 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBHM: Functional Benchmarking and Steering of VLMs for Hateful Meme Detection
May 29, 2026Hateful meme detection remains a formidable challenge for vision-language models, as existing benchmarks are structurally observational - confounding rhetorical hate mechanisms with target community features and preventing causal evaluation of model vulnerabilities. To address this, we introduce FBHM, a systematically curated benchmark of Functionality Based Hateful Memes constructed along two orthogonal axes: 25 distinct rhetorical functionalities and 10 target communities (5,000 memes total). Benchmarking state-of-the-art VLMs reveals a severe generalization gap: models highly accurate on standard datasets catastrophically drop to near-random performance on FBHM, proving they exploit dataset-specific heuristics rather than robust multimodal reasoning. To efficiently close this gap, we propose LSV (learnable steering vectors), an ultra-low data regime strategy that applies a causal intervention objective on as few as 500 steering samples (50 unique base memes), boosting FBHM performance by ~30 Macro-F1 points while outperforming in-context learning and PEFT without degrading source-domain performance.
To Generate or Discriminate? Methodological Considerations for Measuring Cultural Alignment in LLMs
Jan 06, 2026Socio-demographic prompting (SDP) - prompting Large Language Models (LLMs) using demographic proxies to generate culturally aligned outputs - often shows LLM responses as stereotypical and biased. While effective in assessing LLMs' cultural competency, SDP is prone to confounding factors such as prompt sensitivity, decoding parameters, and the inherent difficulty of generation over discrimination tasks due to larger output spaces. These factors complicate interpretation, making it difficult to determine if the poor performance is due to bias or the task design. To address this, we use inverse socio-demographic prompting (ISDP), where we prompt LLMs to discriminate and predict the demographic proxy from actual and simulated user behavior from different users. We use the Goodreads-CSI dataset (Saha et al., 2025), which captures difficulty in understanding English book reviews for users from India, Mexico, and the USA, and test four LLMs: Aya-23, Gemma-2, GPT-4o, and LLaMA-3.1 with ISDP. Results show that models perform better with actual behaviors than simulated ones, contrary to what SDP suggests. However, performance with both behavior types diminishes and becomes nearly equal at the individual level, indicating limits to personalization.
SMAB: MAB based word Sensitivity Estimation Framework and its Applications in Adversarial Text Generation
Feb 10, 2025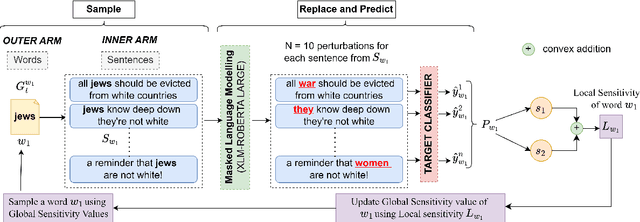

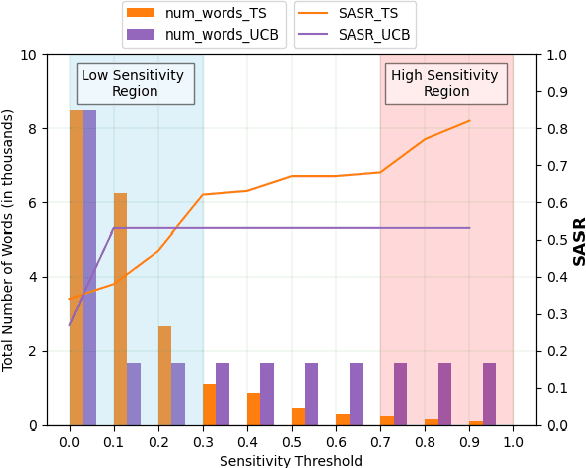

To understand the complexity of sequence classification tasks, Hahn et al. (2021) proposed sensitivity as the number of disjoint subsets of the input sequence that can each be individually changed to change the output. Though effective, calculating sensitivity at scale using this framework is costly because of exponential time complexity. Therefore, we introduce a Sensitivity-based Multi-Armed Bandit framework (SMAB), which provides a scalable approach for calculating word-level local (sentence-level) and global (aggregated) sensitivities concerning an underlying text classifier for any dataset. We establish the effectiveness of our approach through various applications. We perform a case study on CHECKLIST generated sentiment analysis dataset where we show that our algorithm indeed captures intuitively high and low-sensitive words. Through experiments on multiple tasks and languages, we show that sensitivity can serve as a proxy for accuracy in the absence of gold data. Lastly, we show that guiding perturbation prompts using sensitivity values in adversarial example generation improves attack success rate by 15.58%, whereas using sensitivity as an additional reward in adversarial paraphrase generation gives a 12.00% improvement over SOTA approaches. Warning: Contains potentially offensive content.
Low-Resource Counterspeech Generation for Indic Languages: The Case of Bengali and Hindi
Feb 11, 2024With the rise of online abuse, the NLP community has begun investigating the use of neural architectures to generate counterspeech that can "counter" the vicious tone of such abusive speech and dilute/ameliorate their rippling effect over the social network. However, most of the efforts so far have been primarily focused on English. To bridge the gap for low-resource languages such as Bengali and Hindi, we create a benchmark dataset of 5,062 abusive speech/counterspeech pairs, of which 2,460 pairs are in Bengali and 2,602 pairs are in Hindi. We implement several baseline models considering various interlingual transfer mechanisms with different configurations to generate suitable counterspeech to set up an effective benchmark. We observe that the monolingual setup yields the best performance. Further, using synthetic transfer, language models can generate counterspeech to some extent; specifically, we notice that transferability is better when languages belong to the same language family.
CONTRASTE: Supervised Contrastive Pre-training With Aspect-based Prompts For Aspect Sentiment Triplet Extraction
Oct 24, 2023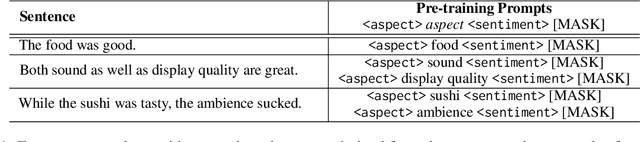
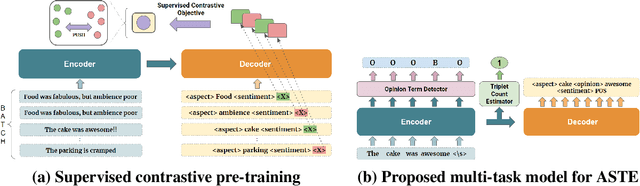

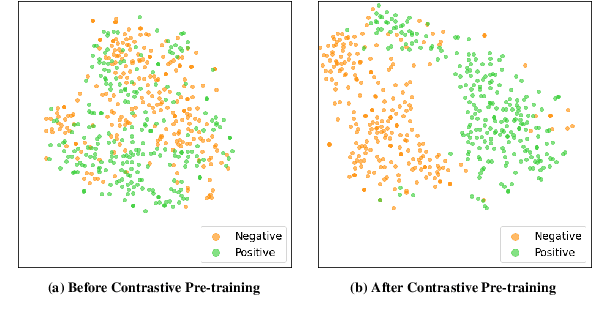
Existing works on Aspect Sentiment Triplet Extraction (ASTE) explicitly focus on developing more efficient fine-tuning techniques for the task. Instead, our motivation is to come up with a generic approach that can improve the downstream performances of multiple ABSA tasks simultaneously. Towards this, we present CONTRASTE, a novel pre-training strategy using CONTRastive learning to enhance the ASTE performance. While we primarily focus on ASTE, we also demonstrate the advantage of our proposed technique on other ABSA tasks such as ACOS, TASD, and AESC. Given a sentence and its associated (aspect, opinion, sentiment) triplets, first, we design aspect-based prompts with corresponding sentiments masked. We then (pre)train an encoder-decoder model by applying contrastive learning on the decoder-generated aspect-aware sentiment representations of the masked terms. For fine-tuning the model weights thus obtained, we then propose a novel multi-task approach where the base encoder-decoder model is combined with two complementary modules, a tagging-based Opinion Term Detector, and a regression-based Triplet Count Estimator. Exhaustive experiments on four benchmark datasets and a detailed ablation study establish the importance of each of our proposed components as we achieve new state-of-the-art ASTE results.
Evaluating ChatGPT's Performance for Multilingual and Emoji-based Hate Speech Detection
May 23, 2023



Hate speech is a severe issue that affects many online platforms. So far, several studies have been performed to develop robust hate speech detection systems. Large language models like ChatGPT have recently shown a great promise in performing several tasks, including hate speech detection. However, it is crucial to comprehend the limitations of these models to build robust hate speech detection systems. To bridge this gap, our study aims to evaluate the strengths and weaknesses of the ChatGPT model in detecting hate speech at a granular level across 11 languages. Our evaluation employs a series of functionality tests that reveals various intricate failures of the model which the aggregate metrics like macro F1 or accuracy are not able to unfold. In addition, we investigate the influence of complex emotions, such as the use of emojis in hate speech, on the performance of the ChatGPT model. Our analysis highlights the shortcomings of the generative models in detecting certain types of hate speech and highlighting the need for further research and improvements in the workings of these models.
On the rise of fear speech in online social media
Mar 18, 2023



Recently, social media platforms are heavily moderated to prevent the spread of online hate speech, which is usually fertile in toxic words and is directed toward an individual or a community. Owing to such heavy moderation, newer and more subtle techniques are being deployed. One of the most striking among these is fear speech. Fear speech, as the name suggests, attempts to incite fear about a target community. Although subtle, it might be highly effective, often pushing communities toward a physical conflict. Therefore, understanding their prevalence in social media is of paramount importance. This article presents a large-scale study to understand the prevalence of 400K fear speech and over 700K hate speech posts collected from Gab.com. Remarkably, users posting a large number of fear speech accrue more followers and occupy more central positions in social networks than users posting a large number of hate speech. They can also reach out to benign users more effectively than hate speech users through replies, reposts, and mentions. This connects to the fact that, unlike hate speech, fear speech has almost zero toxic content, making it look plausible. Moreover, while fear speech topics mostly portray a community as a perpetrator using a (fake) chain of argumentation, hate speech topics hurl direct multitarget insults, thus pointing to why general users could be more gullible to fear speech. Our findings transcend even to other platforms (Twitter and Facebook) and thus necessitate using sophisticated moderation policies and mass awareness to combat fear speech.