 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusting RoBERTa over BERT: Insights from CheckListing the Natural Language Inference Task
Paper and Code

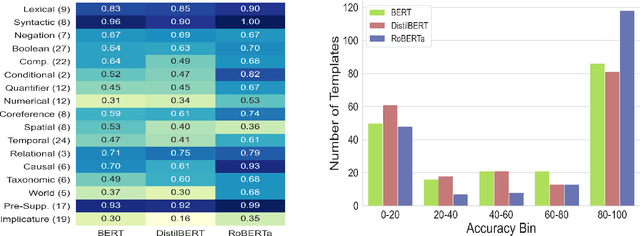

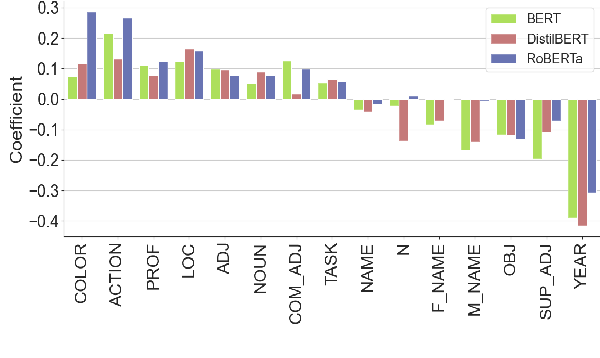
The recent state-of-the-art natural language understanding (NLU) systems often behave unpredictably, failing on simpler reasoning examples. Despite this, there has been limited focus on quantifying progress towards systems with more predictable behavior. We think that reasoning capability-wise behavioral summary is a step towards bridging this gap. We create a CheckList test-suite (184K examples) for the Natural Language Inference (NLI) task, a representative NLU task. We benchmark state-of-the-art NLI systems on this test-suite, which reveals fine-grained insights into the reasoning abilities of BERT and RoBERTa. Our analysis further reveals inconsistencies of the models on examples derived from the same template or distinct templates but pertaining to same reasoning capability, indicating that generalizing the models' behavior through observations made on a CheckList is non-trivial. Through an user-study, we find that users were able to utilize behavioral information to generalize much better for examples predicted from RoBERTa, compared to that of BERT.