 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalorie Aware Automatic Meal Kit Generation from an Image
Dec 18, 2021


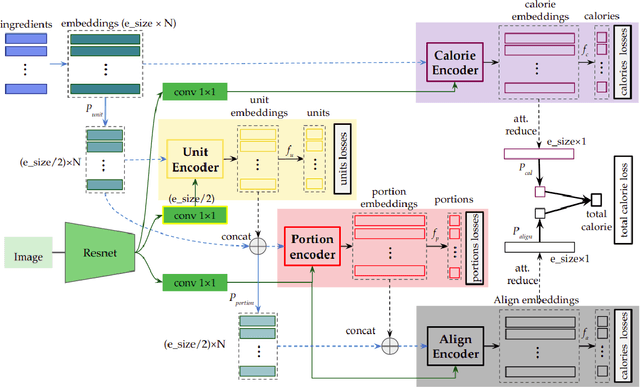
Calorie and nutrition research has attained increased interest in recent years. But, due to the complexity of the problem, literature in this area focuses on a limited subset of ingredients or dish types and simple convolutional neural networks or traditional machine learning. Simultaneously, estimation of ingredient portions can help improve calorie estimation and meal re-production from a given image. In this paper, given a single cooking image, a pipeline for calorie estimation and meal re-production for different servings of the meal is proposed. The pipeline contains two stages. In the first stage, a set of ingredients associated with the meal in the given image are predicted. In the second stage, given image features and ingredients, portions of the ingredients and finally the total meal calorie are simultaneously estimated using a deep transformer-based model. Portion estimation introduced in the model helps improve calorie estimation and is also beneficial for meal re-production in different serving sizes. To demonstrate the benefits of the pipeline, the model can be used for meal kits generation. To evaluate the pipeline, the large scale dataset Recipe1M is used. Prior to experiments, the Recipe1M dataset is parsed and explicitly annotated with portions of ingredients. Experiments show that using ingredients and their portions significantly improves calorie estimation. Also, a visual interface is created in which a user can interact with the pipeline to reach accurate calorie estimations and generate a meal kit for cooking purposes.
Joint Object and State Recognition using Language Knowledge
May 13, 2019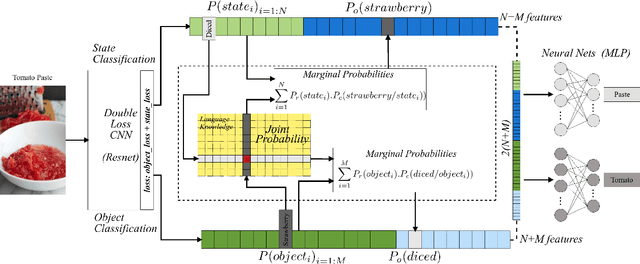
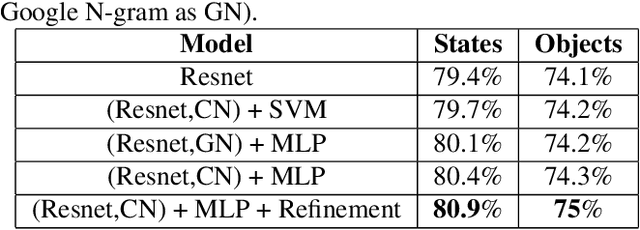
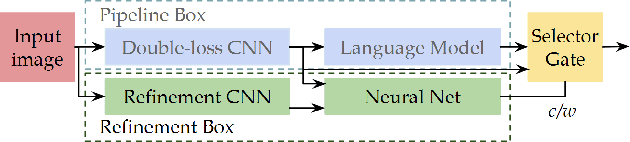

The state of an object is an important piece of knowledge in robotics applications. States and objects are intertwined together, meaning that object information can help recognize the state of an image and vice versa. This paper addresses the state identification problem in cooking related images and uses state and object predictions together to improve the classification accuracy of objects and their states from a single image. The pipeline presented in this paper includes a CNN with a double classification layer and the Concept-Net language knowledge graph on top. The language knowledge creates a semantic likelihood between objects and states. The resulting object and state confidences from the deep architecture are used together with object and state relatedness estimates from a language knowledge graph to produce marginal probabilities for objects and states. The marginal probabilities and confidences of objects (or states) are fused together to improve the final object (or state) classification results. Experiments on a dataset of cooking objects show that using a language knowledge graph on top of a deep neural network effectively enhances object and state classification.
Identifying Object States in Cooking-Related Images
Oct 30, 2018
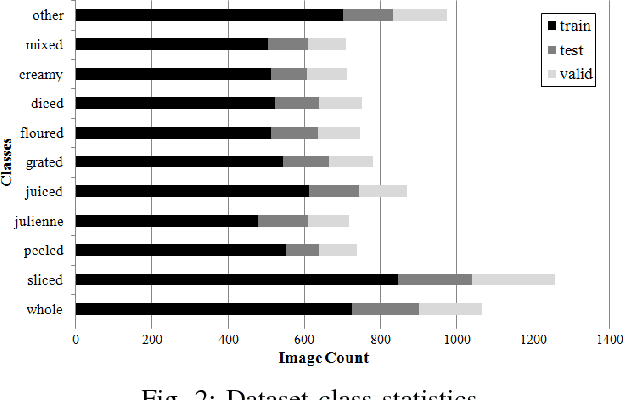

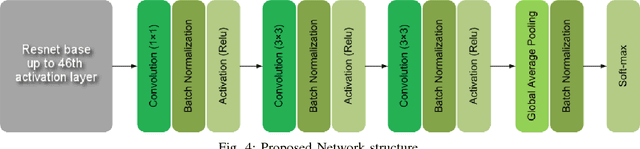
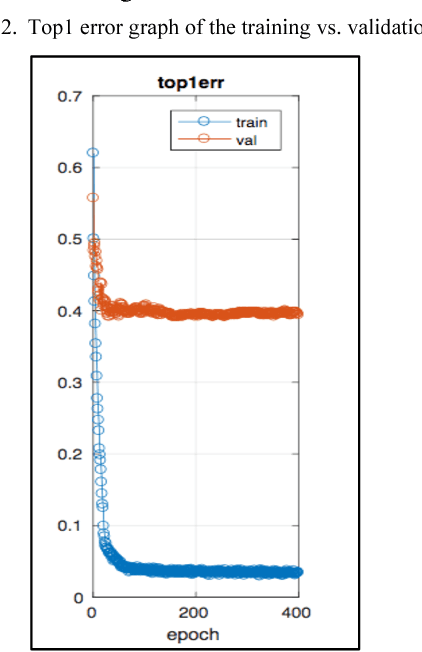
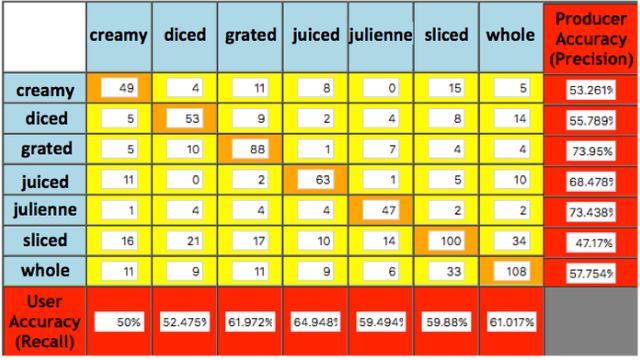
Understanding object states is as important as object recognition for robotic task planning and manipulation. To our knowledge, this paper explicitly introduces and addresses the state identification problem in cooking related images for the first time. In this paper, objects and ingredients in cooking videos are explored and the most frequent objects are analyzed. Eleven states from the most frequent cooking objects are examined and a dataset of images containing those objects and their states is created. As a solution to the state identification problem, a Resnet based deep model is proposed. The model is initialized with Imagenet weights and trained on the dataset of eleven classes. The trained state identification model is evaluated on a subset of the Imagenet dataset and state labels are provided using a combination of the model with manual checking. Moreover, an individual model is fine-tuned for each object in the dataset using the weights from the initially trained model and object-specific images, where significant improvement is demonstrated.
Fine-Tuning VGG Neural Network For Fine-grained State Recognition of Food Images
Sep 08, 2018

State recognition of food images can be considered as one of the promising applications of object recognition and fine-grained image classification in computer vision. In this paper, evidence is provided for the power of convolutional neural network (CNN) for food state recognition, even with a small data set. In this study, we fine-tuned a CNN initially trained on a large natural image recognition dataset (Imagenet ILSVRC) and transferred the learned feature representations to the food state recognition task. A small-scale dataset consisting of 5978 images of seven categories was constructed and annotated manually. Data augmentation was applied to increase the size of the data.
Functional Object-Oriented Network: Construction & Expansion
Jul 05, 2018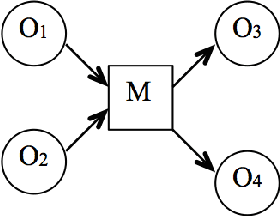
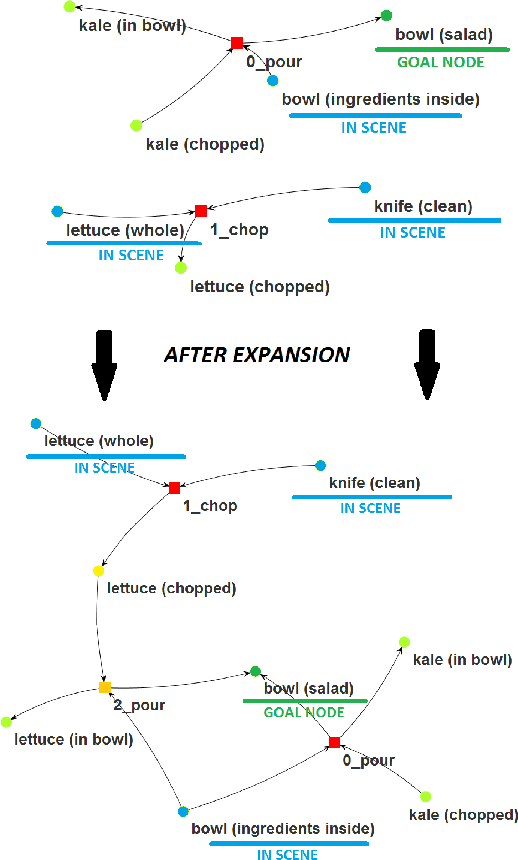
We build upon the functional object-oriented network (FOON), a structured knowledge representation which is constructed from observations of human activities and manipulations. A FOON can be used for representing object-motion affordances. Knowledge retrieval through graph search allows us to obtain novel manipulation sequences using knowledge spanning across many video sources, hence the novelty in our approach. However, we are limited to the sources collected. To further improve the performance of knowledge retrieval as a follow up to our previous work, we discuss generalizing knowledge to be applied to objects which are similar to what we have in FOON without manually annotating new sources of knowledge. We discuss two means of generalization: 1) expanding our network through the use of object similarity to create new functional units from those we already have, and 2) compressing the functional units by object categories rather than specific objects. We discuss experiments which compare the performance of our knowledge retrieval algorithm with both expansion and compression by categories.
Long Activity Video Understanding using Functional Object-Oriented Network
Jul 03, 2018

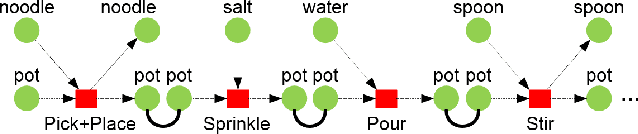
Video understanding is one of the most challenging topics in computer vision. In this paper, a four-stage video understanding pipeline is presented to simultaneously recognize all atomic actions and the single on-going activity in a video. This pipeline uses objects and motions from the video and a graph-based knowledge representation network as prior reference. Two deep networks are trained to identify objects and motions in each video sequence associated with an action. Low Level image features are then used to identify objects of interest in that video sequence. Confidence scores are assigned to objects of interest based on their involvement in the action and to motion classes based on results from a deep neural network that classifies the on-going action in video into motion classes. Confidence scores are computed for each candidate functional unit associated with an action using a knowledge representation network, object confidences, and motion confidences. Each action is therefore associated with a functional unit and the sequence of actions is further evaluated to identify the single on-going activity in the video. The knowledge representation used in the pipeline is called the functional object-oriented network which is a graph-based network useful for encoding knowledge about manipulation tasks. Experiments are performed on a dataset of cooking videos to test the proposed algorithm with action inference and activity classification. Experiments show that using functional object oriented network improves video understanding significantly.
Cooking State Recognition From Images Using Inception Architecture
May 25, 2018



A kitchen robot properly needs to understand the cooking environment to continue any cooking activities. But object's state detection has not been researched well so far as like object detection. In this paper, we propose a deep learning approach to identify different cooking states from images for a kitchen robot. In our research, we investigate particularly the performance of Inception architecture and propose a modified architecture based on Inception model to classify different cooking states. The model is analyzed robustly in terms of different layers, and optimizers. Experimental results on a cooking datasets demonstrate that proposed model can be a potential solution to the cooking state recognition problem.