 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompt to Production:Automating Brand-Safe Marketing Imagery with Text-to-Image Models
Feb 12, 2026Text-to-image models have made significant strides, producing impressive results in generating images from textual descriptions. However, creating a scalable pipeline for deploying these models in production remains a challenge. Achieving the right balance between automation and human feedback is critical to maintain both scale and quality. While automation can handle large volumes, human oversight is still an essential component to ensure that the generated images meet the desired standards and are aligned with the creative vision. This paper presents a new pipeline that offers a fully automated, scalable solution for generating marketing images of commercial products using text-to-image models. The proposed system maintains the quality and fidelity of images, while also introducing sufficient creative variation to adhere to marketing guidelines. By streamlining this process, we ensure a seamless blend of efficiency and human oversight, achieving a $30.77\%$ increase in marketing object fidelity using DINOV2 and a $52.00\%$ increase in human preference over the generated outcome.
Agentic generative AI for media content discovery at the national football league
Oct 08, 2025Generative AI has unlocked new possibilities in content discovery and management. Through collaboration with the National Football League (NFL), we demonstrate how a generative-AI based workflow enables media researchers and analysts to query relevant historical plays using natural language rather than traditional filter-and-click interfaces. The agentic workflow takes a user query as input, breaks it into elements, and translates them into the underlying database query language. Accuracy and latency are further improved through carefully designed semantic caching. The solution achieves over 95 percent accuracy and reduces the average time to find relevant videos from 10 minutes to 30 seconds, significantly increasing the NFL's operational efficiency and allowing users to focus on producing creative content and engaging storylines.
Domain Adaptation of VLM for Soccer Video Understanding
May 20, 2025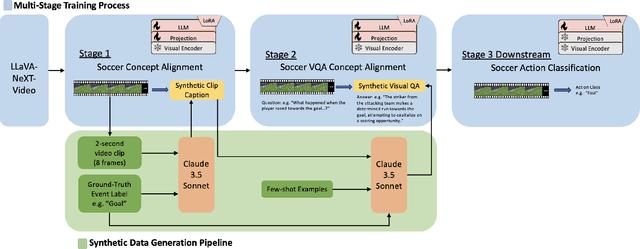

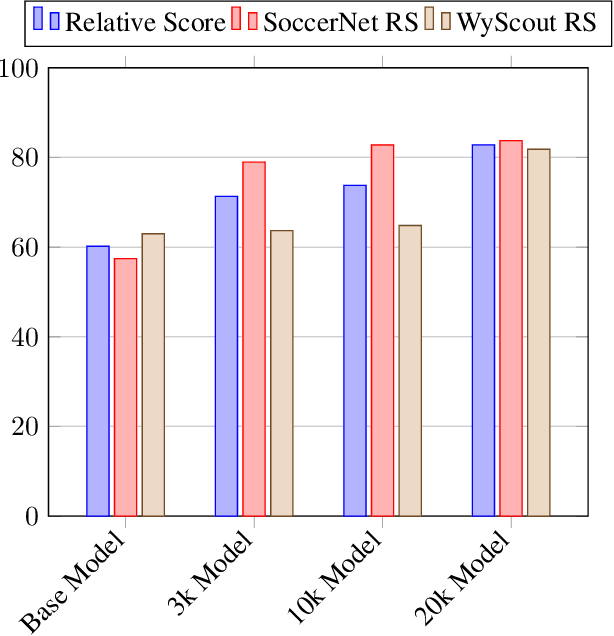

Vision Language Models (VLMs) have demonstrated strong performance in multi-modal tasks by effectively aligning visual and textual representations. However, most video understanding VLM research has been domain-agnostic, leaving the understanding of their transfer learning capability to specialized domains under-explored. In this work, we address this by exploring the adaptability of open-source VLMs to specific domains, and focusing on soccer as an initial case study. Our approach uses large-scale soccer datasets and LLM to create instruction-following data, and use them to iteratively fine-tune the general-domain VLM in a curriculum learning fashion (first teaching the model key soccer concepts to then question answering tasks). The final adapted model, trained using a curated dataset of 20k video clips, exhibits significant improvement in soccer-specific tasks compared to the base model, with a 37.5% relative improvement for the visual question-answering task and an accuracy improvement from 11.8% to 63.5% for the downstream soccer action classification task.
Robust Segmentation of CPR-Induced Capnogram Using U-net: Overcoming Challenges with Deep Learning
Oct 28, 2024Objective: The accurate segmentation of capnograms during cardiopulmonary resuscitation (CPR) is essential for effective patient monitoring and advanced airway management. This study aims to develop a robust algorithm using a U-net architecture to segment capnograms into inhalation and non-inhalation phases, and to demonstrate its superiority over state-of-the-art (SoA) methods in the presence of CPR-induced artifacts. Materials and methods: A total of 24354 segments of one minute extracted from 1587 patients were used to train and evaluate the model. The proposed U-net architecture was tested using patient-wise 10-fold cross-validation. A set of five features was extracted for clustering analysis to evaluate the algorithm performance across different signal characteristics and contexts. The evaluation metrics included segmentation-level and ventilation-level metrics, including ventilation rate and end-tidal-CO$_2$ values. Results: The proposed U-net based algorithm achieved an F1-score of 98% for segmentation and 96% for ventilation detection, outperforming existing SoA methods by 4 points. The root mean square error for end-tidal-CO$_2$ and ventilation rate were 1.9 mmHg and 1.1 breaths per minute, respectively. Detailed performance metrics highlighted the algorithm's robustness against CPR-induced interferences and low amplitude signals. Clustering analysis further demonstrated consistent performance across various signal characteristics. Conclusion: The proposed U-net based segmentation algorithm improves the accuracy of capnogram analysis during CPR. Its enhanced performance in detecting inhalation phases and ventilation events offers a reliable tool for clinical applications, potentially improving patient outcomes during cardiac arrest.
Large-scale Crash Localization using Multi-Task Learning
Sep 29, 2021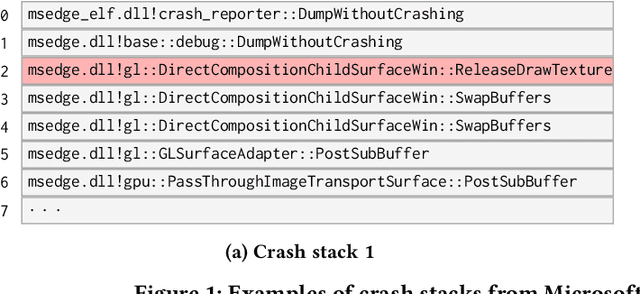

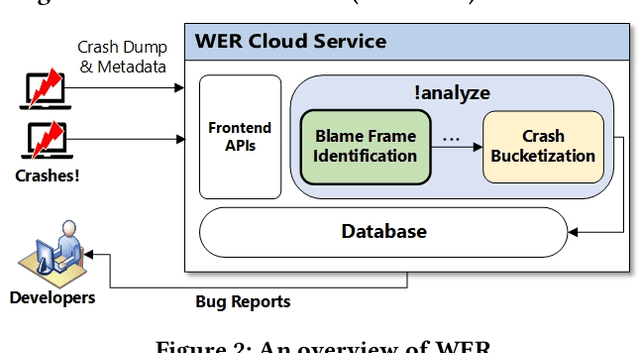
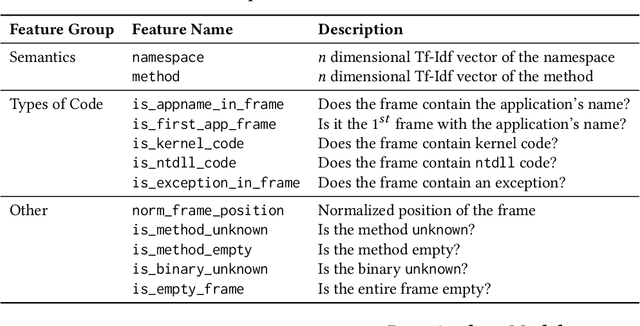
Crash localization, an important step in debugging crashes, is challenging when dealing with an extremely large number of diverse applications and platforms and underlying root causes. Large-scale error reporting systems, e.g., Windows Error Reporting (WER), commonly rely on manually developed rules and heuristics to localize blamed frames causing the crashes. As new applications and features are routinely introduced and existing applications are run under new environments, developing new rules and maintaining existing ones become extremely challenging. We propose a data-driven solution to address the problem. We start with the first large-scale empirical study of 362K crashes and their blamed methods reported to WER by tens of thousands of applications running in the field. The analysis provides valuable insights on where and how the crashes happen and what methods to blame for the crashes. These insights enable us to develop DeepAnalyze, a novel multi-task sequence labeling approach for identifying blamed frames in stack traces. We evaluate our model with over a million real-world crashes from four popular Microsoft applications and show that DeepAnalyze, trained with crashes from one set of applications, not only accurately localizes crashes of the same applications, but also bootstraps crash localization for other applications with zero to very little additional training data.
Trinity: A No-Code AI platform for complex spatial datasets
Jul 01, 2021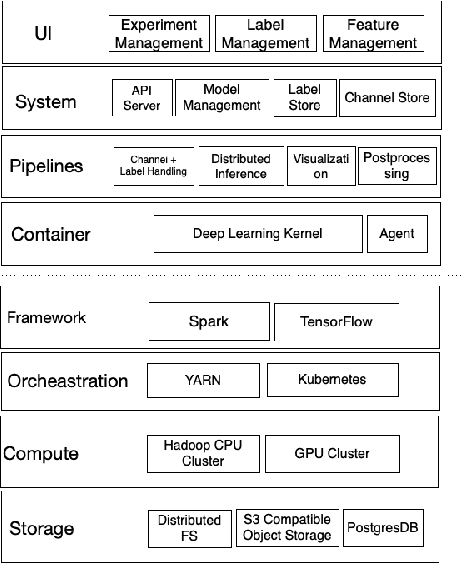
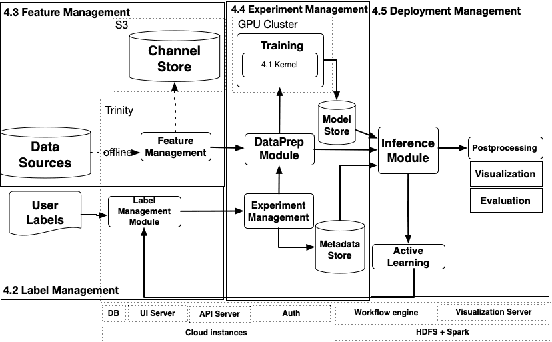
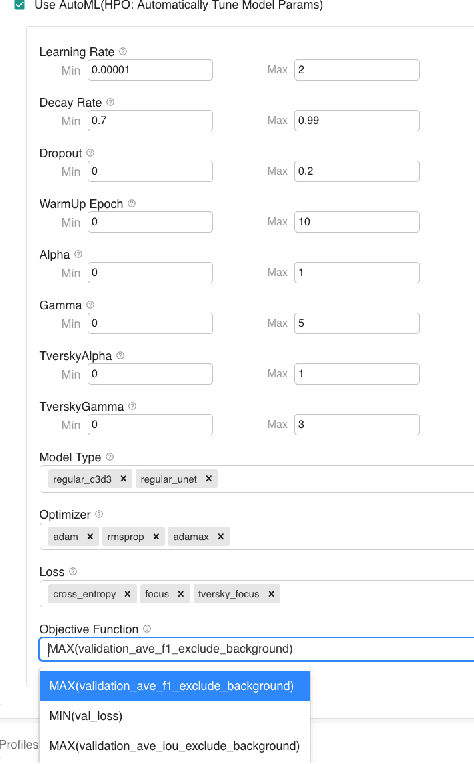

We present a no-code Artificial Intelligence (AI) platform called Trinity with the main design goal of enabling both machine learning researchers and non-technical geospatial domain experts to experiment with domain-specific signals and datasets for solving a variety of complex problems on their own. This versatility to solve diverse problems is achieved by transforming complex Spatio-temporal datasets to make them consumable by standard deep learning models, in this case, Convolutional Neural Networks (CNNs), and giving the ability to formulate disparate problems in a standard way, eg. semantic segmentation. With an intuitive user interface, a feature store that hosts derivatives of complex feature engineering, a deep learning kernel, and a scalable data processing mechanism, Trinity provides a powerful platform for domain experts to share the stage with scientists and engineers in solving business-critical problems. It enables quick prototyping, rapid experimentation and reduces the time to production by standardizing model building and deployment. In this paper, we present our motivation behind Trinity and its design along with showcasing sample applications to motivate the idea of lowering the bar to using AI.
Single View Physical Distance Estimation using Human Pose
Jun 18, 2021
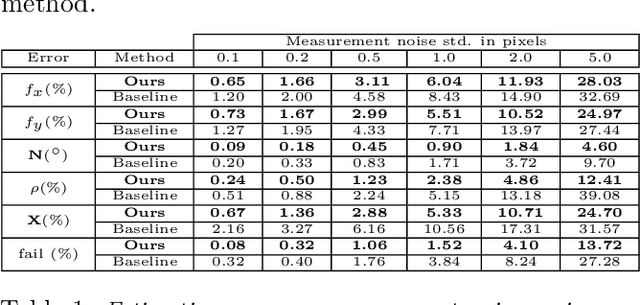
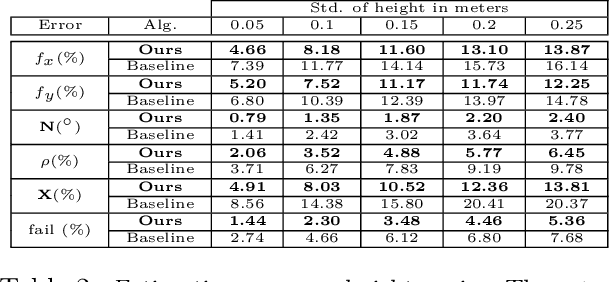
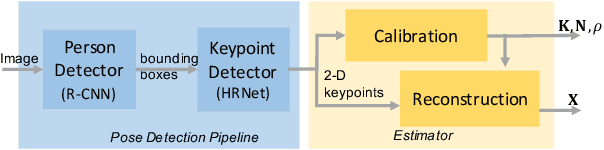
We propose a fully automated system that simultaneously estimates the camera intrinsics, the ground plane, and physical distances between people from a single RGB image or video captured by a camera viewing a 3-D scene from a fixed vantage point. To automate camera calibration and distance estimation, we leverage priors about human pose and develop a novel direct formulation for pose-based auto-calibration and distance estimation, which shows state-of-the-art performance on publicly available datasets. The proposed approach enables existing camera systems to measure physical distances without needing a dedicated calibration process or range sensors, and is applicable to a broad range of use cases such as social distancing and workplace safety. Furthermore, to enable evaluation and drive research in this area, we contribute to the publicly available MEVA dataset with additional distance annotations, resulting in MEVADA -- the first evaluation benchmark in the world for the pose-based auto-calibration and distance estimation problem.