 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCRASP: Multimodal Chain-of-thought Reasoning aware Structured Pruning
May 25, 2026Vision-language models (VLMs) increasingly rely on chain-of-thought (CoT) reasoning to solve complex multimodal tasks, but their large parameter sizes make deployment expensive. Structured pruning offers a natural solution; however, existing methods fail to preserve CoT reasoning accuracy in VLMs. We identify two key reasons: (1) CoT consistency depends on sparse transition points (pivot tokens) in the generation trajectory, while existing pruning methods are CoT-agnostic; and (2) pruning methods designed for unimodal LLMs do not account for activation-distribution differences across visual and textual modalities. Motivated by these observations, we propose MuCRASP, a structured pruning framework that targets reasoning-critical components while preserving cross-modal alignment and accounting for layer-wise sensitivity under a global parameter budget. Experiments on four VLMs across three reasoning benchmarks show that MuCRASP consistently preserves reasoning quality under increasing compression. At 30% pruning on Qwen2.5-VL-7B, MuCRASP achieves an LLM-as-a-Judge score of 8.87 versus 7.32 for the strongest baseline on physical reasoning tasks. Furthermore, MuCRASP maintains high reasoning consistency up to 50% pruning, significantly outperforming prior pruning approaches while exhibiting lower perplexity degradation.
AD$^2$: Analysis and Detection of Adversarial Threats in Visual Perception for End-to-End Autonomous Driving Systems
Feb 10, 2026End-to-end autonomous driving systems have achieved significant progress, yet their adversarial robustness remains largely underexplored. In this work, we conduct a closed-loop evaluation of state-of-the-art autonomous driving agents under black-box adversarial threat models in CARLA. Specifically, we consider three representative attack vectors on the visual perception pipeline: (i) a physics-based blur attack induced by acoustic waves, (ii) an electromagnetic interference attack that distorts captured images, and (iii) a digital attack that adds ghost objects as carefully crafted bounded perturbations on images. Our experiments on two advanced agents, Transfuser and Interfuser, reveal severe vulnerabilities to such attacks, with driving scores dropping by up to 99% in the worst case, raising valid safety concerns. To help mitigate such threats, we further propose a lightweight Attack Detection model for Autonomous Driving systems (AD$^2$) based on attention mechanisms that capture spatial-temporal consistency. Comprehensive experiments across multi-camera inputs on CARLA show that our detector achieves superior detection capability and computational efficiency compared to existing approaches.
PragWorld: A Benchmark Evaluating LLMs' Local World Model under Minimal Linguistic Alterations and Conversational Dynamics
Nov 17, 2025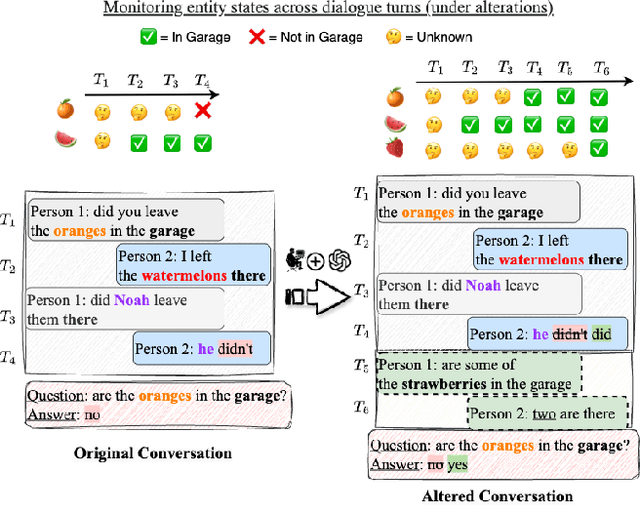
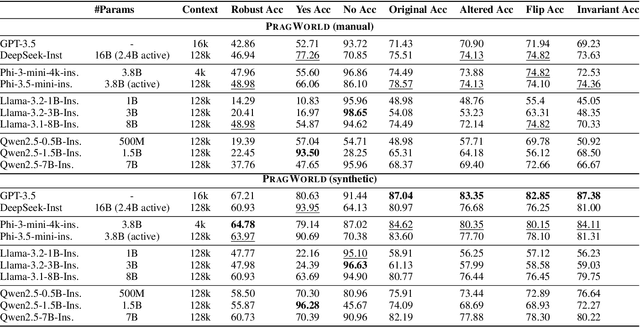
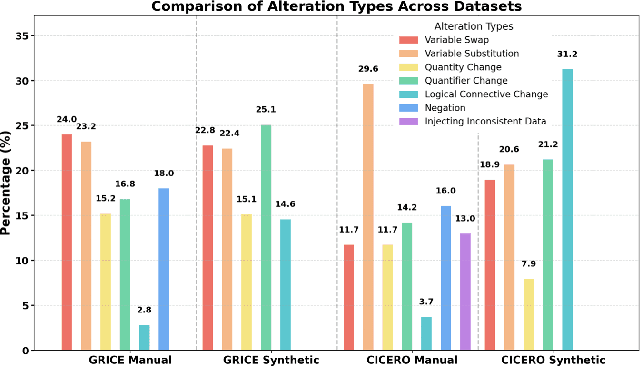
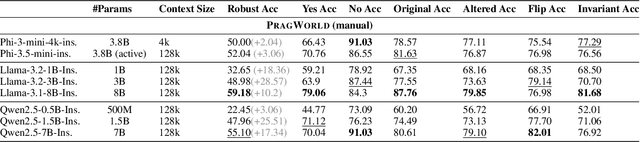
Real-world conversations are rich with pragmatic elements, such as entity mentions, references, and implicatures. Understanding such nuances is a requirement for successful natural communication, and often requires building a local world model which encodes such elements and captures the dynamics of their evolving states. However, it is not well-understood whether language models (LMs) construct or maintain a robust implicit representation of conversations. In this work, we evaluate the ability of LMs to encode and update their internal world model in dyadic conversations and test their malleability under linguistic alterations. To facilitate this, we apply seven minimal linguistic alterations to conversations sourced from popular datasets and construct two benchmarks comprising yes-no questions. We evaluate a wide range of open and closed source LMs and observe that they struggle to maintain robust accuracy. Our analysis unveils that LMs struggle to memorize crucial details, such as tracking entities under linguistic alterations to conversations. We then propose a dual-perspective interpretability framework which identifies transformer layers that are useful or harmful and highlights linguistic alterations most influenced by harmful layers, typically due to encoding spurious signals or relying on shortcuts. Inspired by these insights, we propose two layer-regularization based fine-tuning strategies that suppress the effect of the harmful layers.
NLKI: A lightweight Natural Language Knowledge Integration Framework for Improving Small VLMs in Commonsense VQA Tasks
Aug 28, 2025Commonsense visual-question answering often hinges on knowledge that is missing from the image or the question. Small vision-language models (sVLMs) such as ViLT, VisualBERT and FLAVA therefore lag behind their larger generative counterparts. To study the effect of careful commonsense knowledge integration on sVLMs, we present an end-to-end framework (NLKI) that (i) retrieves natural language facts, (ii) prompts an LLM to craft natural language explanations, and (iii) feeds both signals to sVLMs respectively across two commonsense VQA datasets (CRIC, AOKVQA) and a visual-entailment dataset (e-SNLI-VE). Facts retrieved using a fine-tuned ColBERTv2 and an object information-enriched prompt yield explanations that largely cut down hallucinations, while lifting the end-to-end answer accuracy by up to 7% (across 3 datasets), making FLAVA and other models in NLKI match or exceed medium-sized VLMs such as Qwen-2 VL-2B and SmolVLM-2.5B. As these benchmarks contain 10-25% label noise, additional finetuning using noise-robust losses (such as symmetric cross entropy and generalised cross entropy) adds another 2.5% in CRIC, and 5.5% in AOKVQA. Our findings expose when LLM-based commonsense knowledge beats retrieval from commonsense knowledge bases, how noise-aware training stabilises small models in the context of external knowledge augmentation, and why parameter-efficient commonsense reasoning is now within reach for 250M models.
AURA: Affordance-Understanding and Risk-aware Alignment Technique for Large Language Models
Aug 08, 2025Present day LLMs face the challenge of managing affordance-based safety risks-situations where outputs inadvertently facilitate harmful actions due to overlooked logical implications. Traditional safety solutions, such as scalar outcome-based reward models, parameter tuning, or heuristic decoding strategies, lack the granularity and proactive nature needed to reliably detect and intervene during subtle yet crucial reasoning steps. Addressing this fundamental gap, we introduce AURA, an innovative, multi-layered framework centered around Process Reward Models (PRMs), providing comprehensive, step level evaluations across logical coherence and safety-awareness. Our framework seamlessly combines introspective self-critique, fine-grained PRM assessments, and adaptive safety-aware decoding to dynamically and proactively guide models toward safer reasoning trajectories. Empirical evidence clearly demonstrates that this approach significantly surpasses existing methods, significantly improving the logical integrity and affordance-sensitive safety of model outputs. This research represents a pivotal step toward safer, more responsible, and contextually aware AI, setting a new benchmark for alignment-sensitive applications.
REFINE-AF: A Task-Agnostic Framework to Align Language Models via Self-Generated Instructions using Reinforcement Learning from Automated Feedback
May 10, 2025Instruction-based Large Language Models (LLMs) have proven effective in numerous few-shot or zero-shot Natural Language Processing (NLP) tasks. However, creating human-annotated instruction data is time-consuming, expensive, and often limited in quantity and task diversity. Previous research endeavors have attempted to address this challenge by proposing frameworks capable of generating instructions in a semi-automated and task-agnostic manner directly from the model itself. Many of these efforts have relied on large API-only parameter-based models such as GPT-3.5 (175B), which are expensive, and subject to limits on a number of queries. This paper explores the performance of three open-source small LLMs such as LLaMA 2-7B, LLama 2-13B, and Mistral 7B, using a semi-automated framework, thereby reducing human intervention, effort, and cost required to generate an instruction dataset for fine-tuning LLMs. Furthermore, we demonstrate that incorporating a Reinforcement Learning (RL) based training algorithm into this LLMs-based framework leads to further enhancements. Our evaluation of the dataset reveals that these RL-based frameworks achieve a substantial improvements in 63-66% of the tasks compared to previous approaches.
SMAB: MAB based word Sensitivity Estimation Framework and its Applications in Adversarial Text Generation
Feb 10, 2025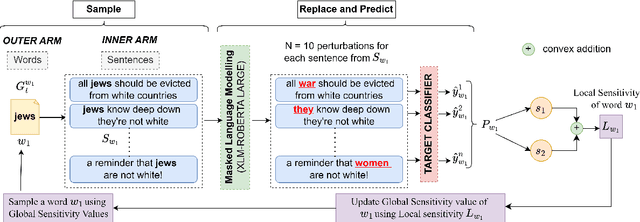

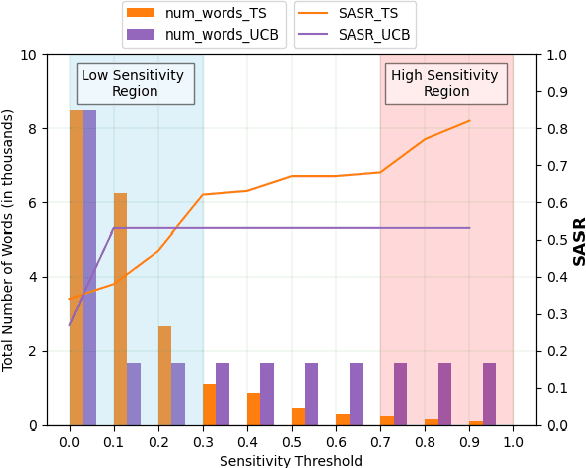

To understand the complexity of sequence classification tasks, Hahn et al. (2021) proposed sensitivity as the number of disjoint subsets of the input sequence that can each be individually changed to change the output. Though effective, calculating sensitivity at scale using this framework is costly because of exponential time complexity. Therefore, we introduce a Sensitivity-based Multi-Armed Bandit framework (SMAB), which provides a scalable approach for calculating word-level local (sentence-level) and global (aggregated) sensitivities concerning an underlying text classifier for any dataset. We establish the effectiveness of our approach through various applications. We perform a case study on CHECKLIST generated sentiment analysis dataset where we show that our algorithm indeed captures intuitively high and low-sensitive words. Through experiments on multiple tasks and languages, we show that sensitivity can serve as a proxy for accuracy in the absence of gold data. Lastly, we show that guiding perturbation prompts using sensitivity values in adversarial example generation improves attack success rate by 15.58%, whereas using sensitivity as an additional reward in adversarial paraphrase generation gives a 12.00% improvement over SOTA approaches. Warning: Contains potentially offensive content.
ERVQA: A Dataset to Benchmark the Readiness of Large Vision Language Models in Hospital Environments
Oct 08, 2024The global shortage of healthcare workers has demanded the development of smart healthcare assistants, which can help monitor and alert healthcare workers when necessary. We examine the healthcare knowledge of existing Large Vision Language Models (LVLMs) via the Visual Question Answering (VQA) task in hospital settings through expert annotated open-ended questions. We introduce the Emergency Room Visual Question Answering (ERVQA) dataset, consisting of <image, question, answer> triplets covering diverse emergency room scenarios, a seminal benchmark for LVLMs. By developing a detailed error taxonomy and analyzing answer trends, we reveal the nuanced nature of the task. We benchmark state-of-the-art open-source and closed LVLMs using traditional and adapted VQA metrics: Entailment Score and CLIPScore Confidence. Analyzing errors across models, we infer trends based on properties like decoder type, model size, and in-context examples. Our findings suggest the ERVQA dataset presents a highly complex task, highlighting the need for specialized, domain-specific solutions.
Jailbreak Paradox: The Achilles' Heel of LLMs
Jun 18, 2024We introduce two paradoxes concerning jailbreak of foundation models: First, it is impossible to construct a perfect jailbreak classifier, and second, a weaker model cannot consistently detect whether a stronger (in a pareto-dominant sense) model is jailbroken or not. We provide formal proofs for these paradoxes and a short case study on Llama and GPT4-o to demonstrate this. We discuss broader theoretical and practical repercussions of these results.
MATHSENSEI: A Tool-Augmented Large Language Model for Mathematical Reasoning
Feb 27, 2024



Tool-augmented Large Language Models (TALM) are known to enhance the skillset of large language models (LLM), thereby, leading to their improved reasoning abilities across many tasks. While, TALMs have been successfully employed in different question-answering benchmarks, their efficacy on complex mathematical reasoning benchmarks, and the potential complimentary benefits offered by tools for knowledge retrieval and mathematical equation solving, are open research questions. In this work, we present MATHSENSEI, a tool-augmented large language model for mathematical reasoning. Augmented with tools for knowledge retrieval (Bing Web Search), program execution (Python), and symbolic equation solving (Wolfram-Alpha), we study the complimentary benefits of these tools through evaluations on mathematical reasoning datasets. We perform exhaustive ablations on MATH,a popular dataset for evaluating mathematical reasoning on diverse mathematical disciplines. We also conduct experiments involving well-known tool planners to study the impact of tool sequencing on the model performance. MATHSENSEI achieves 13.5% better accuracy over gpt-3.5-turbo with chain-of-thought on the MATH dataset. We further observe that TALMs are not as effective for simpler math word problems (in GSM-8k), and the benefit increases as the complexity and required knowledge increases (progressively over AQuA, MMLU-Math, and higher level complex questions in MATH). The code and data are available at https://github.com/Debrup-61/MathSensei.