 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaDeR: Reasoning-aware Dense Retrieval Models
May 23, 2025We propose RaDeR, a set of reasoning-based dense retrieval models trained with data derived from mathematical problem solving using large language models (LLMs). Our method leverages retrieval-augmented reasoning trajectories of an LLM and self-reflective relevance evaluation, enabling the creation of both diverse and hard-negative samples for reasoning-intensive relevance. RaDeR retrievers, trained for mathematical reasoning, effectively generalize to diverse reasoning tasks in the BRIGHT and RAR-b benchmarks, consistently outperforming strong baselines in overall performance.Notably, RaDeR achieves significantly higher performance than baselines on the Math and Coding splits. In addition, RaDeR presents the first dense retriever that outperforms BM25 when queries are Chain-of-Thought reasoning steps, underscoring the critical role of reasoning-based retrieval to augment reasoning language models. Furthermore, RaDeR achieves comparable or superior performance while using only 2.5% of the training data used by the concurrent work REASONIR, highlighting the quality of our synthesized training data.
SMAB: MAB based word Sensitivity Estimation Framework and its Applications in Adversarial Text Generation
Feb 10, 2025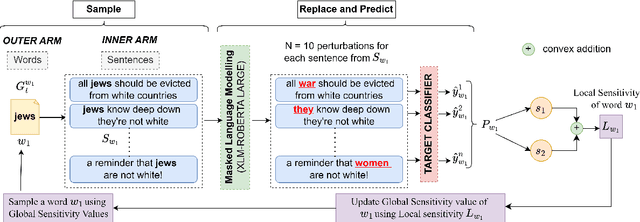

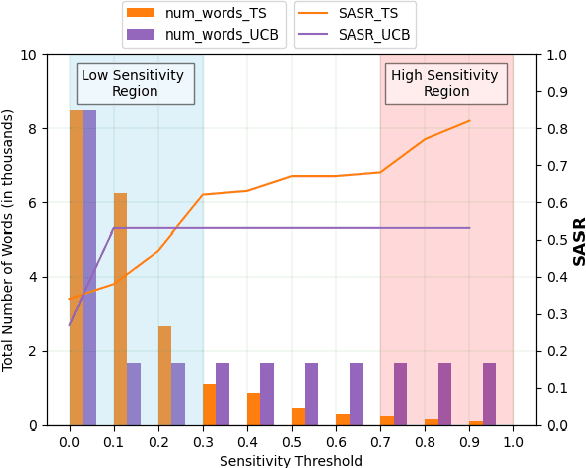

To understand the complexity of sequence classification tasks, Hahn et al. (2021) proposed sensitivity as the number of disjoint subsets of the input sequence that can each be individually changed to change the output. Though effective, calculating sensitivity at scale using this framework is costly because of exponential time complexity. Therefore, we introduce a Sensitivity-based Multi-Armed Bandit framework (SMAB), which provides a scalable approach for calculating word-level local (sentence-level) and global (aggregated) sensitivities concerning an underlying text classifier for any dataset. We establish the effectiveness of our approach through various applications. We perform a case study on CHECKLIST generated sentiment analysis dataset where we show that our algorithm indeed captures intuitively high and low-sensitive words. Through experiments on multiple tasks and languages, we show that sensitivity can serve as a proxy for accuracy in the absence of gold data. Lastly, we show that guiding perturbation prompts using sensitivity values in adversarial example generation improves attack success rate by 15.58%, whereas using sensitivity as an additional reward in adversarial paraphrase generation gives a 12.00% improvement over SOTA approaches. Warning: Contains potentially offensive content.
MATHSENSEI: A Tool-Augmented Large Language Model for Mathematical Reasoning
Feb 27, 2024



Tool-augmented Large Language Models (TALM) are known to enhance the skillset of large language models (LLM), thereby, leading to their improved reasoning abilities across many tasks. While, TALMs have been successfully employed in different question-answering benchmarks, their efficacy on complex mathematical reasoning benchmarks, and the potential complimentary benefits offered by tools for knowledge retrieval and mathematical equation solving, are open research questions. In this work, we present MATHSENSEI, a tool-augmented large language model for mathematical reasoning. Augmented with tools for knowledge retrieval (Bing Web Search), program execution (Python), and symbolic equation solving (Wolfram-Alpha), we study the complimentary benefits of these tools through evaluations on mathematical reasoning datasets. We perform exhaustive ablations on MATH,a popular dataset for evaluating mathematical reasoning on diverse mathematical disciplines. We also conduct experiments involving well-known tool planners to study the impact of tool sequencing on the model performance. MATHSENSEI achieves 13.5% better accuracy over gpt-3.5-turbo with chain-of-thought on the MATH dataset. We further observe that TALMs are not as effective for simpler math word problems (in GSM-8k), and the benefit increases as the complexity and required knowledge increases (progressively over AQuA, MMLU-Math, and higher level complex questions in MATH). The code and data are available at https://github.com/Debrup-61/MathSensei.