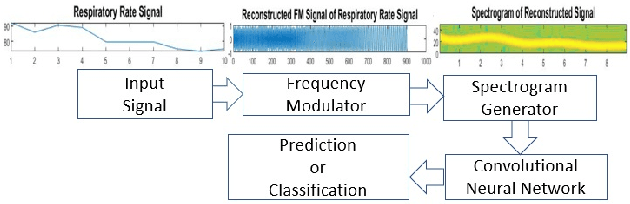
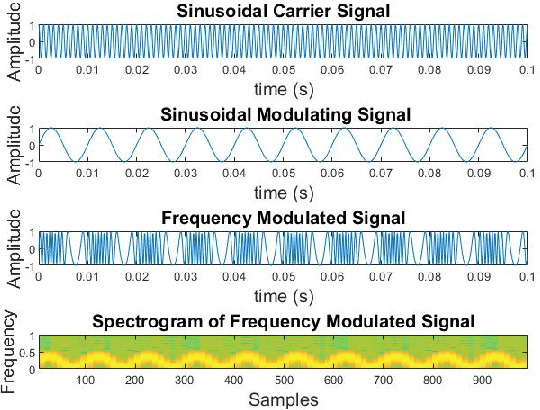
Spectrograms visualize the frequency components of a given signal which may be an audio signal or even a time-series signal. Audio signals have higher sampling rate and high variability of frequency with time. Spectrograms can capture such variations well. But, vital signs which are time-series signals have less sampling frequency and low-frequency variability due to which, spectrograms fail to express variations and patterns. In this paper, we propose a novel solution to introduce frequency variability using frequency modulation on vital signs. Then we apply spectrograms on frequency modulated signals to capture the patterns. The proposed approach has been evaluated on 4 different medical datasets across both prediction and classification tasks. Significant results are found showing the efficacy of the approach for vital sign signals. The results from the proposed approach are promising with an accuracy of 91.55% and 91.67% in prediction and classification tasks respectively.
3DPIFCM Novel Algorithm for Segmentation of Noisy Brain MRI Images
Feb 10, 2020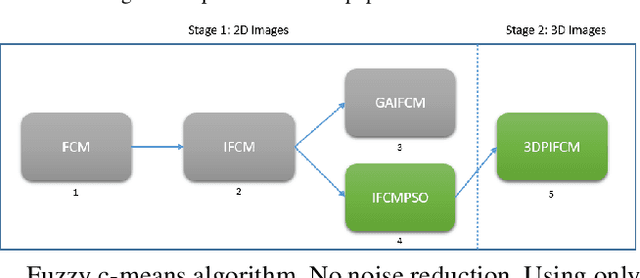
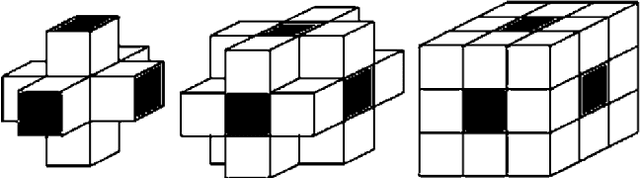
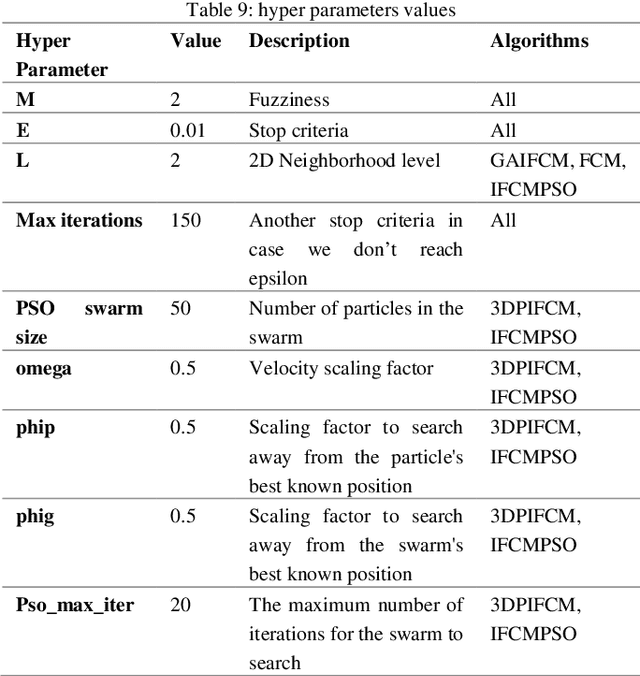
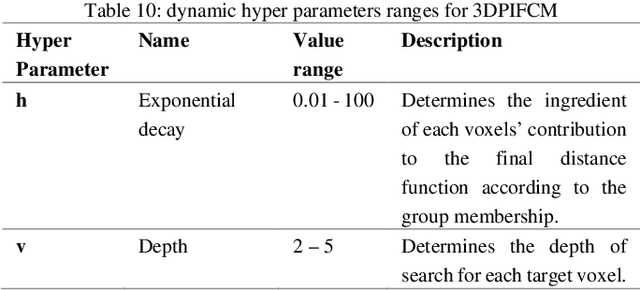
We present a novel algorithm named 3DPIFCM, for automatic segmentation of noisy MRI Brain images. The algorithm is an extension of a well-known IFCM (Improved Fuzzy C-Means) algorithm. It performs fuzzy segmentation and introduces a fitness function that is affected by proximity of the voxels and by the color intensity in 3D images. The 3DPIFCM algorithm uses PSO (Particle Swarm Optimization) in order to optimize the fitness function. In addition, the 3DPIFCM uses 3D features of near voxels to better adjust the noisy artifacts. In our experiments, we evaluate 3DPIFCM on T1 Brainweb dataset with noise levels ranging from 1% to 20% and on a synthetic dataset with ground truth both in 3D. The analysis of the segmentation results shows a significant improvement in the segmentation quality of up to 28% compared to two generic variants in noisy images and up to 60% when compared to the original FCM (Fuzzy C-Means).
Parallel 3DPIFCM Algorithm for Noisy Brain MRI Images
Feb 05, 2020
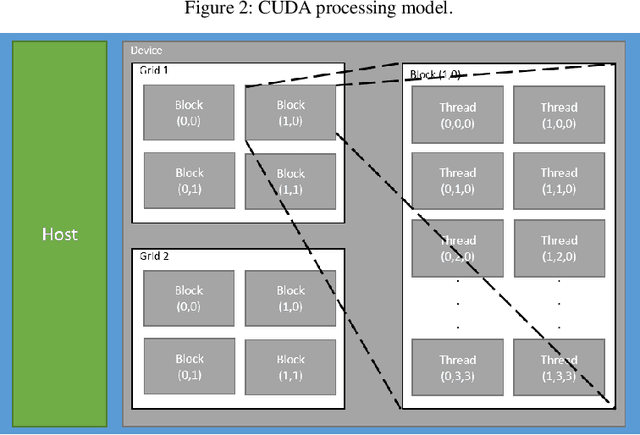
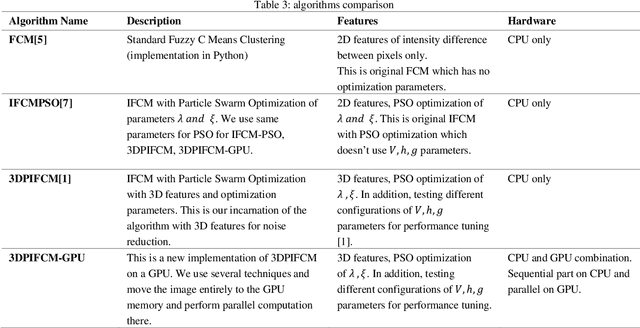
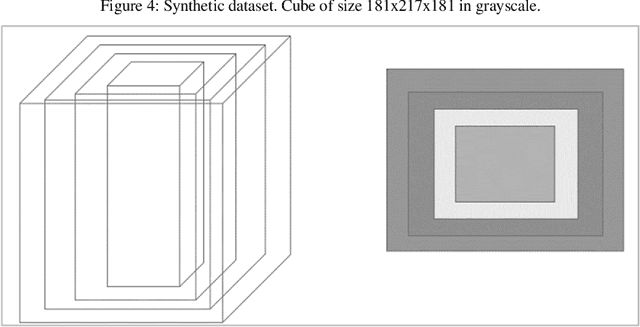
In this paper we implemented the algorithm we developed in [1] called 3DPIFCM in a parallel environment by using CUDA on a GPU. In our previous work we introduced 3DPIFCM which performs segmentation of images in noisy conditions and uses particle swarm optimization for finding the optimal algorithm parameters to account for noise. This algorithm achieved state of the art segmentation accuracy when compared to FCM (Fuzzy C-Means), IFCMPSO (Improved Fuzzy C-Means with Particle Swarm Optimization), GAIFCM (Genetic Algorithm Improved Fuzzy C-Means) on noisy MRI images of an adult Brain. When using a genetic algorithm or PSO (Particle Swarm Optimization) on a single machine for optimization we witnessed long execution times for practical clinical usage. Therefore, in the current paper our goal was to speed up the execution of 3DPIFCM by taking out parts of the algorithm and executing them as kernels on a GPU. The algorithm was implemented using the CUDA [13] framework from NVIDIA and experiments where performed on a server containing 64GB RAM , 8 cores and a TITAN X GPU with 3072 SP cores and 12GB of GPU memory. Our results show that the parallel version of the algorithm performs up to 27x faster than the original sequential version and 68x faster than GAIFCM algorithm. We show that the speedup of the parallel version increases as we increase the size of the image due to better utilization of cores in the GPU. Also, we show a speedup of up to 5x in our Brainweb experiment compared to other generic variants such as IFCMPSO and GAIFCM.
Using Discretization for Extending the Set of Predictive Features
Feb 09, 2018
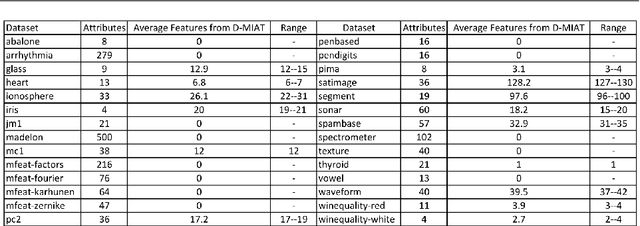

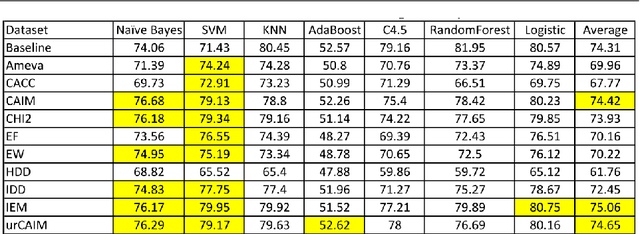
To date, attribute discretization is typically performed by replacing the original set of continuous features with a transposed set of discrete ones. This paper provides support for a new idea that discretized features should often be used in addition to existing features and as such, datasets should be extended, and not replaced, by discretization. We also claim that discretization algorithms should be developed with the explicit purpose of enriching a non-discretized dataset with discretized values. We present such an algorithm, D-MIAT, a supervised algorithm that discretizes data based on Minority Interesting Attribute Thresholds. D-MIAT only generates new features when strong indications exist for one of the target values needing to be learned and thus is intended to be used in addition to the original data. We present extensive empirical results demonstrating the success of using D-MIAT on $ 28 $ benchmark datasets. We also demonstrate that $ 10 $ other discretization algorithms can also be used to generate features that yield improved performance when used in combination with the original non-discretized data. Our results show that the best predictive performance is attained using a combination of the original dataset with added features from a "standard" supervised discretization algorithm and D-MIAT.
* 14 pages
A Syntactic Approach to Domain-Specific Automatic Question Generation
Dec 28, 2017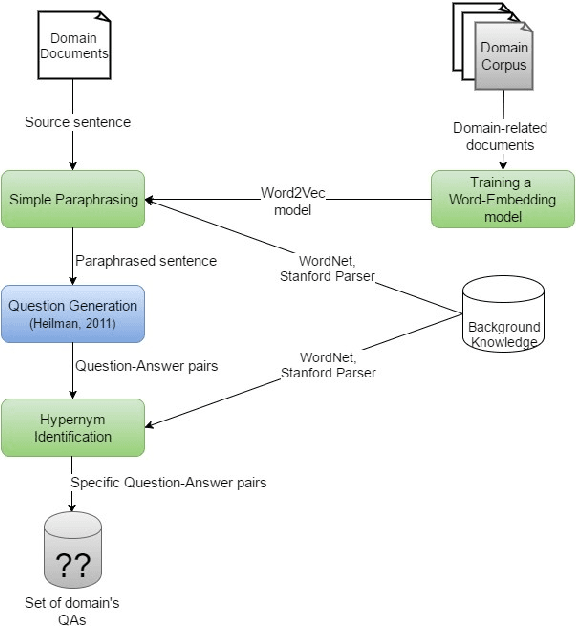
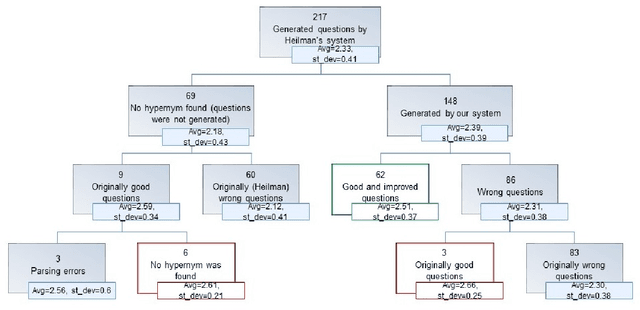
Factoid questions are questions that require short fact-based answers. Automatic generation (AQG) of factoid questions from a given text can contribute to educational activities, interactive question answering systems, search engines, and other applications. The goal of our research is to generate factoid source-question-answer triplets based on a specific domain. We propose a four-component pipeline, which obtains as input a training corpus of domain-specific documents, along with a set of declarative sentences from the same domain, and generates as output a set of factoid questions that refer to the source sentences but are slightly different from them, so that a question-answering system or a person can be asked a question that requires a deeper understanding and knowledge than a simple word-matching. Contrary to existing domain-specific AQG systems that utilize the template-based approach to question generation, we propose to transform each source sentence into a set of questions by applying a series of domain-independent rules (a syntactic-based approach). Our pipeline was evaluated in the domain of cyber security using a series of experiments on each component of the pipeline separately and on the end-to-end system. The proposed approach generated a higher percentage of acceptable questions than a prior state-of-the-art AQG system.