 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Activity Video Understanding using Functional Object-Oriented Network
Paper and Code
Jul 03, 2018
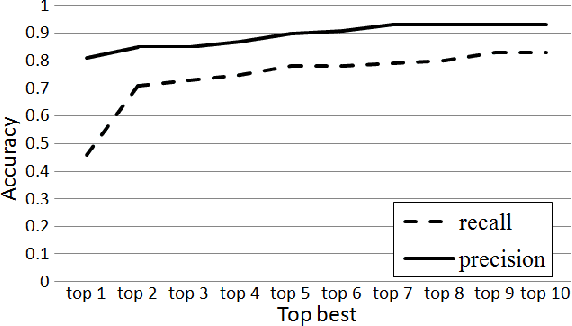

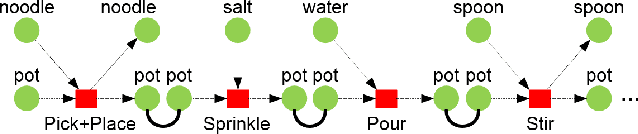
Video understanding is one of the most challenging topics in computer vision. In this paper, a four-stage video understanding pipeline is presented to simultaneously recognize all atomic actions and the single on-going activity in a video. This pipeline uses objects and motions from the video and a graph-based knowledge representation network as prior reference. Two deep networks are trained to identify objects and motions in each video sequence associated with an action. Low Level image features are then used to identify objects of interest in that video sequence. Confidence scores are assigned to objects of interest based on their involvement in the action and to motion classes based on results from a deep neural network that classifies the on-going action in video into motion classes. Confidence scores are computed for each candidate functional unit associated with an action using a knowledge representation network, object confidences, and motion confidences. Each action is therefore associated with a functional unit and the sequence of actions is further evaluated to identify the single on-going activity in the video. The knowledge representation used in the pipeline is called the functional object-oriented network which is a graph-based network useful for encoding knowledge about manipulation tasks. Experiments are performed on a dataset of cooking videos to test the proposed algorithm with action inference and activity classification. Experiments show that using functional object oriented network improves video understanding significantly.