 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Human-in-the-Loop Framework for Efficient Prompt Selection in Microscopy Vision-Language Models
May 19, 2026Deep-learning pipelines for microscopy image classification often require expensive, labor- and time-intensive expert annotation to produce high-quality ground truth for training. Recent work has shown that prompt tuning of vision-language models (VLMs) can reduce manual annotation by constructing a small prompt set of expert-verified image-caption exemplars that is reused as few-shot context to classify all remaining images at inference time. To further reduce effort, the VLM can draft captions for candidate exemplars, which experts then verify and lightly edit instead of writing text de novo. However, two practical questions remain unaddressed: (1) which unlabeled images should be prioritized for verification, and (2) how many verified exemplars are needed to reach a performance target. In this work, we address these questions by formulating prompt-set construction as a target-driven active learning problem that prioritizes which images to annotate. We study three complementary selection criteria under strict low-resource constraints with small unlabeled pools. Experiments show that our methods reach the target performance with substantially fewer expert-verified images than random selection, achieving 100% test accuracy with as few as 20 annotated images on average. More broadly, our human-in-the-loop framework demonstrates a human-centered use of generative AI in biomedical image analysis, where experts remain actively involved in verifying and refining model output while significantly reducing annotation cost. Code and data will be publicly available.
Towards AI-Driven Human-Machine Co-Teaming for Adaptive and Agile Cyber Security Operation Centers
May 09, 2025Security Operations Centers (SOCs) face growing challenges in managing cybersecurity threats due to an overwhelming volume of alerts, a shortage of skilled analysts, and poorly integrated tools. Human-AI collaboration offers a promising path to augment the capabilities of SOC analysts while reducing their cognitive overload. To this end, we introduce an AI-driven human-machine co-teaming paradigm that leverages large language models (LLMs) to enhance threat intelligence, alert triage, and incident response workflows. We present a vision in which LLM-based AI agents learn from human analysts the tacit knowledge embedded in SOC operations, enabling the AI agents to improve their performance on SOC tasks through this co-teaming. We invite SOCs to collaborate with us to further develop this process and uncover replicable patterns where human-AI co-teaming yields measurable improvements in SOC productivity.
Active Prompt Tuning Enables Gpt-40 To Do Efficient Classification Of Microscopy Images
Nov 04, 2024Traditional deep learning-based methods for classifying cellular features in microscopy images require time- and labor-intensive processes for training models. Among the current limitations are major time commitments from domain experts for accurate ground truth preparation; and the need for a large amount of input image data. We previously proposed a solution that overcomes these challenges using OpenAI's GPT-4(V) model on a pilot dataset (Iba-1 immuno-stained tissue sections from 11 mouse brains). Results on the pilot dataset were equivalent in accuracy and with a substantial improvement in throughput efficiency compared to the baseline using a traditional Convolutional Neural Net (CNN)-based approach. The present study builds upon this framework using a second unique and substantially larger dataset of microscopy images. Our current approach uses a newer and faster model, GPT-4o, along with improved prompts. It was evaluated on a microscopy image dataset captured at low (10x) magnification from cresyl-violet-stained sections through the cerebellum of a total of 18 mouse brains (9 Lurcher mice, 9 wild-type controls). We used our approach to classify these images either as a control group or Lurcher mutant. Using 6 mice in the prompt set the results were correct classification for 11 out of the 12 mice (92%) with 96% higher efficiency, reduced image requirements, and lower demands on time and effort of domain experts compared to the baseline method (snapshot ensemble of CNN models). These results confirm that our approach is effective across multiple datasets from different brain regions and magnifications, with minimal overhead.
A Preliminary Study on Using Large Language Models in Software Pentesting
Jan 30, 2024Large language models (LLM) are perceived to offer promising potentials for automating security tasks, such as those found in security operation centers (SOCs). As a first step towards evaluating this perceived potential, we investigate the use of LLMs in software pentesting, where the main task is to automatically identify software security vulnerabilities in source code. We hypothesize that an LLM-based AI agent can be improved over time for a specific security task as human operators interact with it. Such improvement can be made, as a first step, by engineering prompts fed to the LLM based on the responses produced, to include relevant contexts and structures so that the model provides more accurate results. Such engineering efforts become sustainable if the prompts that are engineered to produce better results on current tasks, also produce better results on future unknown tasks. To examine this hypothesis, we utilize the OWASP Benchmark Project 1.2 which contains 2,740 hand-crafted source code test cases containing various types of vulnerabilities. We divide the test cases into training and testing data, where we engineer the prompts based on the training data (only), and evaluate the final system on the testing data. We compare the AI agent's performance on the testing data against the performance of the agent without the prompt engineering. We also compare the AI agent's results against those from SonarQube, a widely used static code analyzer for security testing. We built and tested multiple versions of the AI agent using different off-the-shelf LLMs -- Google's Gemini-pro, as well as OpenAI's GPT-3.5-Turbo and GPT-4-Turbo (with both chat completion and assistant APIs). The results show that using LLMs is a viable approach to build an AI agent for software pentesting that can improve through repeated use and prompt engineering.
Robust Neonatal Face Detection in Real-world Clinical Settings
Apr 01, 2022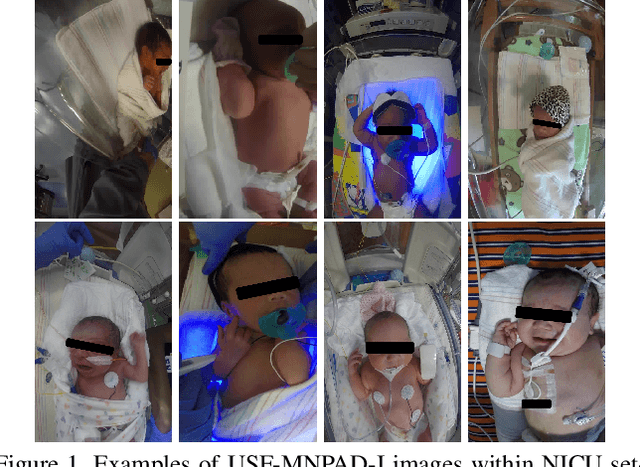

Current face detection algorithms are extremely generalized and can obtain decent accuracy when detecting the adult faces. These approaches are insufficient when handling outlier cases, for example when trying to detect the face of a neonate infant whose face composition and expressions are relatively different than that of the adult. It is furthermore difficult when applied to detect faces in a complicated setting such as the Neonate Intensive Care Unit. By training a state-of-the-art face detection model, You-Only-Look-Once, on a proprietary dataset containing labelled neonate faces in a clinical setting, this work achieves near real time neonate face detection. Our preliminary findings show an accuracy of 68.7%, compared to the off the shelf solution which detected neonate faces with an accuracy of 7.37%. Although further experiments are needed to validate our model, our results are promising and prove the feasibility of detecting neonatal faces in challenging real-world settings. The robust and real-time detection of neonatal faces would benefit wide range of automated systems (e.g., pain recognition and surveillance) who currently suffer from the time and effort due to the necessity of manual annotations. To benefit the research community, we make our trained weights publicly available at github(https://github.com/ja05haus/trained_neonate_face).
Pattern Recognition in Vital Signs Using Spectrograms
Sep 02, 2021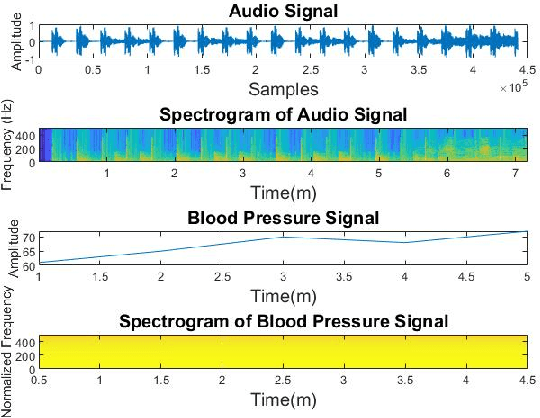
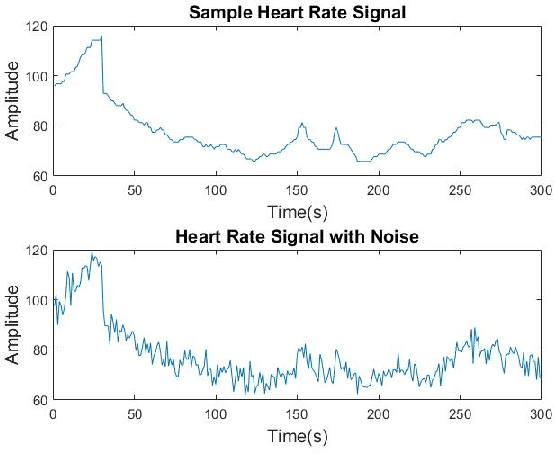
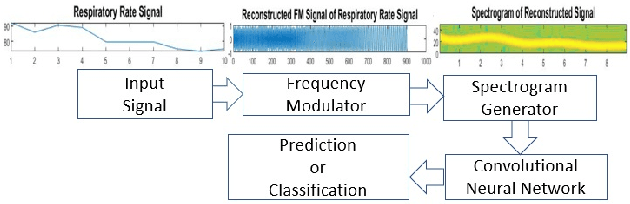
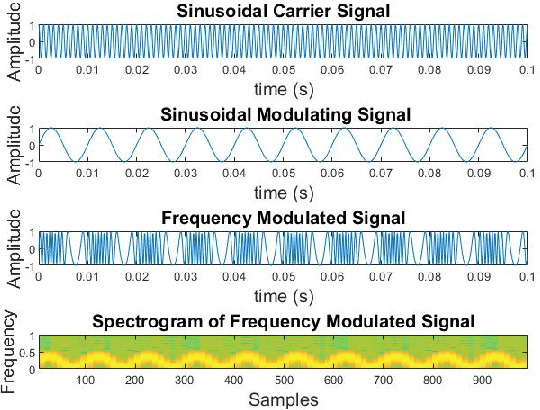
Spectrograms visualize the frequency components of a given signal which may be an audio signal or even a time-series signal. Audio signals have higher sampling rate and high variability of frequency with time. Spectrograms can capture such variations well. But, vital signs which are time-series signals have less sampling frequency and low-frequency variability due to which, spectrograms fail to express variations and patterns. In this paper, we propose a novel solution to introduce frequency variability using frequency modulation on vital signs. Then we apply spectrograms on frequency modulated signals to capture the patterns. The proposed approach has been evaluated on 4 different medical datasets across both prediction and classification tasks. Significant results are found showing the efficacy of the approach for vital sign signals. The results from the proposed approach are promising with an accuracy of 91.55% and 91.67% in prediction and classification tasks respectively.
Multimodal Spatio-Temporal Deep Learning Approach for Neonatal Postoperative Pain Assessment
Dec 03, 2020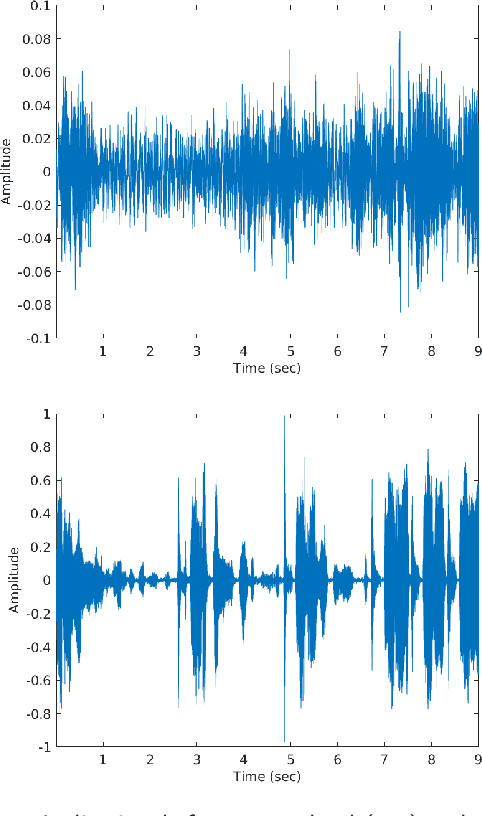
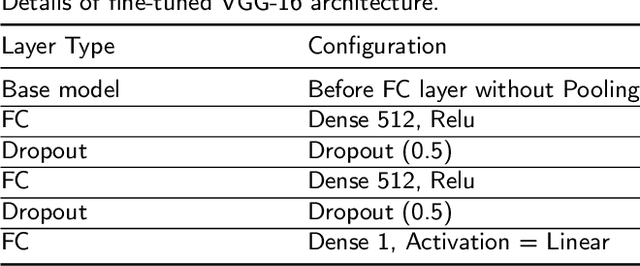
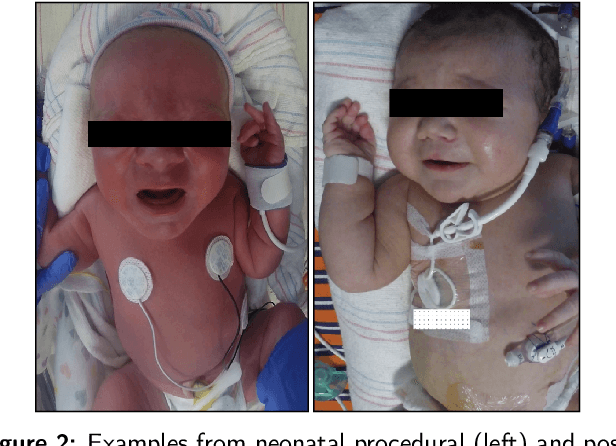
The current practice for assessing neonatal postoperative pain relies on bedside caregivers. This practice is subjective, inconsistent, slow, and discontinuous. To develop a reliable medical interpretation, several automated approaches have been proposed to enhance the current practice. These approaches are unimodal and focus mainly on assessing neonatal procedural (acute) pain. As pain is a multimodal emotion that is often expressed through multiple modalities, the multimodal assessment of pain is necessary especially in case of postoperative (acute prolonged) pain. Additionally, spatio-temporal analysis is more stable over time and has been proven to be highly effective at minimizing misclassification errors. In this paper, we present a novel multimodal spatio-temporal approach that integrates visual and vocal signals and uses them for assessing neonatal postoperative pain. We conduct comprehensive experiments to investigate the effectiveness of the proposed approach. We compare the performance of the multimodal and unimodal postoperative pain assessment, and measure the impact of temporal information integration. The experimental results, on a real-world dataset, show that the proposed multimodal spatio-temporal approach achieves the highest AUC (0.87) and accuracy (79%), which are on average 6.67% and 6.33% higher than unimodal approaches. The results also show that the integration of temporal information markedly improves the performance as compared to the non-temporal approach as it captures changes in the pain dynamic. These results demonstrate that the proposed approach can be used as a viable alternative to manual assessment, which would tread a path toward fully automated pain monitoring in clinical settings, point-of-care testing, and homes.
First Investigation Into the Use of Deep Learning for Continuous Assessment of Neonatal Postoperative Pain
Mar 24, 2020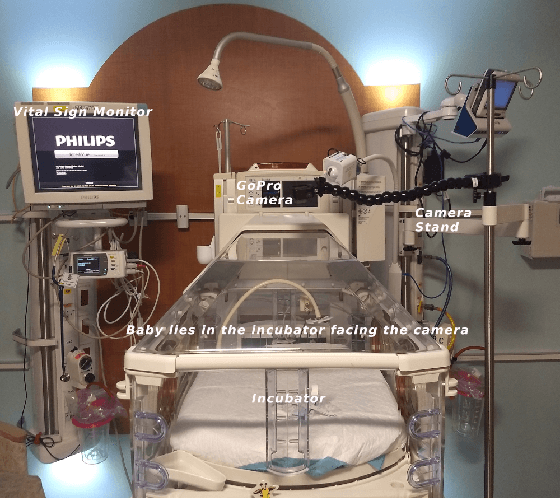
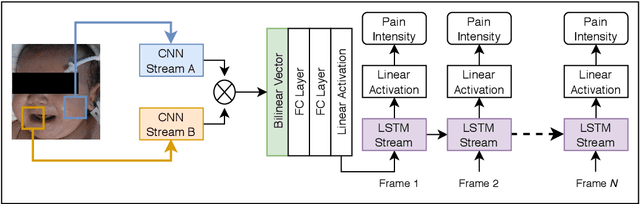
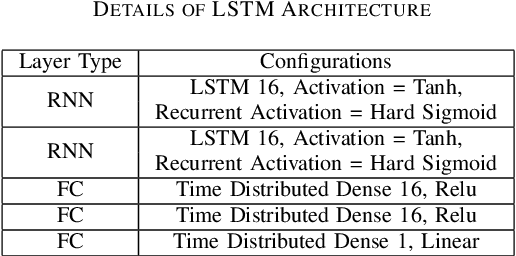
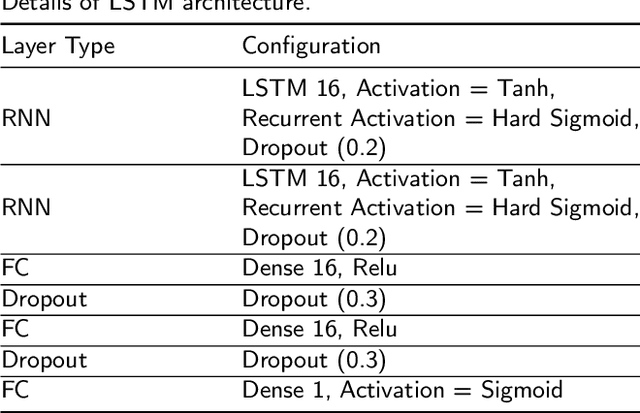
This paper presents the first investigation into the use of fully automated deep learning framework for assessing neonatal postoperative pain. It specifically investigates the use of Bilinear Convolutional Neural Network (B-CNN) to extract facial features during different levels of postoperative pain followed by modeling the temporal pattern using Recurrent Neural Network (RNN). Although acute and postoperative pain have some common characteristics (e.g., visual action units), postoperative pain has a different dynamic, and it evolves in a unique pattern over time. Our experimental results indicate a clear difference between the pattern of acute and postoperative pain. They also suggest the efficiency of using a combination of bilinear CNN with RNN model for the continuous assessment of postoperative pain intensity.
Harnessing the Power of Deep Learning Methods in Healthcare: Neonatal Pain Assessment from Crying Sound
Sep 05, 2019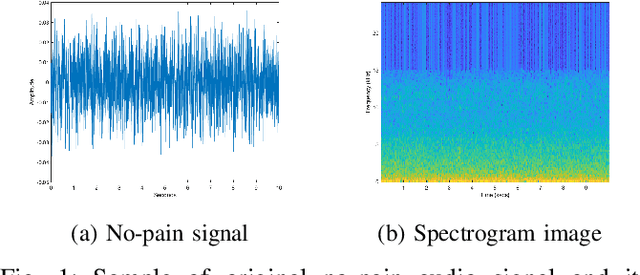
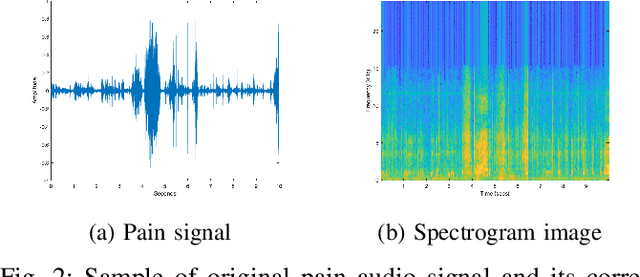
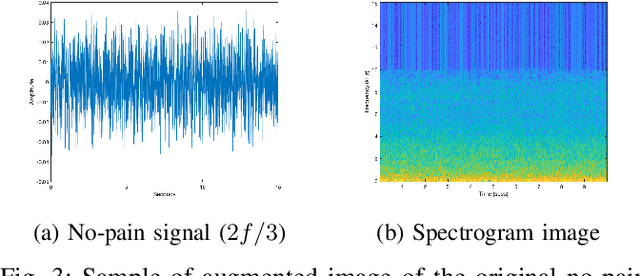
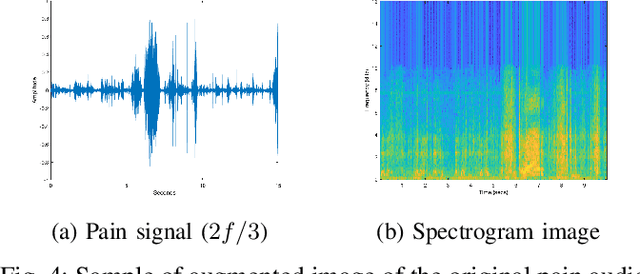
Neonatal pain assessment in clinical environments is challenging as it is discontinuous and biased. Facial/body occlusion can occur in such settings due to clinical condition, developmental delays, prone position, or other external factors. In such cases, crying sound can be used to effectively assess neonatal pain. In this paper, we investigate the use of a novel CNN architecture (N-CNN) along with other CNN architectures (VGG16 and ResNet50) for assessing pain from crying sounds of neonates. The experimental results demonstrate that using our novel N-CNN for assessing pain from the sounds of neonates has a strong clinical potential and provides a viable alternative to the current assessment practice.
Multi-Channel Neural Network for Assessing Neonatal Pain from Videos
Aug 25, 2019
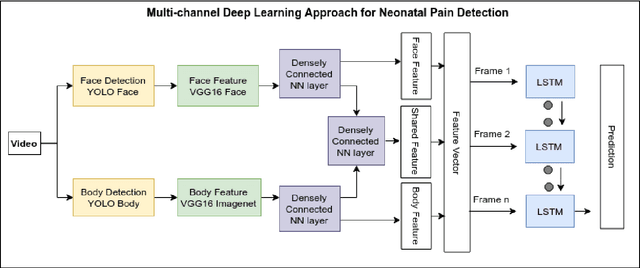
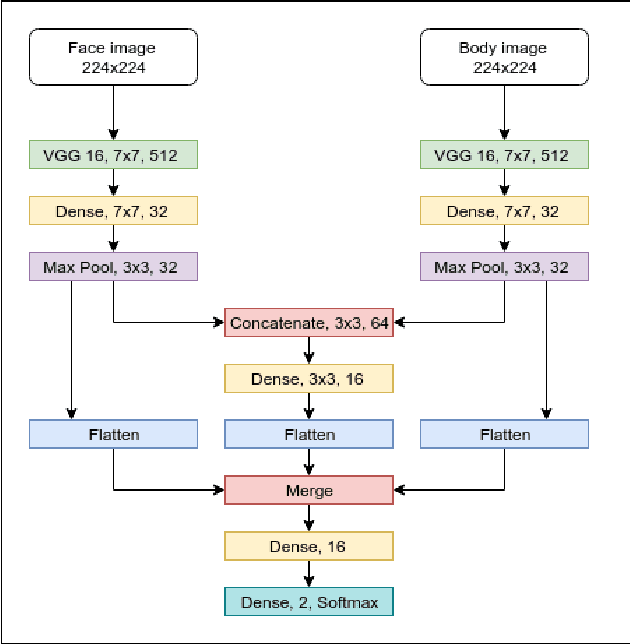
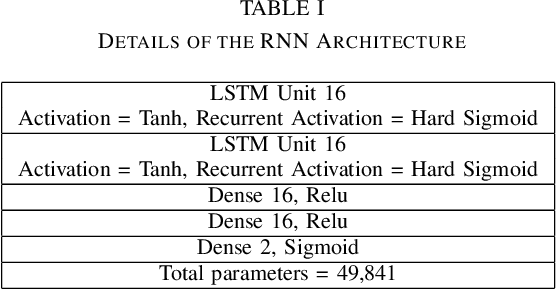
Neonates do not have the ability to either articulate pain or communicate it non-verbally by pointing. The current clinical standard for assessing neonatal pain is intermittent and highly subjective. This discontinuity and subjectivity can lead to inconsistent assessment, and therefore, inadequate treatment. In this paper, we propose a multi-channel deep learning framework for assessing neonatal pain from videos. The proposed framework integrates information from two pain indicators or channels, namely facial expression and body movement, using convolutional neural network (CNN). It also integrates temporal information using a recurrent neural network (LSTM). The experimental results prove the efficiency and superiority of the proposed temporal and multi-channel framework as compared to existing similar methods.