 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Context Augmentation from Contrastive Learning of Experience via Agentic Reflection
Apr 08, 2026Large language model agents rely on effective model context to obtain task-relevant information for decision-making. Many existing context engineering approaches primarily rely on the context generated from the past experience and retrieval mechanisms that reuse these context. However, retrieved context from past tasks must be adapted by the execution agent to fit new situations, placing additional reasoning burden on the underlying LLM. To address this limitation, we propose a generative context augmentation framework using Contrastive Learning of Experience via Agentic Reflection (CLEAR). CLEAR first employs a reflection agent to perform contrastive analysis over past execution trajectories and summarize useful context for each observed task. These summaries are then used as supervised fine-tuning data to train a context augmentation model (CAM). Then we further optimize CAM using reinforcement learning, where the reward signal is obtained by running the task execution agent. By learning to generate task-specific knowledge rather than retrieve knowledge from the past, CAM produces context that is better tailored to the current task. We conduct comprehensive evaluations on the AppWorld and WebShop benchmarks. Experimental results show that CLEAR consistently outperforms strong baselines. It improves task completion rate from 72.62% to 81.15% on AppWorld test set and averaged reward from 0.68 to 0.74 on a subset of WebShop, compared with baseline agent. Our code is publicly available at https://github.com/awslabs/CLEAR.
Reinforcement Learning for Self-Improving Agent with Skill Library
Dec 18, 2025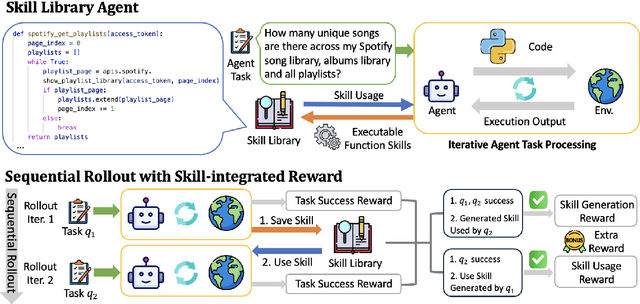
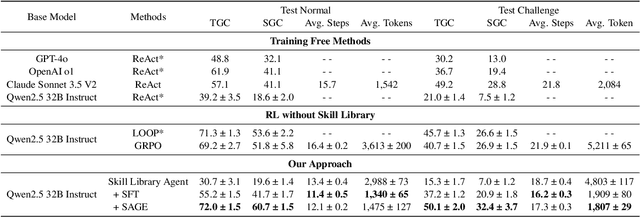
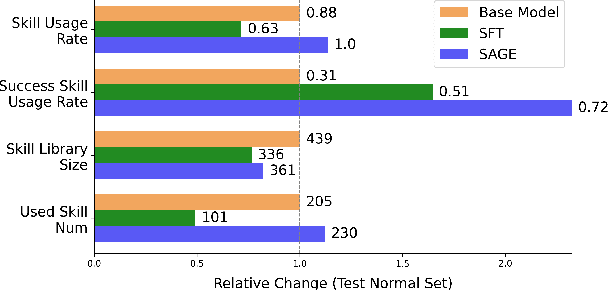
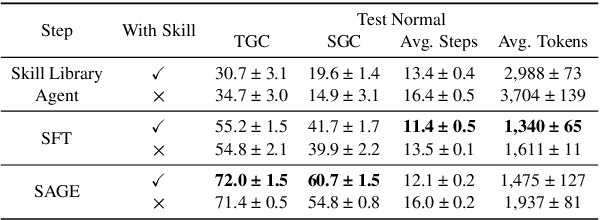
Large Language Model (LLM)-based agents have demonstrated remarkable capabilities in complex reasoning and multi-turn interactions but struggle to continuously improve and adapt when deployed in new environments. One promising approach is implementing skill libraries that allow agents to learn, validate, and apply new skills. However, current skill library approaches rely primarily on LLM prompting, making consistent skill library implementation challenging. To overcome these challenges, we propose a Reinforcement Learning (RL)-based approach to enhance agents' self-improvement capabilities with a skill library. Specifically, we introduce Skill Augmented GRPO for self-Evolution (SAGE), a novel RL framework that systematically incorporates skills into learning. The framework's key component, Sequential Rollout, iteratively deploys agents across a chain of similar tasks for each rollout. As agents navigate through the task chain, skills generated from previous tasks accumulate in the library and become available for subsequent tasks. Additionally, the framework enhances skill generation and utilization through a Skill-integrated Reward that complements the original outcome-based rewards. Experimental results on AppWorld demonstrate that SAGE, when applied to supervised-finetuned model with expert experience, achieves 8.9% higher Scenario Goal Completion while requiring 26% fewer interaction steps and generating 59% fewer tokens, substantially outperforming existing approaches in both accuracy and efficiency.
Collaborative LLM Numerical Reasoning with Local Data Protection
Apr 01, 2025Numerical reasoning over documents, which demands both contextual understanding and logical inference, is challenging for low-capacity local models deployed on computation-constrained devices. Although such complex reasoning queries could be routed to powerful remote models like GPT-4, exposing local data raises significant data leakage concerns. Existing mitigation methods generate problem descriptions or examples for remote assistance. However, the inherent complexity of numerical reasoning hinders the local model from generating logically equivalent queries and accurately inferring answers with remote guidance. In this paper, we present a model collaboration framework with two key innovations: (1) a context-aware synthesis strategy that shifts the query domains while preserving logical consistency; and (2) a tool-based answer reconstruction approach that reuses the remote-generated problem-solving pattern with code snippets. Experimental results demonstrate that our method achieves better reasoning accuracy than solely using local models while providing stronger data protection than fully relying on remote models. Furthermore, our method improves accuracy by 16.2% - 43.6% while reducing data leakage by 2.3% - 44.6% compared to existing data protection approaches.
Enhancing Multi-hop Reasoning in Vision-Language Models via Self-Distillation with Multi-Prompt Ensembling
Mar 03, 2025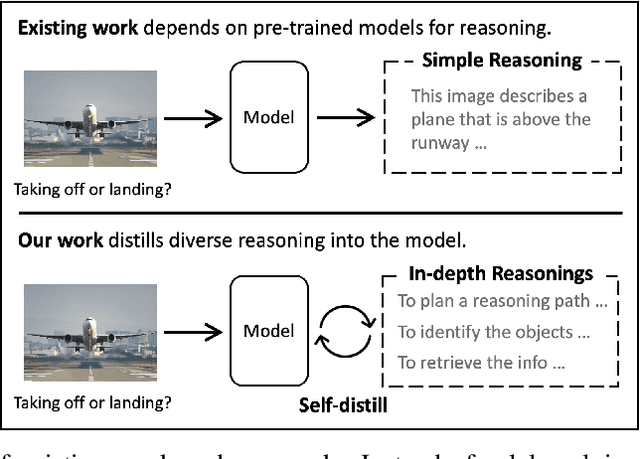

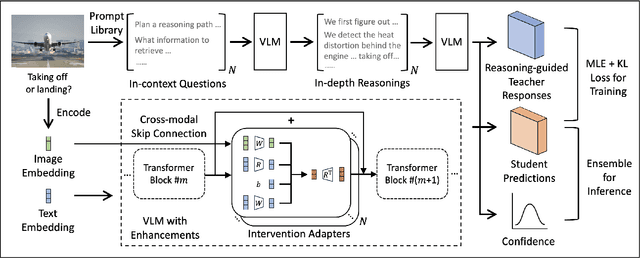

Multi-modal large language models have seen rapid advancement alongside large language models. However, while language models can effectively leverage chain-of-thought prompting for zero or few-shot learning, similar prompting strategies are less effective for multi-modal LLMs due to modality gaps and task complexity. To address this challenge, we explore two prompting approaches: a dual-query method that separates multi-modal input analysis and answer generation into two prompting steps, and an ensemble prompting method that combines multiple prompt variations to arrive at the final answer. Although these approaches enhance the model's reasoning capabilities without fine-tuning, they introduce significant inference overhead. Therefore, building on top of these two prompting techniques, we propose a self-distillation framework such that the model can improve itself without any annotated data. Our self-distillation framework learns representation intervention modules from the reasoning traces collected from ensembled dual-query prompts, in the form of hidden representations. The lightweight intervention modules operate in parallel with the frozen original model, which makes it possible to maintain computational efficiency while significantly improving model capability. We evaluate our method on five widely-used VQA benchmarks, demonstrating its effectiveness in performing multi-hop reasoning for complex tasks.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
VL-Cache: Sparsity and Modality-Aware KV Cache Compression for Vision-Language Model Inference Acceleration
Oct 29, 2024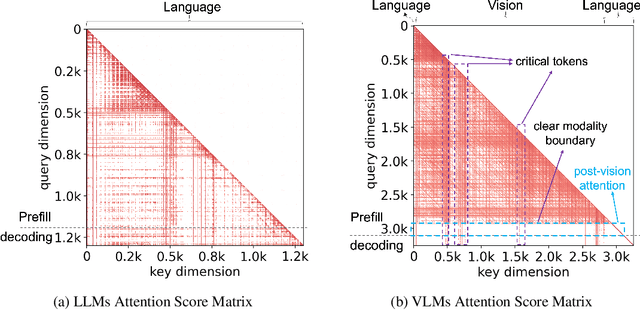

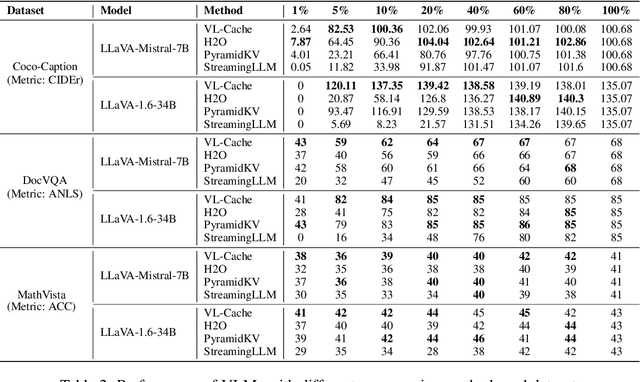
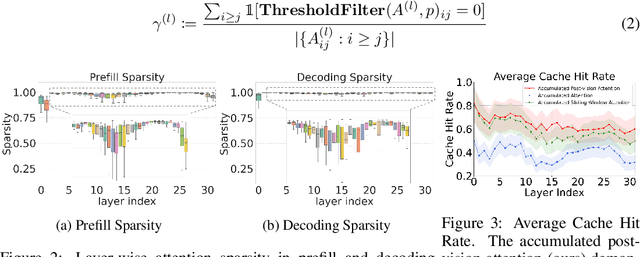
Vision-Language Models (VLMs) have demonstrated impressive performance across a versatile set of tasks. A key challenge in accelerating VLMs is storing and accessing the large Key-Value (KV) cache that encodes long visual contexts, such as images or videos. While existing KV cache compression methods are effective for Large Language Models (LLMs), directly migrating them to VLMs yields suboptimal accuracy and speedup. To bridge the gap, we propose VL-Cache, a novel KV cache compression recipe tailored for accelerating VLM inference. In this paper, we first investigate the unique sparsity pattern of VLM attention by distinguishing visual and text tokens in prefill and decoding phases. Based on these observations, we introduce a layer-adaptive sparsity-aware cache budget allocation method that effectively distributes the limited cache budget across different layers, further reducing KV cache size without compromising accuracy. Additionally, we develop a modality-aware token scoring policy to better evaluate the token importance. Empirical results on multiple benchmark datasets demonstrate that retaining only 10% of KV cache achieves accuracy comparable to that with full cache. In a speed benchmark, our method accelerates end-to-end latency of generating 100 tokens by up to 2.33x and speeds up decoding by up to 7.08x, while reducing the memory footprint of KV cache in GPU by 90%.
Customize Your Own Paired Data via Few-shot Way
May 21, 2024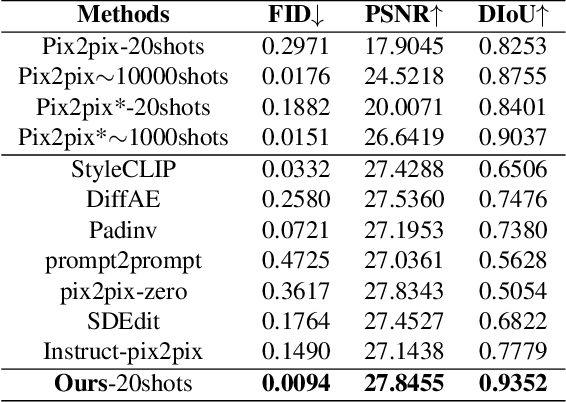
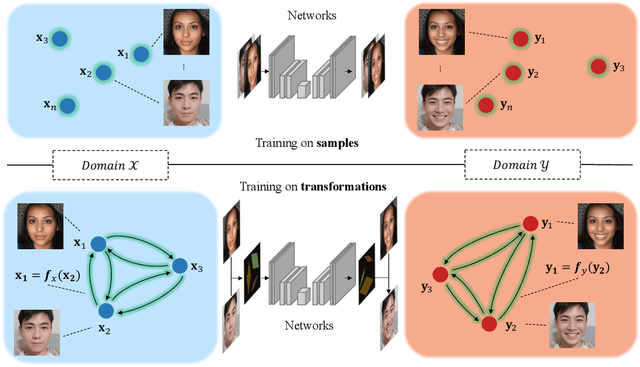
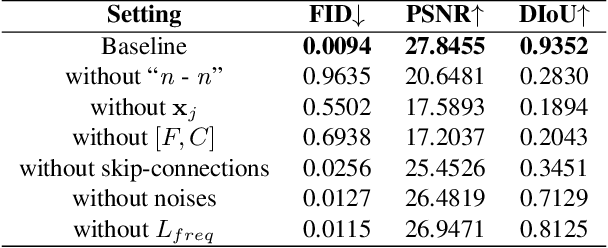
Existing solutions to image editing tasks suffer from several issues. Though achieving remarkably satisfying generated results, some supervised methods require huge amounts of paired training data, which greatly limits their usages. The other unsupervised methods take full advantage of large-scale pre-trained priors, thus being strictly restricted to the domains where the priors are trained on and behaving badly in out-of-distribution cases. The task we focus on is how to enable the users to customize their desired effects through only few image pairs. In our proposed framework, a novel few-shot learning mechanism based on the directional transformations among samples is introduced and expands the learnable space exponentially. Adopting a diffusion model pipeline, we redesign the condition calculating modules in our model and apply several technical improvements. Experimental results demonstrate the capabilities of our method in various cases.
Efficient generation of realistic guided wave signals for reliability estimation
Mar 25, 2024



Across non-destructive testing (NDT) and structural health monitoring (SHM), accurate knowledge of the systems' reliability for detecting defects, such as Probability of Detection (POD) analysis is essential to enabling widespread adoption. Traditionally this relies on access to extensive experimental data to cover all critical areas of the parametric space, which becomes expensive, and heavily undermines the benefit such systems bring. In response to these challenges, reliability estimation based on numerical simulation emerges as a practical solution, offering enhanced efficiency and cost-effectiveness. Nevertheless, precise reliability estimation demands that the simulated data faithfully represents the real-world performance. In this context, a numerical framework tailored to generate realistic signals for reliability estimation purposes is presented here, focusing on the application of guided wave SHM for pipe monitoring. It specifically incorporates key characteristics of real signals: random noise and coherent noise caused by the imbalance in transducer performance within guided wave monitoring systems. The effectiveness of our proposed methodology is demonstrated through a comprehensive comparative analysis between simulation-generated signals and experimental signals both individually and statistically. Furthermore, to assess the reliability of a guided wave system in terms of the inspection range for pipe monitoring, a series of POD analyses using simulation-generated data were conducted. The comparison of POD curves derived from ideal and realistic simulation data underscores the necessity of considering coherent noise for accurate POD curve calculations. Moreover, the POD analysis based on realistic simulation-generated data provides a quantitative estimation of the inspection range with more details compared to the current industry practice.
Effectively Fine-tune to Improve Large Multimodal Models for Radiology Report Generation
Dec 03, 2023
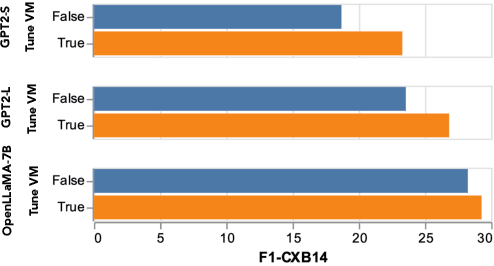
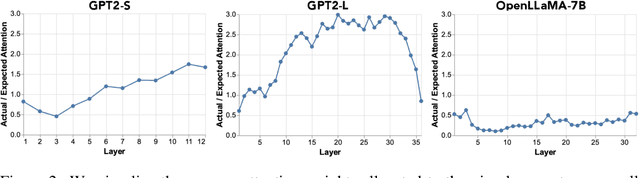
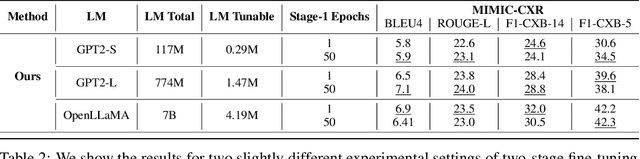
Writing radiology reports from medical images requires a high level of domain expertise. It is time-consuming even for trained radiologists and can be error-prone for inexperienced radiologists. It would be appealing to automate this task by leveraging generative AI, which has shown drastic progress in vision and language understanding. In particular, Large Language Models (LLM) have demonstrated impressive capabilities recently and continued to set new state-of-the-art performance on almost all natural language tasks. While many have proposed architectures to combine vision models with LLMs for multimodal tasks, few have explored practical fine-tuning strategies. In this work, we proposed a simple yet effective two-stage fine-tuning protocol to align visual features to LLM's text embedding space as soft visual prompts. Our framework with OpenLLaMA-7B achieved state-of-the-art level performance without domain-specific pretraining. Moreover, we provide detailed analyses of soft visual prompts and attention mechanisms, shedding light on future research directions.
Graph Neural Prompting with Large Language Models
Sep 27, 2023
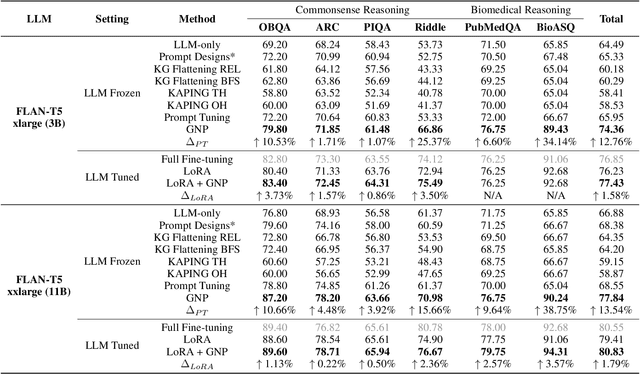
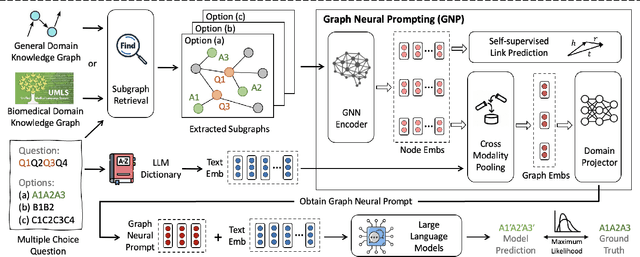
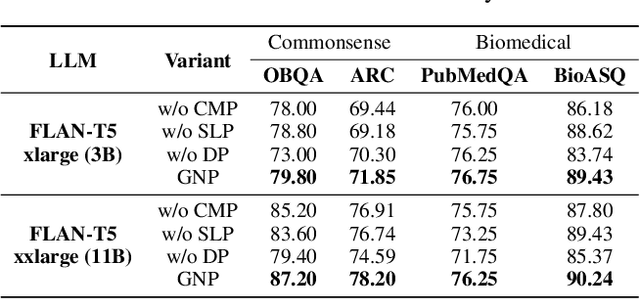
Large Language Models (LLMs) have shown remarkable generalization capability with exceptional performance in various language modeling tasks. However, they still exhibit inherent limitations in precisely capturing and returning grounded knowledge. While existing work has explored utilizing knowledge graphs to enhance language modeling via joint training and customized model architectures, applying this to LLMs is problematic owing to their large number of parameters and high computational cost. In addition, how to leverage the pre-trained LLMs and avoid training a customized model from scratch remains an open question. In this work, we propose Graph Neural Prompting (GNP), a novel plug-and-play method to assist pre-trained LLMs in learning beneficial knowledge from KGs. GNP encompasses various designs, including a standard graph neural network encoder, a cross-modality pooling module, a domain projector, and a self-supervised link prediction objective. Extensive experiments on multiple datasets demonstrate the superiority of GNP on both commonsense and biomedical reasoning tasks across different LLM sizes and settings.