 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Image Deconvolution Using Variational Deep Image Prior
Feb 01, 2022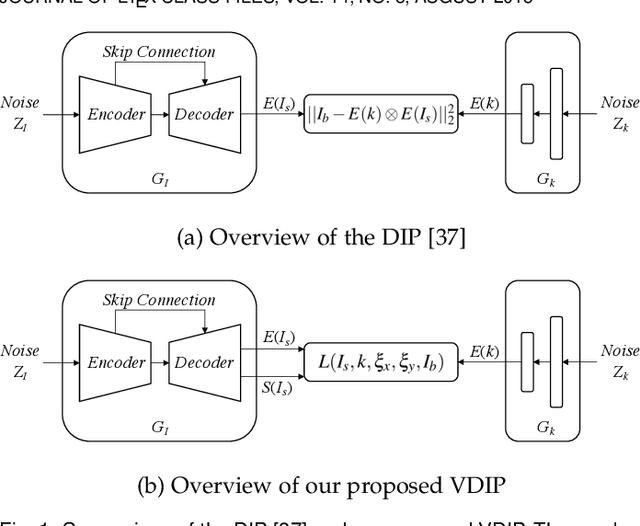
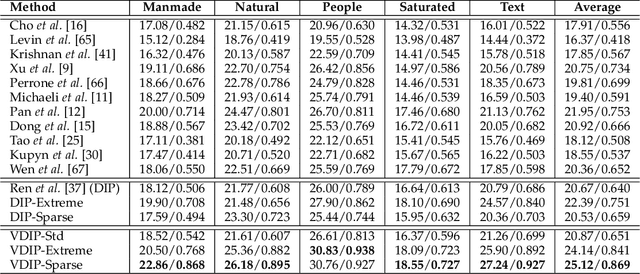
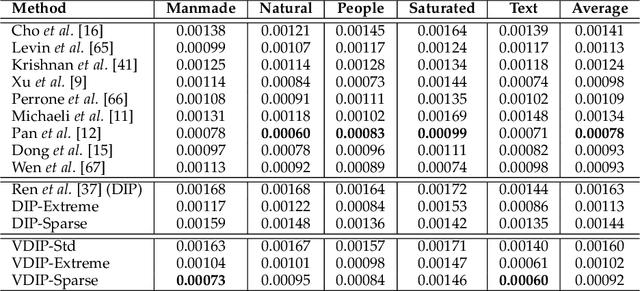
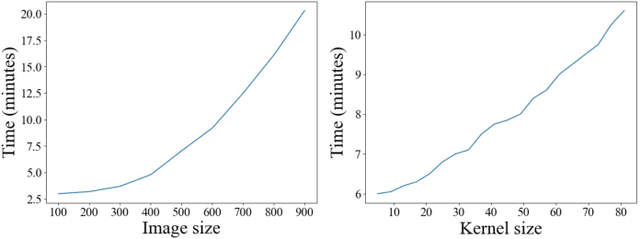
Conventional deconvolution methods utilize hand-crafted image priors to constrain the optimization. While deep-learning-based methods have simplified the optimization by end-to-end training, they fail to generalize well to blurs unseen in the training dataset. Thus, training image-specific models is important for higher generalization. Deep image prior (DIP) provides an approach to optimize the weights of a randomly initialized network with a single degraded image by maximum a posteriori (MAP), which shows that the architecture of a network can serve as the hand-crafted image prior. Different from the conventional hand-crafted image priors that are statistically obtained, it is hard to find a proper network architecture because the relationship between images and their corresponding network architectures is unclear. As a result, the network architecture cannot provide enough constraint for the latent sharp image. This paper proposes a new variational deep image prior (VDIP) for blind image deconvolution, which exploits additive hand-crafted image priors on latent sharp images and approximates a distribution for each pixel to avoid suboptimal solutions. Our mathematical analysis shows that the proposed method can better constrain the optimization. The experimental results further demonstrate that the generated images have better quality than that of the original DIP on benchmark datasets. The source code of our VDIP is available at https://github.com/Dong-Huo/VDIP-Deconvolution.
Blind Non-Uniform Motion Deblurring using Atrous Spatial Pyramid Deformable Convolution and Deblurring-Reblurring Consistency
Jun 27, 2021



Many deep learning based methods are designed to remove non-uniform (spatially variant) motion blur caused by object motion and camera shake without knowing the blur kernel. Some methods directly output the latent sharp image in one stage, while others utilize a multi-stage strategy (\eg multi-scale, multi-patch, or multi-temporal) to gradually restore the sharp image. However, these methods have the following two main issues: 1) The computational cost of multi-stage is high; 2) The same convolution kernel is applied in different regions, which is not an ideal choice for non-uniform blur. Hence, non-uniform motion deblurring is still a challenging and open problem. In this paper, we propose a new architecture which consists of multiple Atrous Spatial Pyramid Deformable Convolution (ASPDC) modules to deblur an image end-to-end with more flexibility. Multiple ASPDC modules implicitly learn the pixel-specific motion with different dilation rates in the same layer to handle movements of different magnitude. To improve the training, we also propose a reblurring network to map the deblurred output back to the blurred input, which constrains the solution space. Our experimental results show that the proposed method outperforms state-of-the-art methods on the benchmark datasets.