 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Orchestrated Self-verification and Cross-path Refinement
Apr 02, 2026Diffusion language models (DLMs) expose their denoising trajectories, offering a natural handle for inference-time control; accordingly, an ideal hallucination mitigation framework should intervene during generation using this model-native signal rather than relying on an externally trained hallucination classifier. Toward this, we formulate commitment uncertainty localization: given a denoising trajectory, identify token positions whose cross-chain entropy exceeds an unsupervised threshold before factually unreliable commitments propagate into self-consistent but incorrect outputs. We introduce a suite of trajectory-level assessments, including a cross-chain divergence-at-hallucination (CDH) metric, for principled comparison of localization methods. We also introduce OSCAR, a training-free inference-time framework operationalizing this formulation. OSCAR runs N parallel denoising chains with randomized reveal orders, computes cross-chain Shannon entropy to detect high-uncertainty positions, and then performs targeted remasking conditioned on retrieved evidence. Ablations confirm that localization and correction contribute complementary gains, robust across N in {4, 8, 16}. On TriviaQA, HotpotQA, RAGTruth, and CommonsenseQA using LLaDA-8B and Dream-7B, OSCAR enhances generation quality by significantly reducing hallucinated content and improving factual accuracy through uncertainty-guided remasking, which also facilitates more effective integration of retrieved evidence. Its native entropy-based uncertainty signal surpasses that of specialized trained detectors, highlighting an inherent capacity of diffusion language models to identify factual uncertainty that is not present in the sequential token commitment structure of autoregressive models. We are releasing the codebase1 to support future research on localization and uncertainty-aware generation in DLMs.
Synapse Compendium Aware Federated Knowledge Exchange for Tool Routed LLMs
Jan 31, 2026Collaborative learning among LLM-based agents under federated learning faces challenges, including communication costs, heterogeneity in data, and tool-usage, limiting their effectiveness. We introduce Synapse, a framework that trains a shared global knowledge model of tool-usage behavior. Client agents with fixed LLMs learn tool-usage patterns locally, and transmit artifacts for federated aggregation through coordinators. A global tool compendium is updated and redistributed, enabling convergence toward stable tool selection. Synapse uses templated representations, embedding retrieval with LLM reranking, and adaptive masking to maintain utility while limiting information leakage. The framework supports heterogeneous data and quantifies performance improvements. Results show that Synapse improves tool-usage effectiveness and reduces communication overhead compared with weight or prompt-sharing approaches in multi-agent LLM systems.
DoPE: Decoy Oriented Perturbation Encapsulation Human-Readable, AI-Hostile Documents for Academic Integrity
Jan 18, 2026Multimodal Large Language Models (MLLMs) can directly consume exam documents, threatening conventional assessments and academic integrity. We present DoPE (Decoy-Oriented Perturbation Encapsulation), a document-layer defense framework that embeds semantic decoys into PDF/HTML assessments to exploit render-parse discrepancies in MLLM pipelines. By instrumenting exams at authoring time, DoPE provides model-agnostic prevention (stop or confound automated solving) and detection (flag blind AI reliance) without relying on conventional one-shot classifiers. We formalize prevention and detection tasks, and introduce FewSoRT-Q, an LLM-guided pipeline that generates question-level semantic decoys and FewSoRT-D to encapsulate them into watermarked documents. We evaluate on Integrity-Bench, a novel benchmark of 1826 exams (PDF+HTML) derived from public QA datasets and OpenCourseWare. Against black-box MLLMs from OpenAI and Anthropic, DoPE yields strong empirical gains: a 91.4% detection rate at an 8.7% false-positive rate using an LLM-as-Judge verifier, and prevents successful completion or induces decoy-aligned failures in 96.3% of attempts. We release Integrity-Bench, our toolkit, and evaluation code to enable reproducible study of document-layer defenses for academic integrity.
Integrity Shield A System for Ethical AI Use & Authorship Transparency in Assessments
Jan 16, 2026Large Language Models (LLMs) can now solve entire exams directly from uploaded PDF assessments, raising urgent concerns about academic integrity and the reliability of grades and credentials. Existing watermarking techniques either operate at the token level or assume control over the model's decoding process, making them ineffective when students query proprietary black-box systems with instructor-provided documents. We present Integrity Shield, a document-layer watermarking system that embeds schema-aware, item-level watermarks into assessment PDFs while keeping their human-visible appearance unchanged. These watermarks consistently prevent MLLMs from answering shielded exam PDFs and encode stable, item-level signatures that can be reliably recovered from model or student responses. Across 30 exams spanning STEM, humanities, and medical reasoning, Integrity Shield achieves exceptionally high prevention (91-94% exam-level blocking) and strong detection reliability (89-93% signature retrieval) across four commercial MLLMs. Our demo showcases an interactive interface where instructors upload an exam, preview watermark behavior, and inspect pre/post AI performance & authorship evidence.
Learning Resilient Elections with Adversarial GNNs
Jan 04, 2026In the face of adverse motives, it is indispensable to achieve a consensus. Elections have been the canonical way by which modern democracy has operated since the 17th century. Nowadays, they regulate markets, provide an engine for modern recommender systems or peer-to-peer networks, and remain the main approach to represent democracy. However, a desirable universal voting rule that satisfies all hypothetical scenarios is still a challenging topic, and the design of these systems is at the forefront of mechanism design research. Automated mechanism design is a promising approach, and recent works have demonstrated that set-invariant architectures are uniquely suited to modelling electoral systems. However, various concerns prevent the direct application to real-world settings, such as robustness to strategic voting. In this paper, we generalise the expressive capability of learned voting rules, and combine improvements in neural network architecture with adversarial training to improve the resilience of voting rules while maximizing social welfare. We evaluate the effectiveness of our methods on both synthetic and real-world datasets. Our method resolves critical limitations of prior work regarding learning voting rules by representing elections using bipartite graphs, and learning such voting rules using graph neural networks. We believe this opens new frontiers for applying machine learning to real-world elections.
Effectively Fine-tune to Improve Large Multimodal Models for Radiology Report Generation
Dec 03, 2023
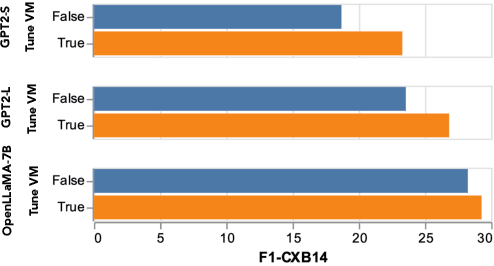
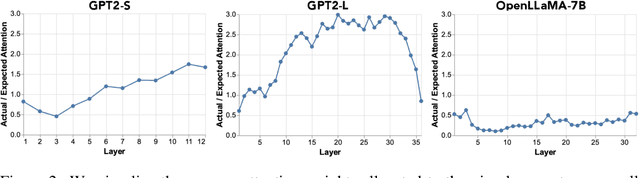
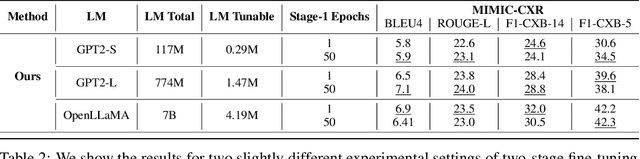
Writing radiology reports from medical images requires a high level of domain expertise. It is time-consuming even for trained radiologists and can be error-prone for inexperienced radiologists. It would be appealing to automate this task by leveraging generative AI, which has shown drastic progress in vision and language understanding. In particular, Large Language Models (LLM) have demonstrated impressive capabilities recently and continued to set new state-of-the-art performance on almost all natural language tasks. While many have proposed architectures to combine vision models with LLMs for multimodal tasks, few have explored practical fine-tuning strategies. In this work, we proposed a simple yet effective two-stage fine-tuning protocol to align visual features to LLM's text embedding space as soft visual prompts. Our framework with OpenLLaMA-7B achieved state-of-the-art level performance without domain-specific pretraining. Moreover, we provide detailed analyses of soft visual prompts and attention mechanisms, shedding light on future research directions.
App for Resume-Based Job Matching with Speech Interviews and Grammar Analysis: A Review
Nov 20, 2023Through the advancement in natural language processing (NLP), specifically in speech recognition, fully automated complex systems functioning on voice input have started proliferating in areas such as home automation. These systems have been termed Automatic Speech Recognition Systems (ASR). In this review paper, we explore the feasibility of an end-to-end system providing speech and text based natural language processing for job interview preparation as well as recommendation of relevant job postings. We also explore existing recommender-based systems and note their limitations. This literature review would help us identify the approaches and limitations of the various similar use-cases of NLP technology for our upcoming project.
Real-time Recognition of Yoga Poses using computer Vision for Smart Health Care
Jan 19, 2022Nowadays, yoga has become a part of life for many people. Exercises and sports technological assistance is implemented in yoga pose identification. In this work, a self-assistance based yoga posture identification technique is developed, which helps users to perform Yoga with the correction feature in Real-time. The work also presents Yoga-hand mudra (hand gestures) identification. The YOGI dataset has been developed which include 10 Yoga postures with around 400-900 images of each pose and also contain 5 mudras for identification of mudras postures. It contains around 500 images of each mudra. The feature has been extracted by making a skeleton on the body for yoga poses and hand for mudra poses. Two different algorithms have been used for creating a skeleton one for yoga poses and the second for hand mudras. Angles of the joints have been extracted as a features for different machine learning and deep learning models. among all the models XGBoost with RandomSearch CV is most accurate and gives 99.2\% accuracy. The complete design framework is described in the present paper.
Stem-driven Language Models for Morphologically Rich Languages
Oct 25, 2019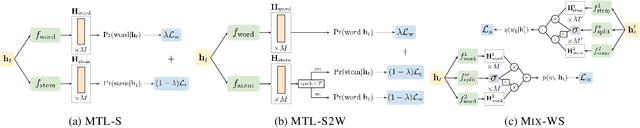
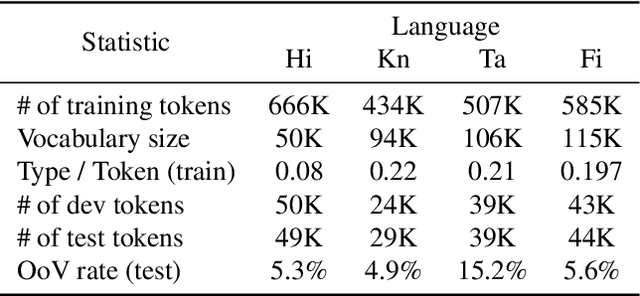
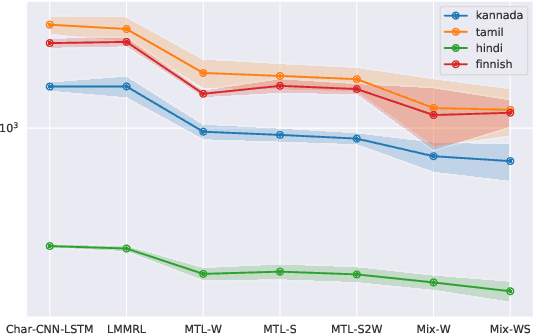
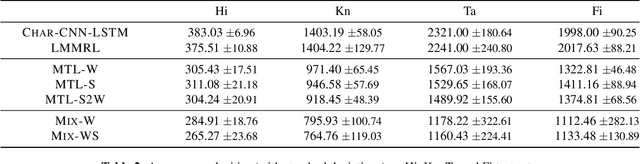
Neural language models (LMs) have shown to benefit significantly from enhancing word vectors with subword-level information, especially for morphologically rich languages. This has been mainly tackled by providing subword-level information as an input; using subword units in the output layer has been far less explored. In this work, we propose LMs that are cognizant of the underlying stems in each word. We derive stems for words using a simple unsupervised technique for stem identification. We experiment with different architectures involving multi-task learning and mixture models over words and stems. We focus on four morphologically complex languages -- Hindi, Tamil, Kannada and Finnish -- and observe significant perplexity gains with using our stem-driven LMs when compared with other competitive baseline models.