 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of VLM for Soccer Video Understanding
May 20, 2025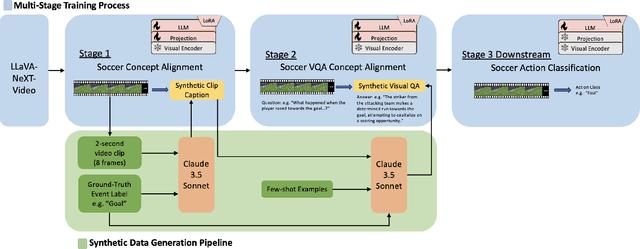

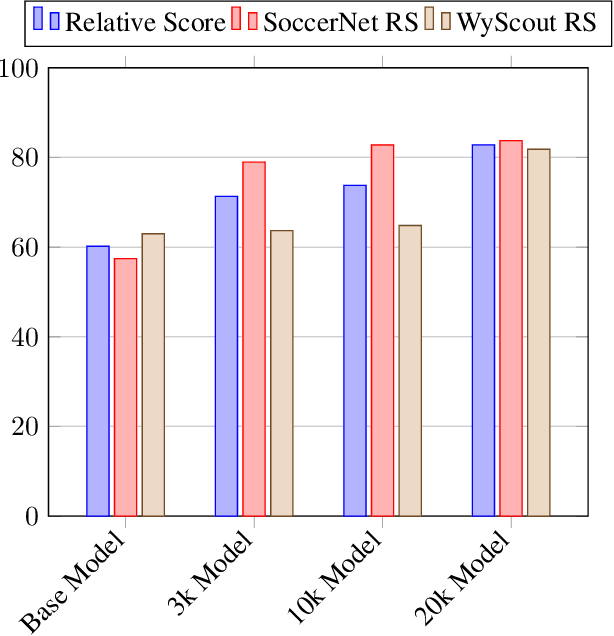

Vision Language Models (VLMs) have demonstrated strong performance in multi-modal tasks by effectively aligning visual and textual representations. However, most video understanding VLM research has been domain-agnostic, leaving the understanding of their transfer learning capability to specialized domains under-explored. In this work, we address this by exploring the adaptability of open-source VLMs to specific domains, and focusing on soccer as an initial case study. Our approach uses large-scale soccer datasets and LLM to create instruction-following data, and use them to iteratively fine-tune the general-domain VLM in a curriculum learning fashion (first teaching the model key soccer concepts to then question answering tasks). The final adapted model, trained using a curated dataset of 20k video clips, exhibits significant improvement in soccer-specific tasks compared to the base model, with a 37.5% relative improvement for the visual question-answering task and an accuracy improvement from 11.8% to 63.5% for the downstream soccer action classification task.
Robust Neonatal Face Detection in Real-world Clinical Settings
Apr 01, 2022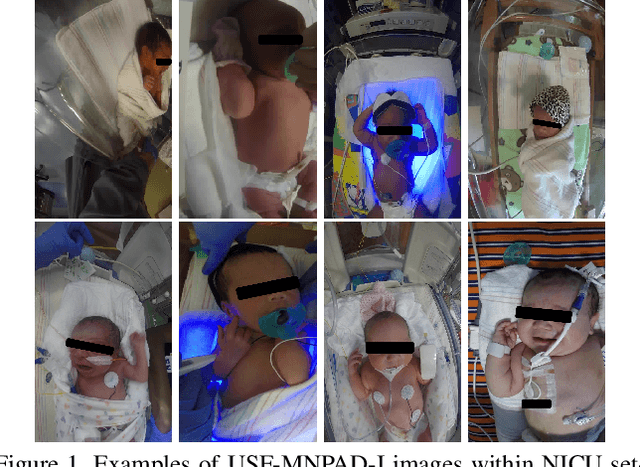

Current face detection algorithms are extremely generalized and can obtain decent accuracy when detecting the adult faces. These approaches are insufficient when handling outlier cases, for example when trying to detect the face of a neonate infant whose face composition and expressions are relatively different than that of the adult. It is furthermore difficult when applied to detect faces in a complicated setting such as the Neonate Intensive Care Unit. By training a state-of-the-art face detection model, You-Only-Look-Once, on a proprietary dataset containing labelled neonate faces in a clinical setting, this work achieves near real time neonate face detection. Our preliminary findings show an accuracy of 68.7%, compared to the off the shelf solution which detected neonate faces with an accuracy of 7.37%. Although further experiments are needed to validate our model, our results are promising and prove the feasibility of detecting neonatal faces in challenging real-world settings. The robust and real-time detection of neonatal faces would benefit wide range of automated systems (e.g., pain recognition and surveillance) who currently suffer from the time and effort due to the necessity of manual annotations. To benefit the research community, we make our trained weights publicly available at github(https://github.com/ja05haus/trained_neonate_face).
Pattern Recognition in Vital Signs Using Spectrograms
Sep 02, 2021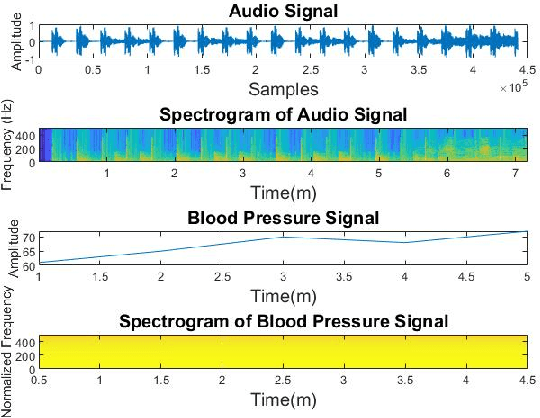
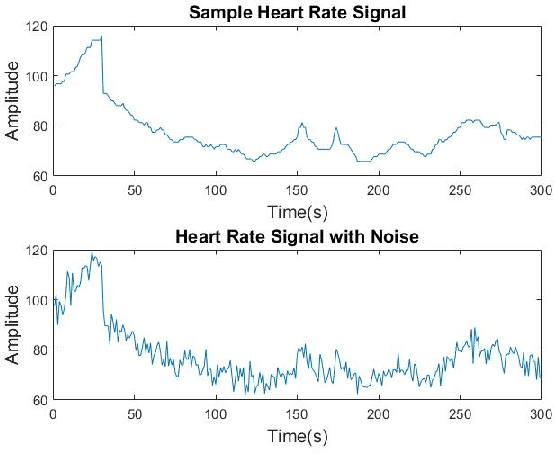
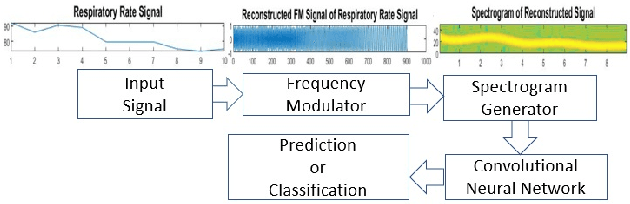
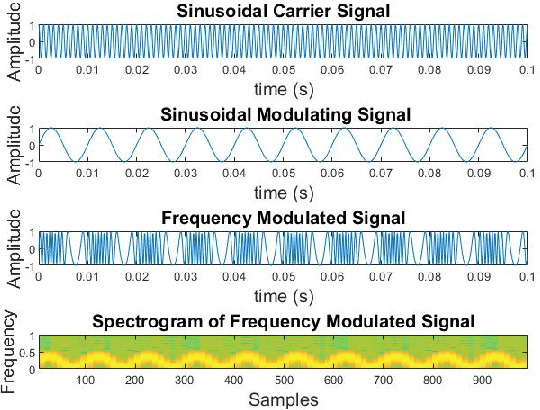
Spectrograms visualize the frequency components of a given signal which may be an audio signal or even a time-series signal. Audio signals have higher sampling rate and high variability of frequency with time. Spectrograms can capture such variations well. But, vital signs which are time-series signals have less sampling frequency and low-frequency variability due to which, spectrograms fail to express variations and patterns. In this paper, we propose a novel solution to introduce frequency variability using frequency modulation on vital signs. Then we apply spectrograms on frequency modulated signals to capture the patterns. The proposed approach has been evaluated on 4 different medical datasets across both prediction and classification tasks. Significant results are found showing the efficacy of the approach for vital sign signals. The results from the proposed approach are promising with an accuracy of 91.55% and 91.67% in prediction and classification tasks respectively.
Multimodal Spatio-Temporal Deep Learning Approach for Neonatal Postoperative Pain Assessment
Dec 03, 2020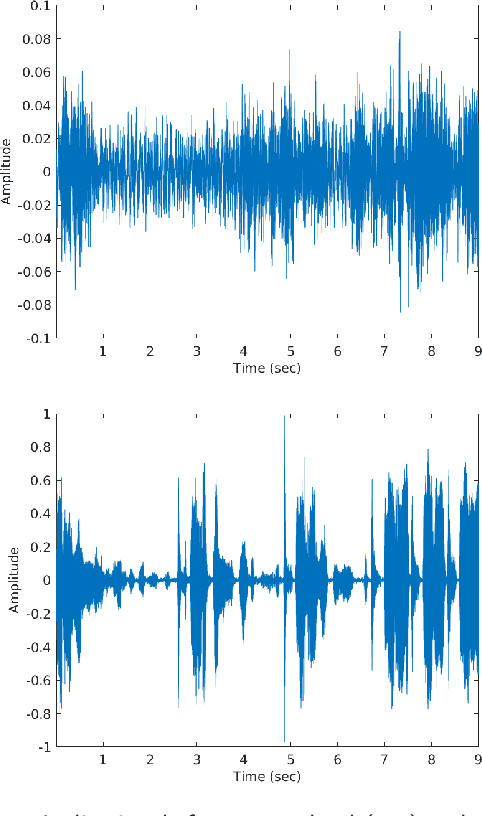
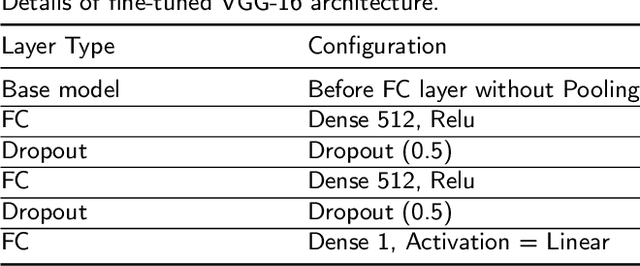
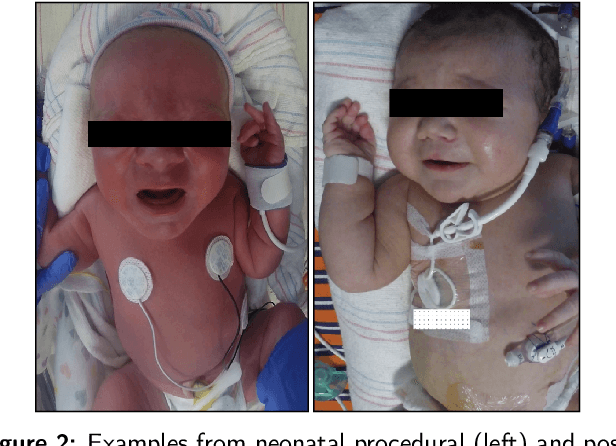
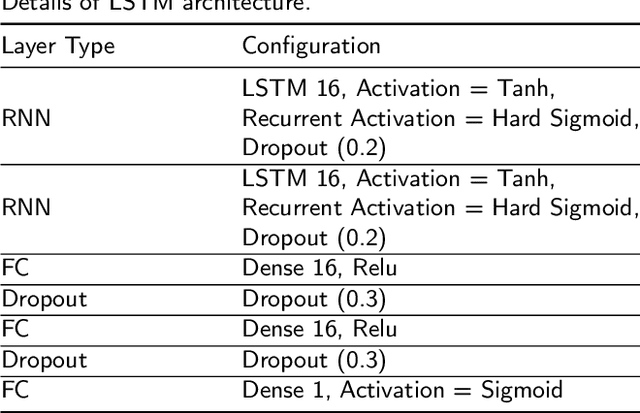
The current practice for assessing neonatal postoperative pain relies on bedside caregivers. This practice is subjective, inconsistent, slow, and discontinuous. To develop a reliable medical interpretation, several automated approaches have been proposed to enhance the current practice. These approaches are unimodal and focus mainly on assessing neonatal procedural (acute) pain. As pain is a multimodal emotion that is often expressed through multiple modalities, the multimodal assessment of pain is necessary especially in case of postoperative (acute prolonged) pain. Additionally, spatio-temporal analysis is more stable over time and has been proven to be highly effective at minimizing misclassification errors. In this paper, we present a novel multimodal spatio-temporal approach that integrates visual and vocal signals and uses them for assessing neonatal postoperative pain. We conduct comprehensive experiments to investigate the effectiveness of the proposed approach. We compare the performance of the multimodal and unimodal postoperative pain assessment, and measure the impact of temporal information integration. The experimental results, on a real-world dataset, show that the proposed multimodal spatio-temporal approach achieves the highest AUC (0.87) and accuracy (79%), which are on average 6.67% and 6.33% higher than unimodal approaches. The results also show that the integration of temporal information markedly improves the performance as compared to the non-temporal approach as it captures changes in the pain dynamic. These results demonstrate that the proposed approach can be used as a viable alternative to manual assessment, which would tread a path toward fully automated pain monitoring in clinical settings, point-of-care testing, and homes.
First Investigation Into the Use of Deep Learning for Continuous Assessment of Neonatal Postoperative Pain
Mar 24, 2020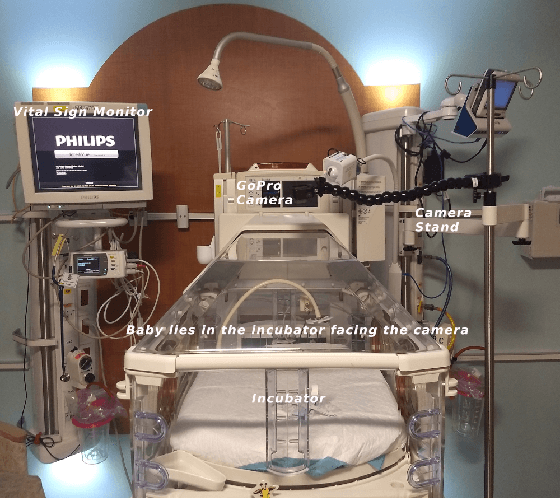
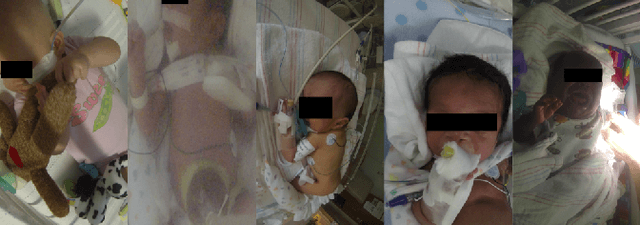
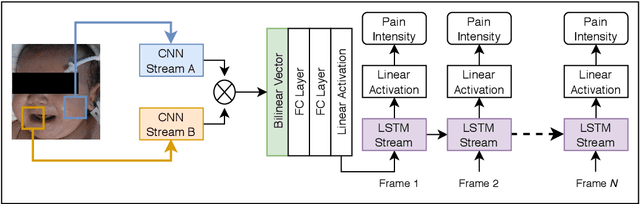
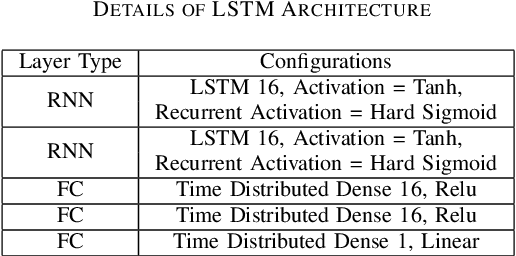
This paper presents the first investigation into the use of fully automated deep learning framework for assessing neonatal postoperative pain. It specifically investigates the use of Bilinear Convolutional Neural Network (B-CNN) to extract facial features during different levels of postoperative pain followed by modeling the temporal pattern using Recurrent Neural Network (RNN). Although acute and postoperative pain have some common characteristics (e.g., visual action units), postoperative pain has a different dynamic, and it evolves in a unique pattern over time. Our experimental results indicate a clear difference between the pattern of acute and postoperative pain. They also suggest the efficiency of using a combination of bilinear CNN with RNN model for the continuous assessment of postoperative pain intensity.
Harnessing the Power of Deep Learning Methods in Healthcare: Neonatal Pain Assessment from Crying Sound
Sep 05, 2019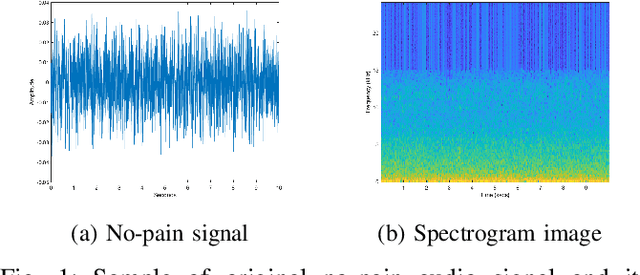
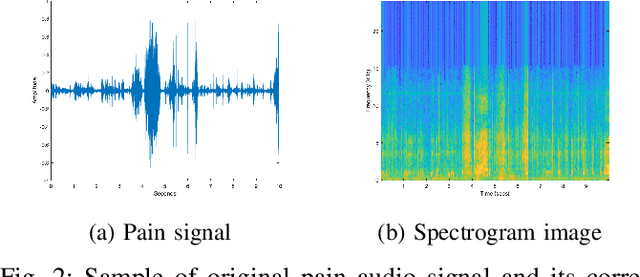
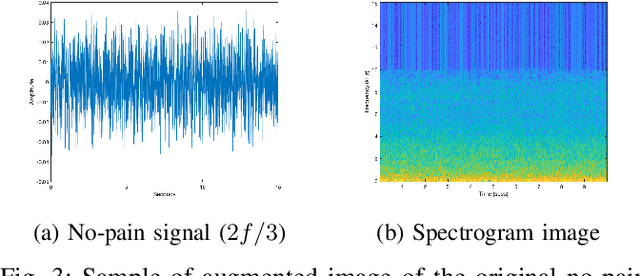
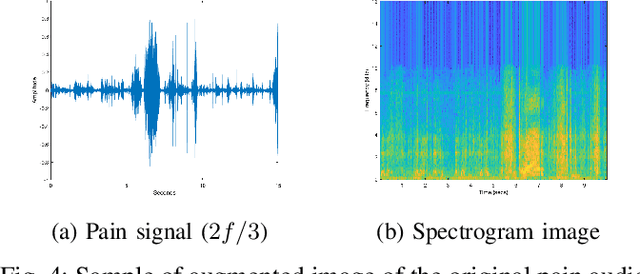
Neonatal pain assessment in clinical environments is challenging as it is discontinuous and biased. Facial/body occlusion can occur in such settings due to clinical condition, developmental delays, prone position, or other external factors. In such cases, crying sound can be used to effectively assess neonatal pain. In this paper, we investigate the use of a novel CNN architecture (N-CNN) along with other CNN architectures (VGG16 and ResNet50) for assessing pain from crying sounds of neonates. The experimental results demonstrate that using our novel N-CNN for assessing pain from the sounds of neonates has a strong clinical potential and provides a viable alternative to the current assessment practice.
Multi-Channel Neural Network for Assessing Neonatal Pain from Videos
Aug 25, 2019
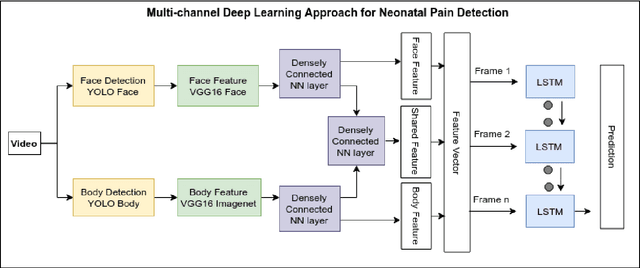
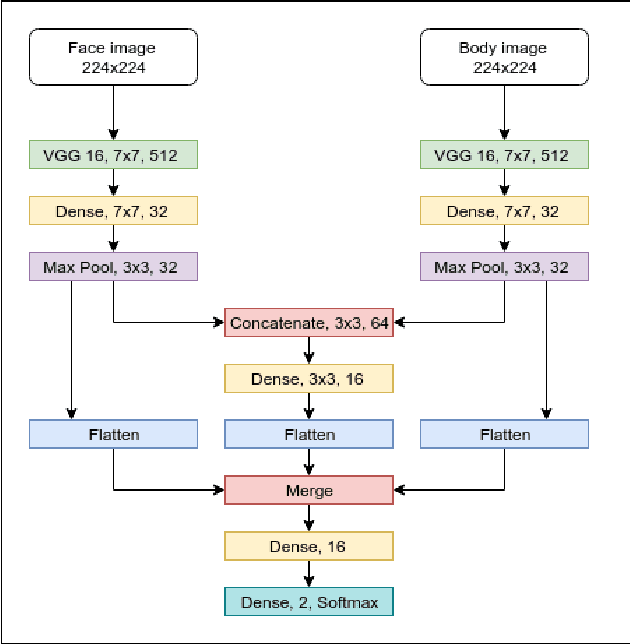
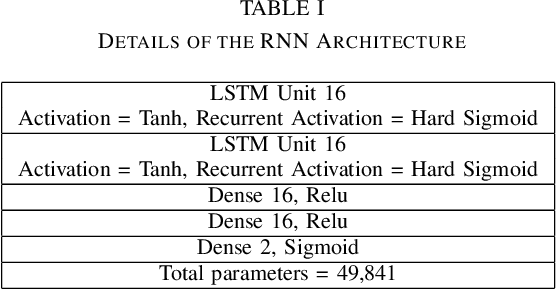
Neonates do not have the ability to either articulate pain or communicate it non-verbally by pointing. The current clinical standard for assessing neonatal pain is intermittent and highly subjective. This discontinuity and subjectivity can lead to inconsistent assessment, and therefore, inadequate treatment. In this paper, we propose a multi-channel deep learning framework for assessing neonatal pain from videos. The proposed framework integrates information from two pain indicators or channels, namely facial expression and body movement, using convolutional neural network (CNN). It also integrates temporal information using a recurrent neural network (LSTM). The experimental results prove the efficiency and superiority of the proposed temporal and multi-channel framework as compared to existing similar methods.
Contrast Enhancement of Medical X-Ray Image Using Morphological Operators with Optimal Structuring Element
May 21, 2019

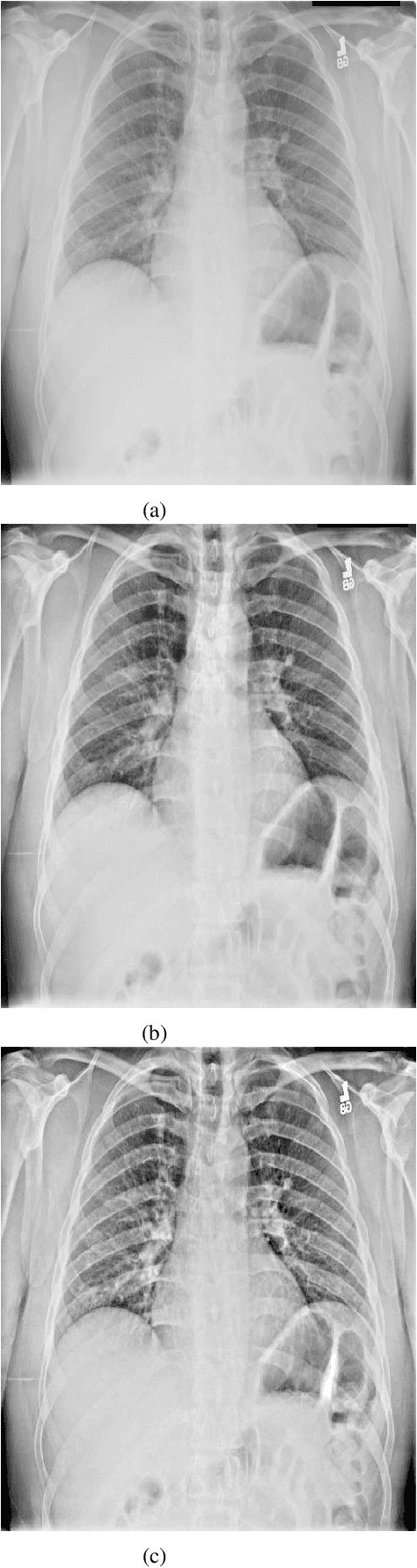
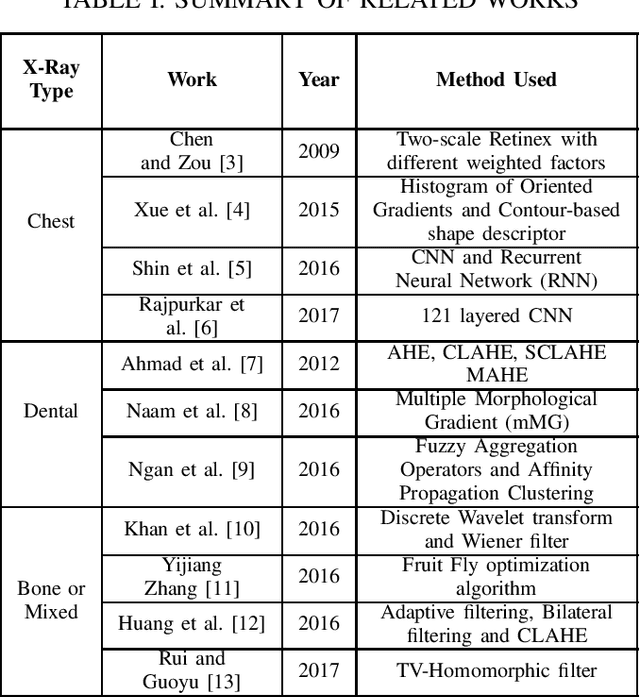
To guide surgical and medical treatment X-ray images have been used by physicians in every modern healthcare organization and hospitals. Doctor's evaluation process and disease identification in the area of skeletal system can be performed in a faster and efficient way with the help of X-ray imaging technique as they can depict bone structure painlessly. This paper presents an efficient contrast enhancement technique using morphological operators which will help to visualize important bone segments and soft tissues more clearly. Top-hat and Bottom-hat transform are utilized to enhance the image where gradient magnitude value is calculated for automatically selecting the structuring element (SE) size. Experimental evaluation on different x-ray imaging databases shows the effectiveness of our method which also produces comparatively better output against some existing image enhancement techniques.
Identifying Object States in Cooking-Related Images
Oct 30, 2018
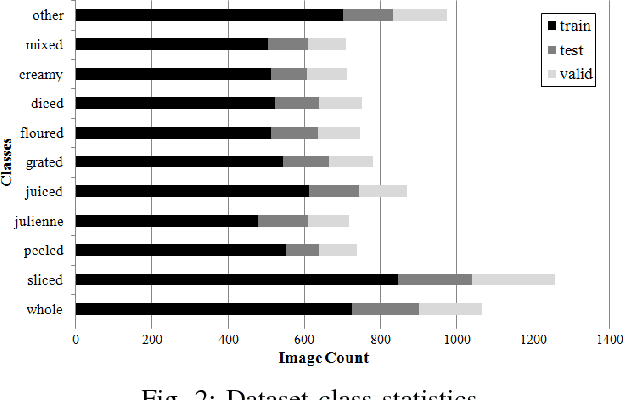

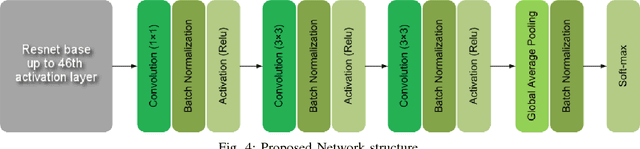
Understanding object states is as important as object recognition for robotic task planning and manipulation. To our knowledge, this paper explicitly introduces and addresses the state identification problem in cooking related images for the first time. In this paper, objects and ingredients in cooking videos are explored and the most frequent objects are analyzed. Eleven states from the most frequent cooking objects are examined and a dataset of images containing those objects and their states is created. As a solution to the state identification problem, a Resnet based deep model is proposed. The model is initialized with Imagenet weights and trained on the dataset of eleven classes. The trained state identification model is evaluated on a subset of the Imagenet dataset and state labels are provided using a combination of the model with manual checking. Moreover, an individual model is fine-tuned for each object in the dataset using the weights from the initially trained model and object-specific images, where significant improvement is demonstrated.
Cooking State Recognition From Images Using Inception Architecture
May 25, 2018



A kitchen robot properly needs to understand the cooking environment to continue any cooking activities. But object's state detection has not been researched well so far as like object detection. In this paper, we propose a deep learning approach to identify different cooking states from images for a kitchen robot. In our research, we investigate particularly the performance of Inception architecture and propose a modified architecture based on Inception model to classify different cooking states. The model is analyzed robustly in terms of different layers, and optimizers. Experimental results on a cooking datasets demonstrate that proposed model can be a potential solution to the cooking state recognition problem.