 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Injection: Improving Out-of-Distribution Generalization for Limited Size Datasets
Nov 05, 2025


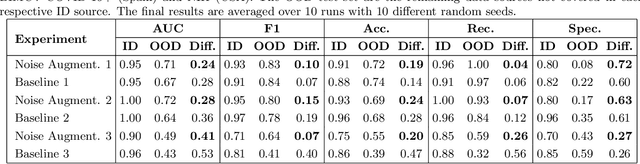
Deep learned (DL) models for image recognition have been shown to fail to generalize to data from different devices, populations, etc. COVID-19 detection from Chest X-rays (CXRs), in particular, has been shown to fail to generalize to out-of-distribution (OOD) data from new clinical sources not covered in the training set. This occurs because models learn to exploit shortcuts - source-specific artifacts that do not translate to new distributions - rather than reasonable biomarkers to maximize performance on in-distribution (ID) data. Rendering the models more robust to distribution shifts, our study investigates the use of fundamental noise injection techniques (Gaussian, Speckle, Poisson, and Salt and Pepper) during training. Our empirical results demonstrate that this technique can significantly reduce the performance gap between ID and OOD evaluation from 0.10-0.20 to 0.01-0.06, based on results averaged over ten random seeds across key metrics such as AUC, F1, accuracy, recall and specificity. Our source code is publicly available at https://github.com/Duongmai127/Noisy-ood
A Preliminary Study on Using Large Language Models in Software Pentesting
Jan 30, 2024Large language models (LLM) are perceived to offer promising potentials for automating security tasks, such as those found in security operation centers (SOCs). As a first step towards evaluating this perceived potential, we investigate the use of LLMs in software pentesting, where the main task is to automatically identify software security vulnerabilities in source code. We hypothesize that an LLM-based AI agent can be improved over time for a specific security task as human operators interact with it. Such improvement can be made, as a first step, by engineering prompts fed to the LLM based on the responses produced, to include relevant contexts and structures so that the model provides more accurate results. Such engineering efforts become sustainable if the prompts that are engineered to produce better results on current tasks, also produce better results on future unknown tasks. To examine this hypothesis, we utilize the OWASP Benchmark Project 1.2 which contains 2,740 hand-crafted source code test cases containing various types of vulnerabilities. We divide the test cases into training and testing data, where we engineer the prompts based on the training data (only), and evaluate the final system on the testing data. We compare the AI agent's performance on the testing data against the performance of the agent without the prompt engineering. We also compare the AI agent's results against those from SonarQube, a widely used static code analyzer for security testing. We built and tested multiple versions of the AI agent using different off-the-shelf LLMs -- Google's Gemini-pro, as well as OpenAI's GPT-3.5-Turbo and GPT-4-Turbo (with both chat completion and assistant APIs). The results show that using LLMs is a viable approach to build an AI agent for software pentesting that can improve through repeated use and prompt engineering.
Simulating User-Level Twitter Activity with XGBoost and Probabilistic Hybrid Models
Feb 18, 2022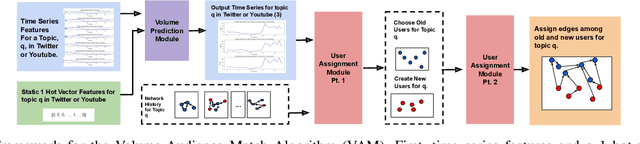
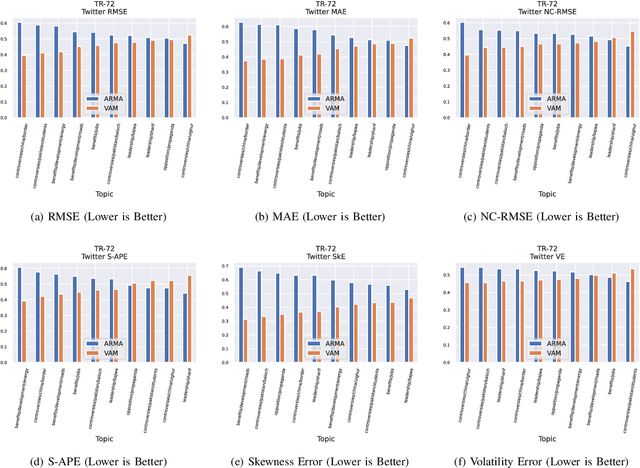
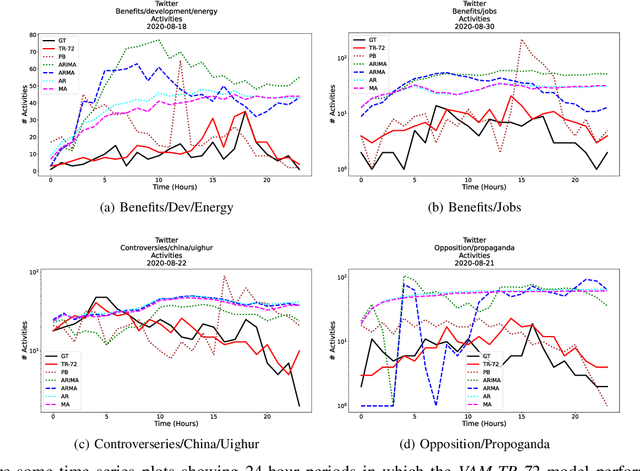
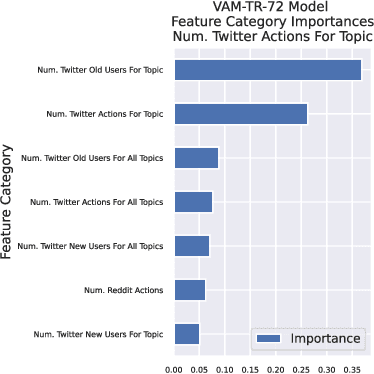
The Volume-Audience-Match simulator, or VAM was applied to predict future activity on Twitter related to international economic affairs. VAM was applied to do timeseries forecasting to predict the: (1) number of total activities, (2) number of active old users, and (3) number of newly active users over the span of 24 hours from the start time of prediction. VAM then used these volume predictions to perform user link predictions. A user-user edge was assigned to each of the activities in the 24 future timesteps. VAM considerably outperformed a set of baseline models in both the time series and user-assignment tasks