 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 28, 2023



Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.
Blind Image Deconvolution Using Variational Deep Image Prior
Feb 01, 2022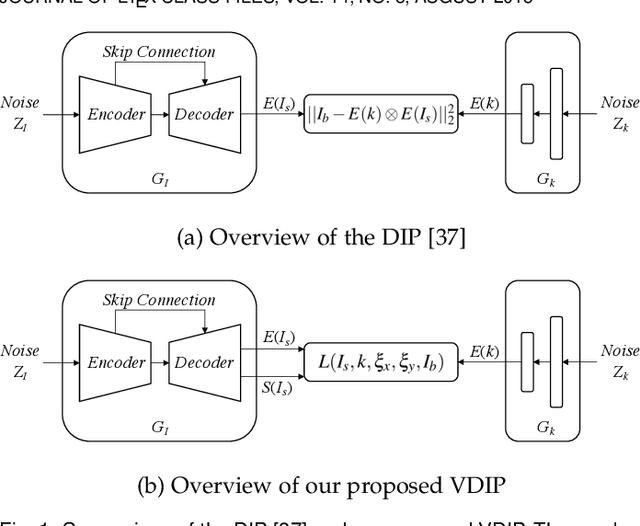
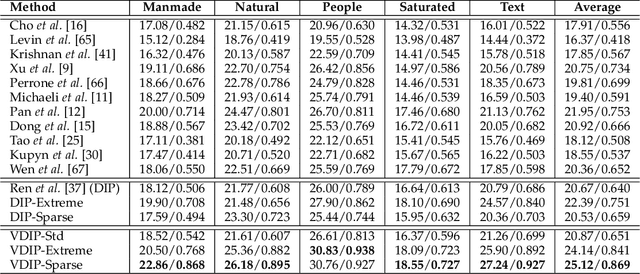
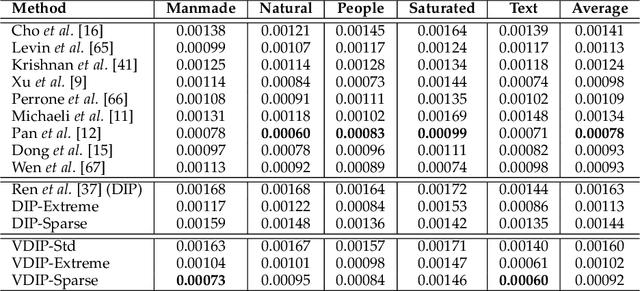
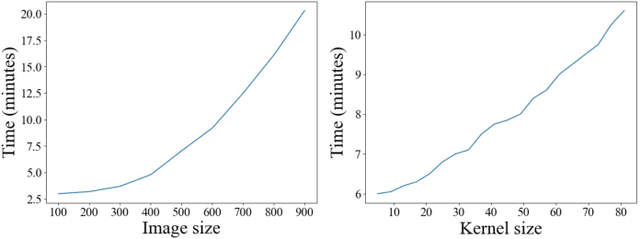
Conventional deconvolution methods utilize hand-crafted image priors to constrain the optimization. While deep-learning-based methods have simplified the optimization by end-to-end training, they fail to generalize well to blurs unseen in the training dataset. Thus, training image-specific models is important for higher generalization. Deep image prior (DIP) provides an approach to optimize the weights of a randomly initialized network with a single degraded image by maximum a posteriori (MAP), which shows that the architecture of a network can serve as the hand-crafted image prior. Different from the conventional hand-crafted image priors that are statistically obtained, it is hard to find a proper network architecture because the relationship between images and their corresponding network architectures is unclear. As a result, the network architecture cannot provide enough constraint for the latent sharp image. This paper proposes a new variational deep image prior (VDIP) for blind image deconvolution, which exploits additive hand-crafted image priors on latent sharp images and approximates a distribution for each pixel to avoid suboptimal solutions. Our mathematical analysis shows that the proposed method can better constrain the optimization. The experimental results further demonstrate that the generated images have better quality than that of the original DIP on benchmark datasets. The source code of our VDIP is available at https://github.com/Dong-Huo/VDIP-Deconvolution.
Contrast Enhancement of Medical X-Ray Image Using Morphological Operators with Optimal Structuring Element
May 21, 2019

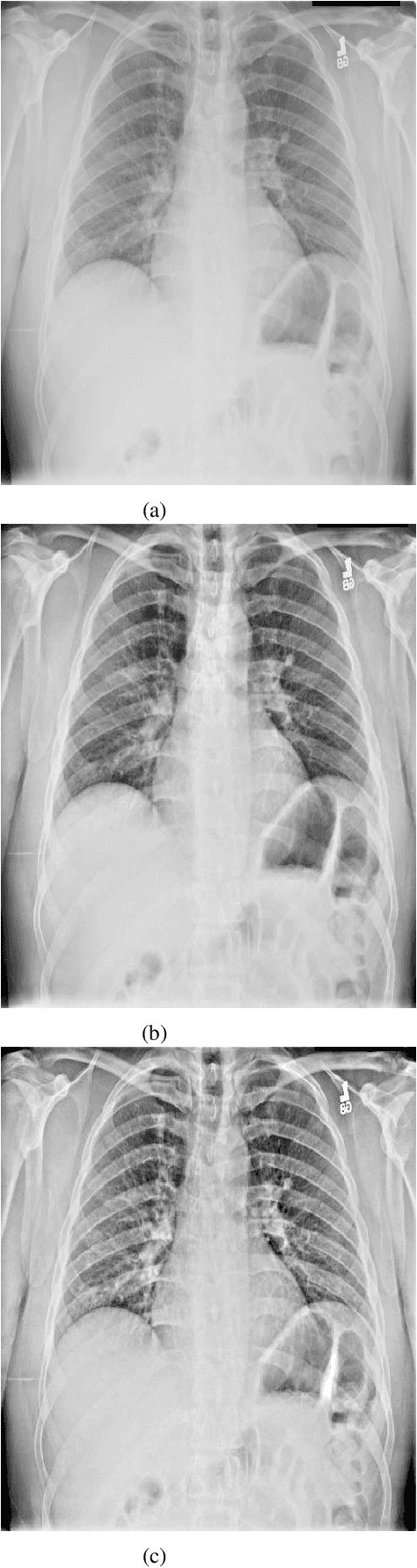
To guide surgical and medical treatment X-ray images have been used by physicians in every modern healthcare organization and hospitals. Doctor's evaluation process and disease identification in the area of skeletal system can be performed in a faster and efficient way with the help of X-ray imaging technique as they can depict bone structure painlessly. This paper presents an efficient contrast enhancement technique using morphological operators which will help to visualize important bone segments and soft tissues more clearly. Top-hat and Bottom-hat transform are utilized to enhance the image where gradient magnitude value is calculated for automatically selecting the structuring element (SE) size. Experimental evaluation on different x-ray imaging databases shows the effectiveness of our method which also produces comparatively better output against some existing image enhancement techniques.