 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
Learning to Ideate for Machine Learning Engineering Agents
Jan 24, 2026Existing machine learning engineering (MLE) agents struggle to iteratively optimize their implemented algorithms for effectiveness. To address this, we introduce MLE-Ideator, a dual-agent framework that separates ideation from implementation. In our system, an implementation agent can request strategic help from a dedicated Ideator. We show this approach is effective in two ways. First, in a training-free setup, our framework significantly outperforms implementation-only agent baselines on MLE-Bench. Second, we demonstrate that the Ideator can be trained with reinforcement learning (RL) to generate more effective ideas. With only 1K training samples from 10 MLE tasks, our RL-trained Qwen3-8B Ideator achieves an 11.5% relative improvement compared to its untrained counterpart and surpasses Claude Sonnet 3.5. These results highlights a promising path toward training strategic AI systems for scientific discovery.
Reinforcement Learning for Self-Improving Agent with Skill Library
Dec 18, 2025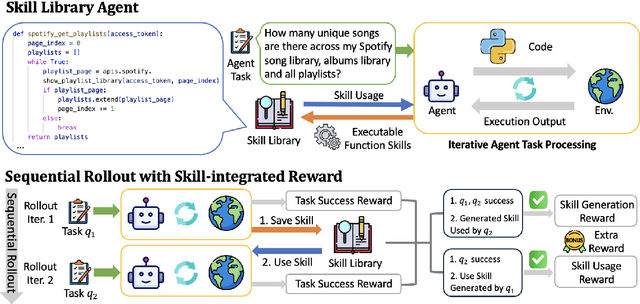
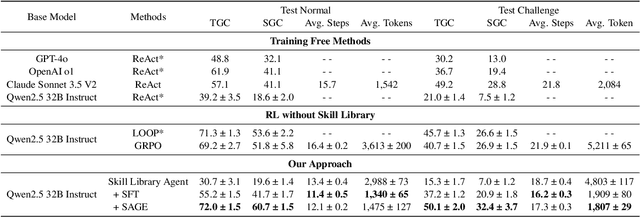
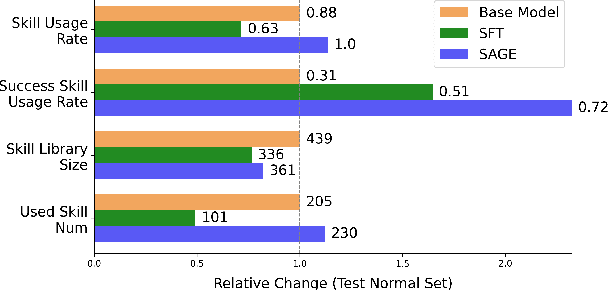
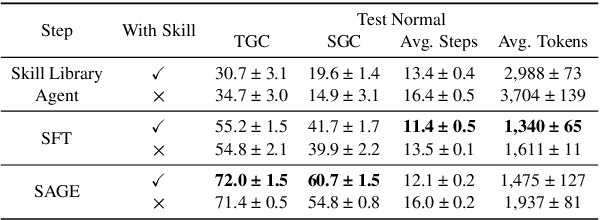
Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.
Diffusion Language Model Inference with Monte Carlo Tree Search
Dec 13, 2025Diffusion language models (DLMs) have recently emerged as a compelling alternative to autoregressive generation, offering parallel generation and improved global coherence. During inference, DLMs generate text by iteratively denoising masked sequences in parallel; however, determining which positions to unmask and which tokens to commit forms a large combinatorial search problem. Existing inference methods approximate this search using heuristics, which often yield suboptimal decoding paths; other approaches instead rely on additional training to guide token selection. To introduce a principled search mechanism for DLMs inference, we introduce MEDAL, a framework that integrates Monte Carlo Tree SEarch initialization for Diffusion LAnguage Model inference. We employ Monte Carlo Tree Search at the initialization stage to explore promising unmasking trajectories, providing a robust starting point for subsequent refinement. This integration is enabled by restricting the search space to high-confidence actions and prioritizing token choices that improve model confidence over remaining masked positions. Across multiple benchmarks, MEDAL achieves up to 22.0% improvement over existing inference strategies, establishing a new paradigm for search-based inference in diffusion language models.
PromptPrism: A Linguistically-Inspired Taxonomy for Prompts
May 19, 2025Prompts are the interface for eliciting the capabilities of large language models (LLMs). Understanding their structure and components is critical for analyzing LLM behavior and optimizing performance. However, the field lacks a comprehensive framework for systematic prompt analysis and understanding. We introduce PromptPrism, a linguistically-inspired taxonomy that enables prompt analysis across three hierarchical levels: functional structure, semantic component, and syntactic pattern. We show the practical utility of PromptPrism by applying it to three applications: (1) a taxonomy-guided prompt refinement approach that automatically improves prompt quality and enhances model performance across a range of tasks; (2) a multi-dimensional dataset profiling method that extracts and aggregates structural, semantic, and syntactic characteristics from prompt datasets, enabling comprehensive analysis of prompt distributions and patterns; (3) a controlled experimental framework for prompt sensitivity analysis by quantifying the impact of semantic reordering and delimiter modifications on LLM performance. Our experimental results validate the effectiveness of our taxonomy across these applications, demonstrating that PromptPrism provides a foundation for refining, profiling, and analyzing prompts.
Black-Box Visual Prompt Engineering for Mitigating Object Hallucination in Large Vision Language Models
Apr 30, 2025Large Vision Language Models (LVLMs) often suffer from object hallucination, which undermines their reliability. Surprisingly, we find that simple object-based visual prompting -- overlaying visual cues (e.g., bounding box, circle) on images -- can significantly mitigate such hallucination; however, different visual prompts (VPs) vary in effectiveness. To address this, we propose Black-Box Visual Prompt Engineering (BBVPE), a framework to identify optimal VPs that enhance LVLM responses without needing access to model internals. Our approach employs a pool of candidate VPs and trains a router model to dynamically select the most effective VP for a given input image. This black-box approach is model-agnostic, making it applicable to both open-source and proprietary LVLMs. Evaluations on benchmarks such as POPE and CHAIR demonstrate that BBVPE effectively reduces object hallucination.
Collaborative LLM Numerical Reasoning with Local Data Protection
Apr 01, 2025Numerical reasoning over documents, which demands both contextual understanding and logical inference, is challenging for low-capacity local models deployed on computation-constrained devices. Although such complex reasoning queries could be routed to powerful remote models like GPT-4, exposing local data raises significant data leakage concerns. Existing mitigation methods generate problem descriptions or examples for remote assistance. However, the inherent complexity of numerical reasoning hinders the local model from generating logically equivalent queries and accurately inferring answers with remote guidance. In this paper, we present a model collaboration framework with two key innovations: (1) a context-aware synthesis strategy that shifts the query domains while preserving logical consistency; and (2) a tool-based answer reconstruction approach that reuses the remote-generated problem-solving pattern with code snippets. Experimental results demonstrate that our method achieves better reasoning accuracy than solely using local models while providing stronger data protection than fully relying on remote models. Furthermore, our method improves accuracy by 16.2% - 43.6% while reducing data leakage by 2.3% - 44.6% compared to existing data protection approaches.
Enhancing Multi-hop Reasoning in Vision-Language Models via Self-Distillation with Multi-Prompt Ensembling
Mar 03, 2025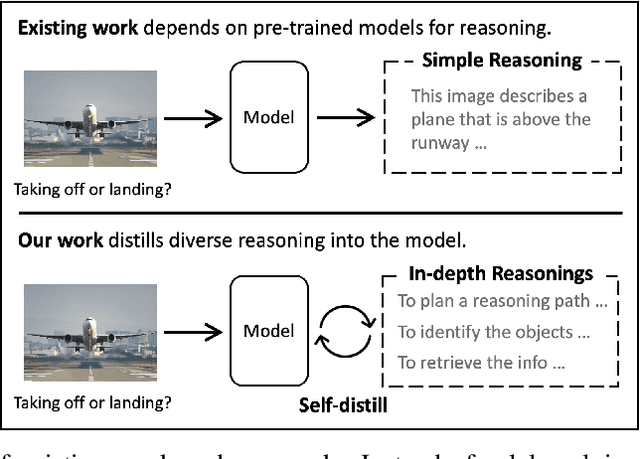

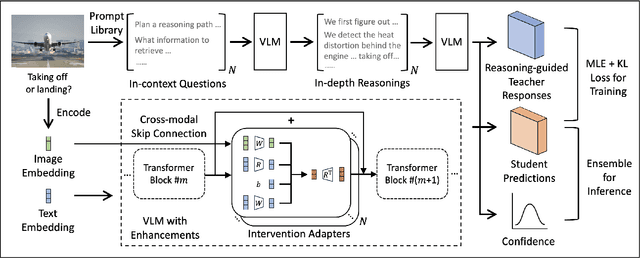

Multi-modal large language models have seen rapid advancement alongside large language models. However, while language models can effectively leverage chain-of-thought prompting for zero or few-shot learning, similar prompting strategies are less effective for multi-modal LLMs due to modality gaps and task complexity. To address this challenge, we explore two prompting approaches: a dual-query method that separates multi-modal input analysis and answer generation into two prompting steps, and an ensemble prompting method that combines multiple prompt variations to arrive at the final answer. Although these approaches enhance the model's reasoning capabilities without fine-tuning, they introduce significant inference overhead. Therefore, building on top of these two prompting techniques, we propose a self-distillation framework such that the model can improve itself without any annotated data. Our self-distillation framework learns representation intervention modules from the reasoning traces collected from ensembled dual-query prompts, in the form of hidden representations. The lightweight intervention modules operate in parallel with the frozen original model, which makes it possible to maintain computational efficiency while significantly improving model capability. We evaluate our method on five widely-used VQA benchmarks, demonstrating its effectiveness in performing multi-hop reasoning for complex tasks.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Explainability of Traditional and Deep Learning Models on Longitudinal Healthcare Records
Nov 22, 2022



Recent advances in deep learning have led to interest in training deep learning models on longitudinal healthcare records to predict a range of medical events, with models demonstrating high predictive performance. Predictive performance is necessary but insufficient, however, with explanations and reasoning from models required to convince clinicians for sustained use. Rigorous evaluation of explainability is often missing, as comparisons between models (traditional versus deep) and various explainability methods have not been well-studied. Furthermore, ground truths needed to evaluate explainability can be highly subjective depending on the clinician's perspective. Our work is one of the first to evaluate explainability performance between and within traditional (XGBoost) and deep learning (LSTM with Attention) models on both a global and individual per-prediction level on longitudinal healthcare data. We compared explainability using three popular methods: 1) SHapley Additive exPlanations (SHAP), 2) Layer-Wise Relevance Propagation (LRP), and 3) Attention. These implementations were applied on synthetically generated datasets with designed ground-truths and a real-world medicare claims dataset. We showed that overall, LSTMs with SHAP or LRP provides superior explainability compared to XGBoost on both the global and local level, while LSTM with dot-product attention failed to produce reasonable ones. With the explosion of the volume of healthcare data and deep learning progress, the need to evaluate explainability will be pivotal towards successful adoption of deep learning models in healthcare settings.