 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
Enhancing Multi-hop Reasoning in Vision-Language Models via Self-Distillation with Multi-Prompt Ensembling
Mar 03, 2025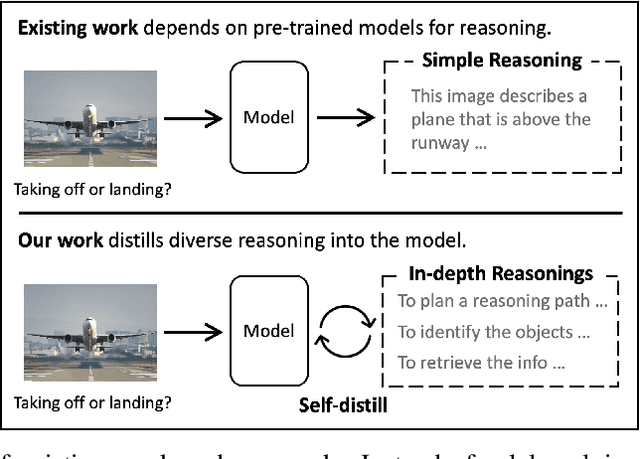

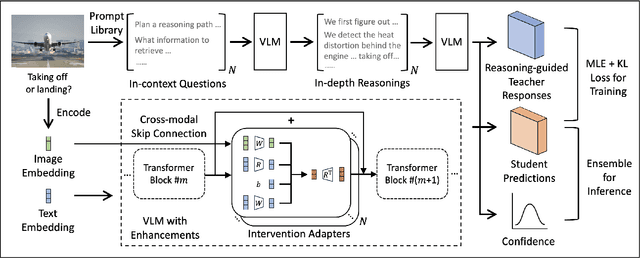

Multi-modal large language models have seen rapid advancement alongside large language models. However, while language models can effectively leverage chain-of-thought prompting for zero or few-shot learning, similar prompting strategies are less effective for multi-modal LLMs due to modality gaps and task complexity. To address this challenge, we explore two prompting approaches: a dual-query method that separates multi-modal input analysis and answer generation into two prompting steps, and an ensemble prompting method that combines multiple prompt variations to arrive at the final answer. Although these approaches enhance the model's reasoning capabilities without fine-tuning, they introduce significant inference overhead. Therefore, building on top of these two prompting techniques, we propose a self-distillation framework such that the model can improve itself without any annotated data. Our self-distillation framework learns representation intervention modules from the reasoning traces collected from ensembled dual-query prompts, in the form of hidden representations. The lightweight intervention modules operate in parallel with the frozen original model, which makes it possible to maintain computational efficiency while significantly improving model capability. We evaluate our method on five widely-used VQA benchmarks, demonstrating its effectiveness in performing multi-hop reasoning for complex tasks.
Satori: Towards Proactive AR Assistant with Belief-Desire-Intention User Modeling
Oct 22, 2024



Augmented Reality assistance are increasingly popular for supporting users with tasks like assembly and cooking. However, current practice typically provide reactive responses initialized from user requests, lacking consideration of rich contextual and user-specific information. To address this limitation, we propose a novel AR assistance system, Satori, that models both user states and environmental contexts to deliver proactive guidance. Our system combines the Belief-Desire-Intention (BDI) model with a state-of-the-art multi-modal large language model (LLM) to infer contextually appropriate guidance. The design is informed by two formative studies involving twelve experts. A sixteen within-subject study find that Satori achieves performance comparable to an designer-created Wizard-of-Oz (WoZ) system without relying on manual configurations or heuristics, thereby enhancing generalizability, reusability and opening up new possibilities for AR assistance.
POEM: Interactive Prompt Optimization for Enhancing Multimodal Reasoning of Large Language Models
Jun 06, 2024



Large language models (LLMs) have exhibited impressive abilities for multimodal content comprehension and reasoning with proper prompting in zero- or few-shot settings. Despite the proliferation of interactive systems developed to support prompt engineering for LLMs across various tasks, most have primarily focused on textual or visual inputs, thus neglecting the complex interplay between modalities within multimodal inputs. This oversight hinders the development of effective prompts that guide model multimodal reasoning processes by fully exploiting the rich context provided by multiple modalities. In this paper, we present POEM, a visual analytics system to facilitate efficient prompt engineering for enhancing the multimodal reasoning performance of LLMs. The system enables users to explore the interaction patterns across modalities at varying levels of detail for a comprehensive understanding of the multimodal knowledge elicited by various prompts. Through diverse recommendations of demonstration examples and instructional principles, POEM supports users in iteratively crafting and refining prompts to better align and enhance model knowledge with human insights. The effectiveness and efficiency of our system are validated through two case studies and interviews with experts.
Your Co-Workers Matter: Evaluating Collaborative Capabilities of Language Models in Blocks World
Mar 30, 2024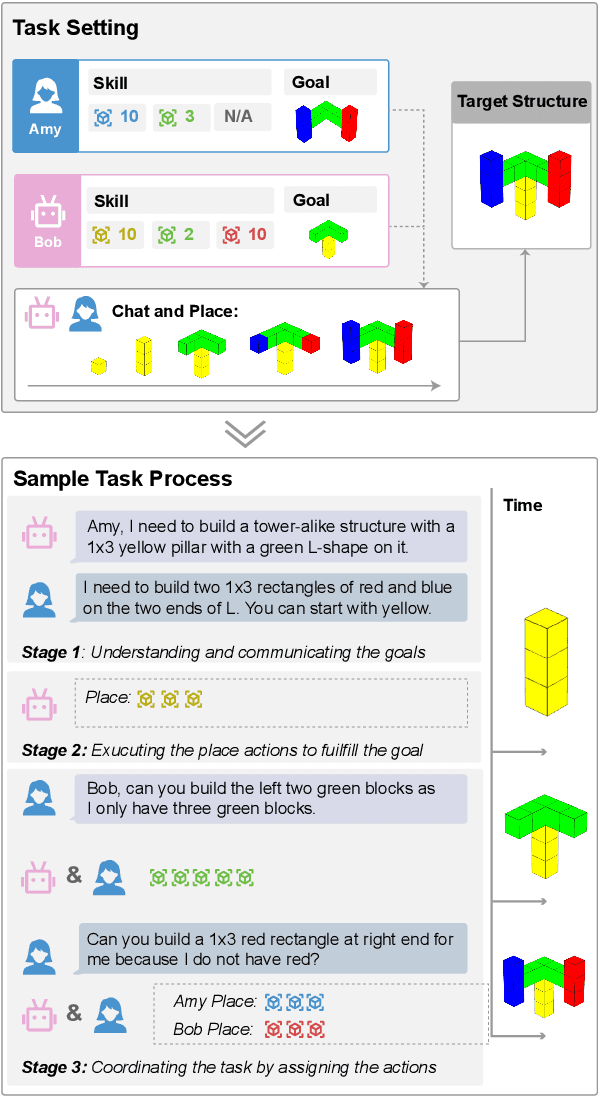

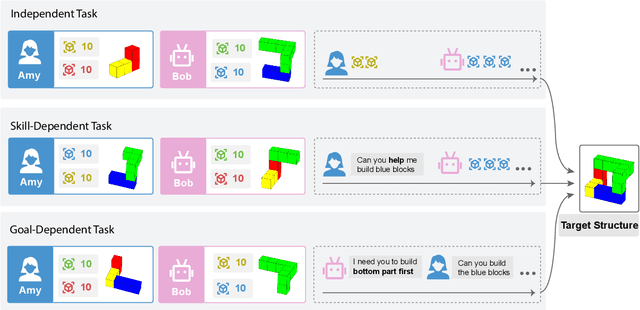

Language agents that interact with the world on their own have great potential for automating digital tasks. While large language model (LLM) agents have made progress in understanding and executing tasks such as textual games and webpage control, many real-world tasks also require collaboration with humans or other LLMs in equal roles, which involves intent understanding, task coordination, and communication. To test LLM's ability to collaborate, we design a blocks-world environment, where two agents, each having unique goals and skills, build a target structure together. To complete the goals, they can act in the world and communicate in natural language. Under this environment, we design increasingly challenging settings to evaluate different collaboration perspectives, from independent to more complex, dependent tasks. We further adopt chain-of-thought prompts that include intermediate reasoning steps to model the partner's state and identify and correct execution errors. Both human-machine and machine-machine experiments show that LLM agents have strong grounding capacities, and our approach significantly improves the evaluation metric.
ARTiST: Automated Text Simplification for Task Guidance in Augmented Reality
Feb 29, 2024
Text presented in augmented reality provides in-situ, real-time information for users. However, this content can be challenging to apprehend quickly when engaging in cognitively demanding AR tasks, especially when it is presented on a head-mounted display. We propose ARTiST, an automatic text simplification system that uses a few-shot prompt and GPT-3 models to specifically optimize the text length and semantic content for augmented reality. Developed out of a formative study that included seven users and three experts, our system combines a customized error calibration model with a few-shot prompt to integrate the syntactic, lexical, elaborative, and content simplification techniques, and generate simplified AR text for head-worn displays. Results from a 16-user empirical study showed that ARTiST lightens the cognitive load and improves performance significantly over both unmodified text and text modified via traditional methods. Our work constitutes a step towards automating the optimization of batch text data for readability and performance in augmented reality.
IntentVizor: Towards Generic Query Guided Interactive Video Summarization Using Slow-Fast Graph Convolutional Networks
Sep 30, 2021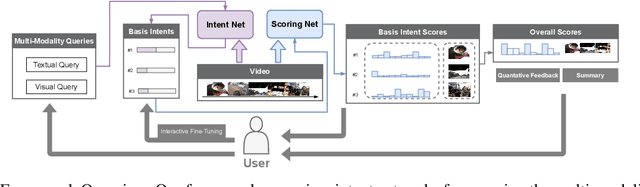
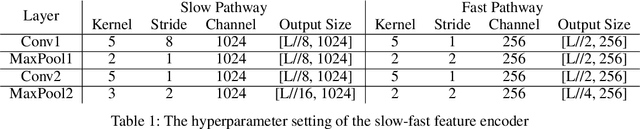
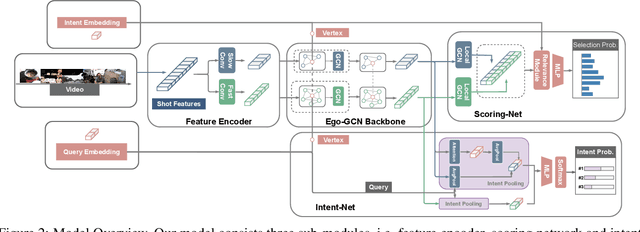
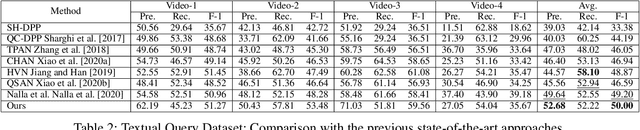
The target of automatic Video summarization is to create a short skim of the original long video while preserving the major content/events. There is a growing interest in the integration of user's queries into video summarization, or query-driven video summarization. This video summarization method predicts a concise synopsis of the original video based on the user query, which is commonly represented by the input text. However, two inherent problems exist in this query-driven way. First, the query text might not be enough to describe the exact and diverse needs of the user. Second, the user cannot edit once the summaries are produced, limiting this summarization technique's practical value. We assume the needs of the user should be subtle and need to be adjusted interactively. To solve these two problems, we propose a novel IntentVizor framework, which is an interactive video summarization framework guided by genric multi-modality queries. The input query that describes the user's needs is not limited to text but also the video snippets. We further conclude these multi-modality finer-grained queries as user `intent', which is a newly proposed concept in this paper. This intent is interpretable, interactable, and better quantifies/describes the user's needs. To be more specific, We use a set of intents to represent the inputs of users to design our new interactive visual analytic interface. Users can interactively control and adjust these mixed-initiative intents to obtain a more satisfying summary of this newly proposed interface. Also, as algorithms help users achieve their summarization goal via video understanding, we propose two novel intent/scoring networks based on the slow-fast feature for our algorithm part. We conduct our experiments on two benchmark datasets. The comparison with the state-of-the-art methods verifies the effectiveness of the proposed framework.
ERA: Entity Relationship Aware Video Summarization with Wasserstein GAN
Sep 06, 2021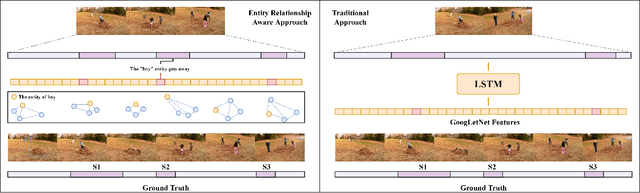
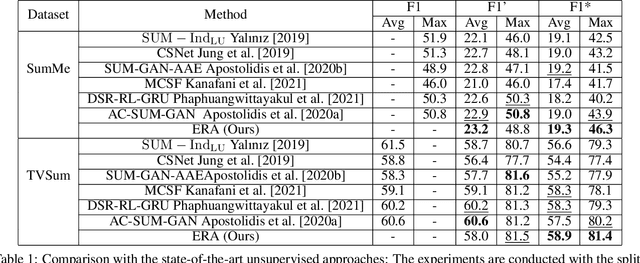
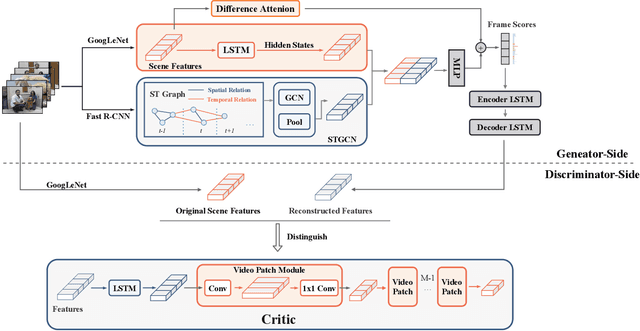

Video summarization aims to simplify large scale video browsing by generating concise, short summaries that diver from but well represent the original video. Due to the scarcity of video annotations, recent progress for video summarization concentrates on unsupervised methods, among which the GAN based methods are most prevalent. This type of methods includes a summarizer and a discriminator. The summarized video from the summarizer will be assumed as the final output, only if the video reconstructed from this summary cannot be discriminated from the original one by the discriminator. The primary problems of this GAN based methods are two folds. First, the summarized video in this way is a subset of original video with low redundancy and contains high priority events/entities. This summarization criterion is not enough. Second, the training of the GAN framework is not stable. This paper proposes a novel Entity relationship Aware video summarization method (ERA) to address the above problems. To be more specific, we introduce an Adversarial Spatio Temporal network to construct the relationship among entities, which we think should also be given high priority in the summarization. The GAN training problem is solved by introducing the Wasserstein GAN and two newly proposed video patch/score sum losses. In addition, the score sum loss can also relieve the model sensitivity to the varying video lengths, which is an inherent problem for most current video analysis tasks. Our method substantially lifts the performance on the target benchmark datasets and exceeds the current leaderboard Rank 1 state of the art CSNet (2.1% F1 score increase on TVSum and 3.1% F1 score increase on SumMe). We hope our straightforward yet effective approach will shed some light on the future research of unsupervised video summarization.