 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoNLI: An Extensible Framework for Testing Diverse Logical Reasoning Capabilities for NLI
Dec 04, 2021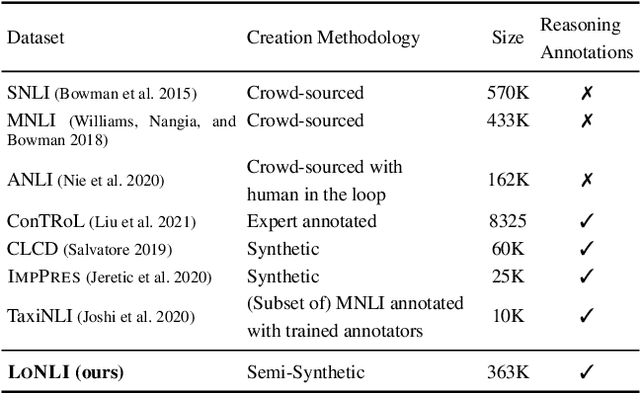
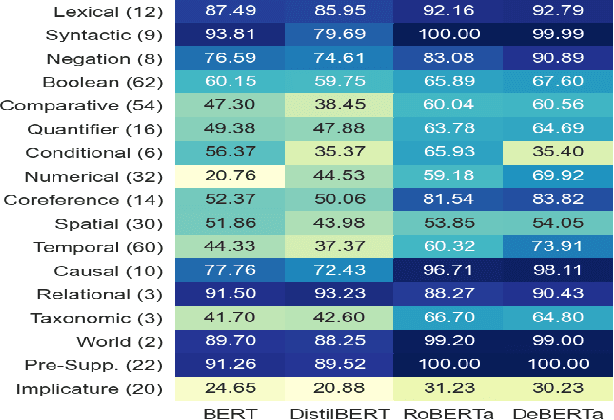

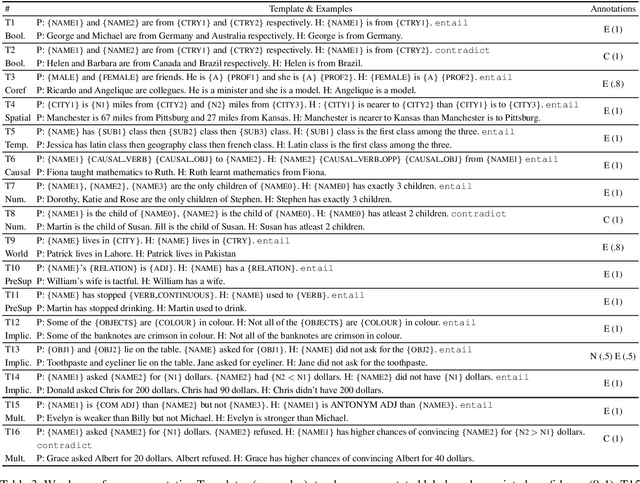
Natural Language Inference (NLI) is considered a representative task to test natural language understanding (NLU). In this work, we propose an extensible framework to collectively yet categorically test diverse Logical reasoning capabilities required for NLI (and by extension, NLU). Motivated by behavioral testing, we create a semi-synthetic large test-bench (363 templates, 363k examples) and an associated framework that offers following utilities: 1) individually test and analyze reasoning capabilities along 17 reasoning dimensions (including pragmatic reasoning), 2) design experiments to study cross-capability information content (leave one out or bring one in); and 3) the synthetic nature enable us to control for artifacts and biases. The inherited power of automated test case instantiation from free-form natural language templates (using CheckList), and a well-defined taxonomy of capabilities enable us to extend to (cognitively) harder test cases while varying the complexity of natural language. Through our analysis of state-of-the-art NLI systems, we observe that our benchmark is indeed hard (and non-trivial even with training on additional resources). Some capabilities stand out as harder. Further fine-grained analysis and fine-tuning experiments reveal more insights about these capabilities and the models -- supporting and extending previous observations. Towards the end we also perform an user-study, to investigate whether behavioral information can be utilised to generalize much better for some models compared to others.
Trusting RoBERTa over BERT: Insights from CheckListing the Natural Language Inference Task
Jul 15, 2021
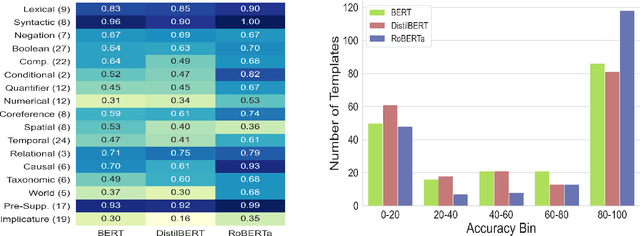

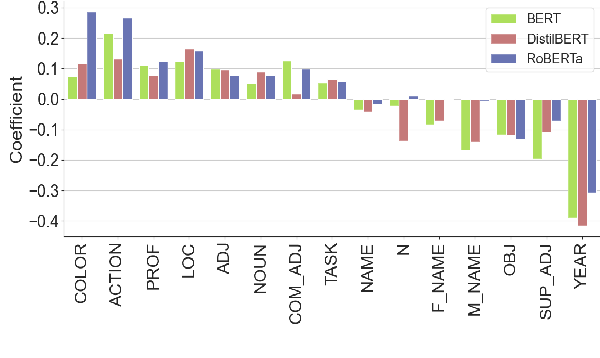
The recent state-of-the-art natural language understanding (NLU) systems often behave unpredictably, failing on simpler reasoning examples. Despite this, there has been limited focus on quantifying progress towards systems with more predictable behavior. We think that reasoning capability-wise behavioral summary is a step towards bridging this gap. We create a CheckList test-suite (184K examples) for the Natural Language Inference (NLI) task, a representative NLU task. We benchmark state-of-the-art NLI systems on this test-suite, which reveals fine-grained insights into the reasoning abilities of BERT and RoBERTa. Our analysis further reveals inconsistencies of the models on examples derived from the same template or distinct templates but pertaining to same reasoning capability, indicating that generalizing the models' behavior through observations made on a CheckList is non-trivial. Through an user-study, we find that users were able to utilize behavioral information to generalize much better for examples predicted from RoBERTa, compared to that of BERT.
From Machine Translation to Code-Switching: Generating High-Quality Code-Switched Text
Jul 14, 2021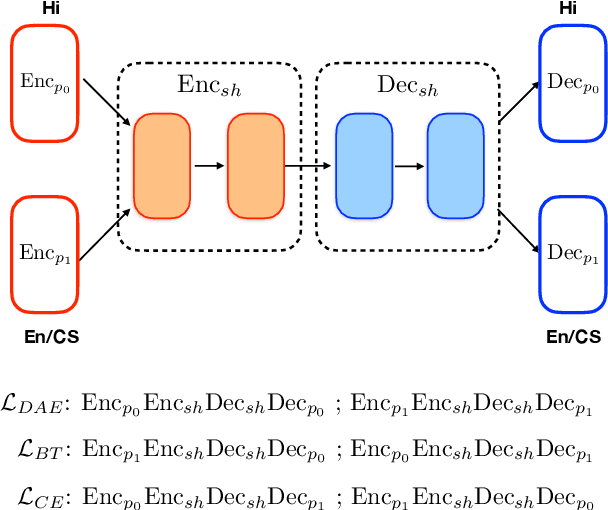


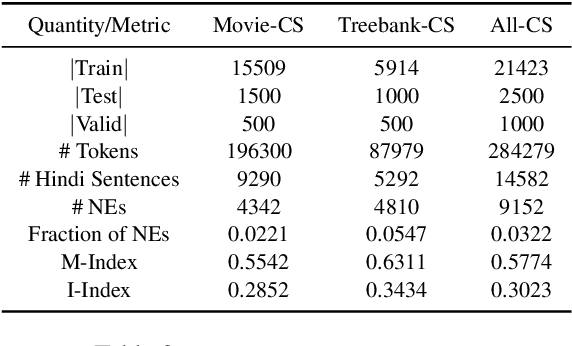
Generating code-switched text is a problem of growing interest, especially given the scarcity of corpora containing large volumes of real code-switched text. In this work, we adapt a state-of-the-art neural machine translation model to generate Hindi-English code-switched sentences starting from monolingual Hindi sentences. We outline a carefully designed curriculum of pretraining steps, including the use of synthetic code-switched text, that enable the model to generate high-quality code-switched text. Using text generated from our model as data augmentation, we show significant reductions in perplexity on a language modeling task, compared to using text from other generative models of CS text. We also show improvements using our text for a downstream code-switched natural language inference task. Our generated text is further subjected to a rigorous evaluation using a human evaluation study and a range of objective metrics, where we show performance comparable (and sometimes even superior) to code-switched text obtained via crowd workers who are native Hindi speakers.
Meta-Learning for Effective Multi-task and Multilingual Modelling
Jan 27, 2021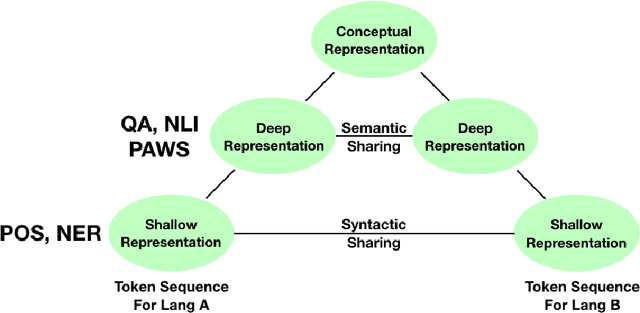
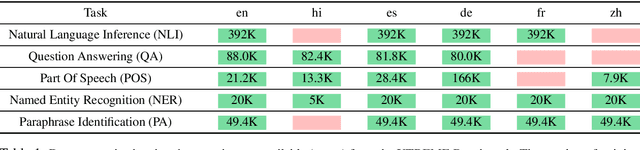
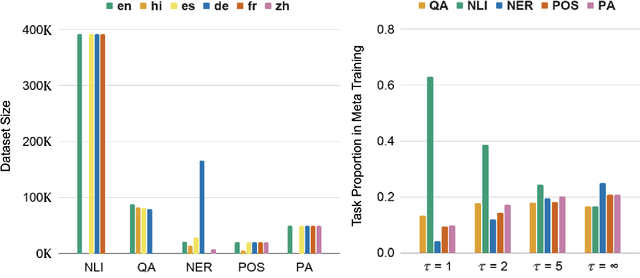
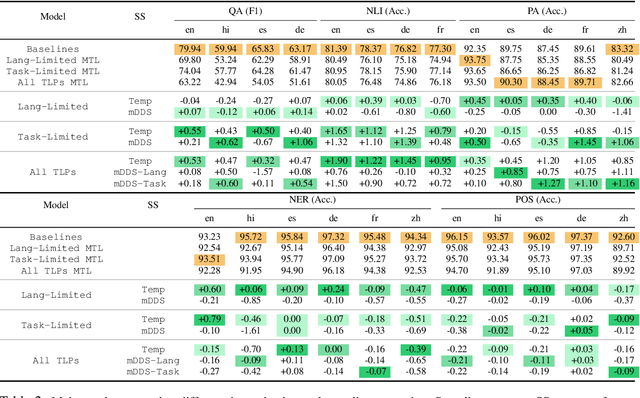
Natural language processing (NLP) tasks (e.g. question-answering in English) benefit from knowledge of other tasks (e.g. named entity recognition in English) and knowledge of other languages (e.g. question-answering in Spanish). Such shared representations are typically learned in isolation, either across tasks or across languages. In this work, we propose a meta-learning approach to learn the interactions between both tasks and languages. We also investigate the role of different sampling strategies used during meta-learning. We present experiments on five different tasks and six different languages from the XTREME multilingual benchmark dataset. Our meta-learned model clearly improves in performance compared to competitive baseline models that also include multi-task baselines. We also present zero-shot evaluations on unseen target languages to demonstrate the utility of our proposed model.
Stem-driven Language Models for Morphologically Rich Languages
Oct 25, 2019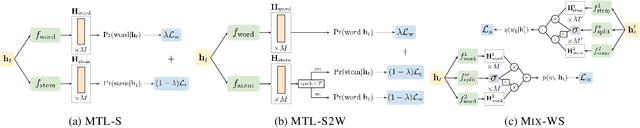
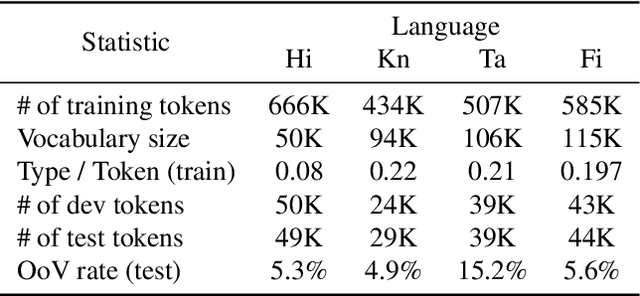
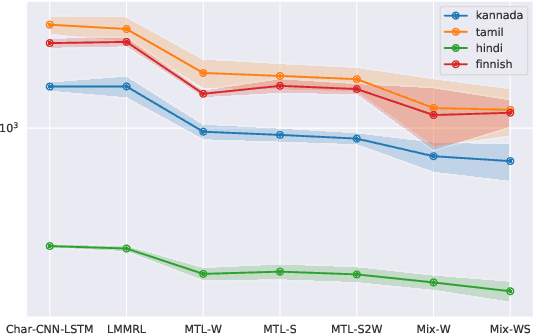
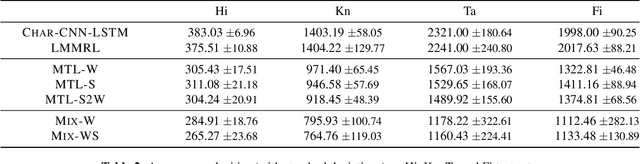
Neural language models (LMs) have shown to benefit significantly from enhancing word vectors with subword-level information, especially for morphologically rich languages. This has been mainly tackled by providing subword-level information as an input; using subword units in the output layer has been far less explored. In this work, we propose LMs that are cognizant of the underlying stems in each word. We derive stems for words using a simple unsupervised technique for stem identification. We experiment with different architectures involving multi-task learning and mixture models over words and stems. We focus on four morphologically complex languages -- Hindi, Tamil, Kannada and Finnish -- and observe significant perplexity gains with using our stem-driven LMs when compared with other competitive baseline models.