 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRAJEVAL: Decomposing Code Agent Trajectories for Fine-Grained Diagnosis
Mar 25, 2026Code agents can autonomously resolve GitHub issues, yet when they fail, current evaluation provides no visibility into where or why. Metrics such as Pass@1 collapse an entire execution into a single binary outcome, making it difficult to identify where and why the agent went wrong. To address this limitation, we introduce TRAJEVAL, a diagnostic framework that decomposes agent trajectories into three interpretable stages: search (file localization), read (function comprehension), and edit (modification targeting). For each stage, we compute precision and recall by comparing against reference patches. Analyzing 16,758 trajectories across three agent architectures and seven models, we find universal inefficiencies (all agents examine approximately 22x more functions than necessary) yet distinct failure modes: GPT-5 locates relevant code but targets edits incorrectly, while Qwen-32B fails at file discovery entirely. We validate that these diagnostics are predictive, achieving model-level Pass@1 prediction within 0.87-2.1% MAE, and actionable: real-time feedback based on trajectory signals improves two state-of-the-art models by 2.2-4.6 percentage points while reducing costs by 20-31%. These results demonstrate that our framework not only provides a more fine-grained analysis of agent behavior, but also translates diagnostic signals into tangible performance gains. More broadly, TRAJEVAL transforms agent evaluation beyond outcome-based benchmarking toward mechanism-driven diagnosis of agent success and failure.
Advantages of Domain Knowledge Injection for Legal Document Summarization: A Case Study on Summarizing Indian Court Judgments in English and Hindi
Feb 07, 2026Summarizing Indian legal court judgments is a complex task not only due to the intricate language and unstructured nature of the legal texts, but also since a large section of the Indian population does not understand the complex English in which legal text is written, thus requiring summaries in Indian languages. In this study, we aim to improve the summarization of Indian legal text to generate summaries in both English and Hindi (the most widely spoken Indian language), by injecting domain knowledge into diverse summarization models. We propose a framework to enhance extractive neural summarization models by incorporating domain-specific pre-trained encoders tailored for legal texts. Further, we explore the injection of legal domain knowledge into generative models (including Large Language Models) through continual pre-training on large legal corpora in English and Hindi. Our proposed approaches achieve statistically significant improvements in both English-to-English and English-to-Hindi Indian legal document summarization, as measured by standard evaluation metrics, factual consistency metrics, and legal domain-specific metrics. Furthermore, these improvements are validated through domain experts, demonstrating the effectiveness of our approaches.
Aero-LLM: A Distributed Framework for Secure UAV Communication and Intelligent Decision-Making
Feb 05, 2025Increased utilization of unmanned aerial vehicles (UAVs) in critical operations necessitates secure and reliable communication with Ground Control Stations (GCS). This paper introduces Aero-LLM, a framework integrating multiple Large Language Models (LLMs) to enhance UAV mission security and operational efficiency. Unlike conventional singular LLMs, Aero-LLM leverages multiple specialized LLMs for various tasks, such as inferencing, anomaly detection, and forecasting, deployed across onboard systems, edge, and cloud servers. This dynamic, distributed architecture reduces performance bottleneck and increases security capabilities. Aero-LLM's evaluation demonstrates outstanding task-specific metrics and robust defense against cyber threats, significantly enhancing UAV decision-making and operational capabilities and security resilience against cyber attacks, setting a new standard for secure, intelligent UAV operations.
Parameter-Efficient Instruction Tuning of Large Language Models For Extreme Financial Numeral Labelling
May 15, 2024


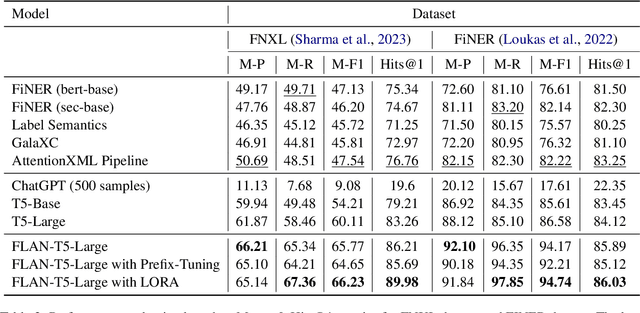
We study the problem of automatically annotating relevant numerals (GAAP metrics) occurring in the financial documents with their corresponding XBRL tags. Different from prior works, we investigate the feasibility of solving this extreme classification problem using a generative paradigm through instruction tuning of Large Language Models (LLMs). To this end, we leverage metric metadata information to frame our target outputs while proposing a parameter efficient solution for the task using LoRA. We perform experiments on two recently released financial numeric labeling datasets. Our proposed model, FLAN-FinXC, achieves new state-of-the-art performances on both the datasets, outperforming several strong baselines. We explain the better scores of our proposed model by demonstrating its capability for zero-shot as well as the least frequently occurring tags. Also, even when we fail to predict the XBRL tags correctly, our generated output has substantial overlap with the ground-truth in majority of the cases.
MILDSum: A Novel Benchmark Dataset for Multilingual Summarization of Indian Legal Case Judgments
Oct 28, 2023



Automatic summarization of legal case judgments is a practically important problem that has attracted substantial research efforts in many countries. In the context of the Indian judiciary, there is an additional complexity -- Indian legal case judgments are mostly written in complex English, but a significant portion of India's population lacks command of the English language. Hence, it is crucial to summarize the legal documents in Indian languages to ensure equitable access to justice. While prior research primarily focuses on summarizing legal case judgments in their source languages, this study presents a pioneering effort toward cross-lingual summarization of English legal documents into Hindi, the most frequently spoken Indian language. We construct the first high-quality legal corpus comprising of 3,122 case judgments from prominent Indian courts in English, along with their summaries in both English and Hindi, drafted by legal practitioners. We benchmark the performance of several diverse summarization approaches on our corpus and demonstrate the need for further research in cross-lingual summarization in the legal domain.
CONTRASTE: Supervised Contrastive Pre-training With Aspect-based Prompts For Aspect Sentiment Triplet Extraction
Oct 24, 2023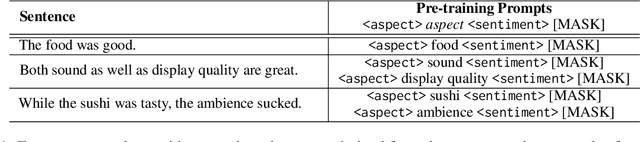
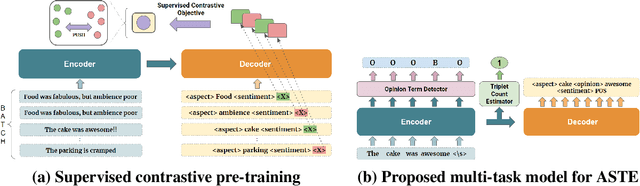

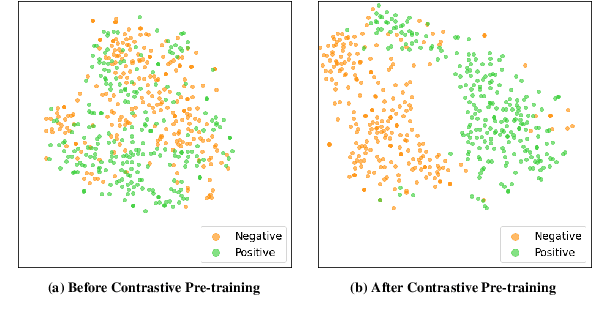
Existing works on Aspect Sentiment Triplet Extraction (ASTE) explicitly focus on developing more efficient fine-tuning techniques for the task. Instead, our motivation is to come up with a generic approach that can improve the downstream performances of multiple ABSA tasks simultaneously. Towards this, we present CONTRASTE, a novel pre-training strategy using CONTRastive learning to enhance the ASTE performance. While we primarily focus on ASTE, we also demonstrate the advantage of our proposed technique on other ABSA tasks such as ACOS, TASD, and AESC. Given a sentence and its associated (aspect, opinion, sentiment) triplets, first, we design aspect-based prompts with corresponding sentiments masked. We then (pre)train an encoder-decoder model by applying contrastive learning on the decoder-generated aspect-aware sentiment representations of the masked terms. For fine-tuning the model weights thus obtained, we then propose a novel multi-task approach where the base encoder-decoder model is combined with two complementary modules, a tagging-based Opinion Term Detector, and a regression-based Triplet Count Estimator. Exhaustive experiments on four benchmark datasets and a detailed ablation study establish the importance of each of our proposed components as we achieve new state-of-the-art ASTE results.
Legal Case Document Summarization: Extractive and Abstractive Methods and their Evaluation
Oct 14, 2022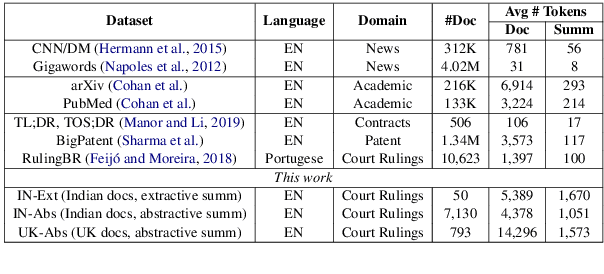
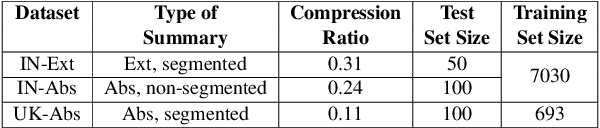
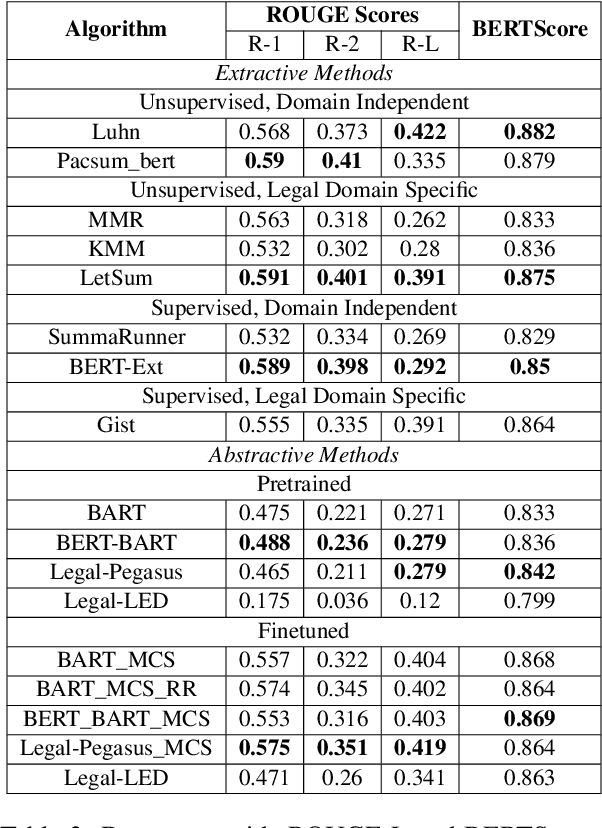
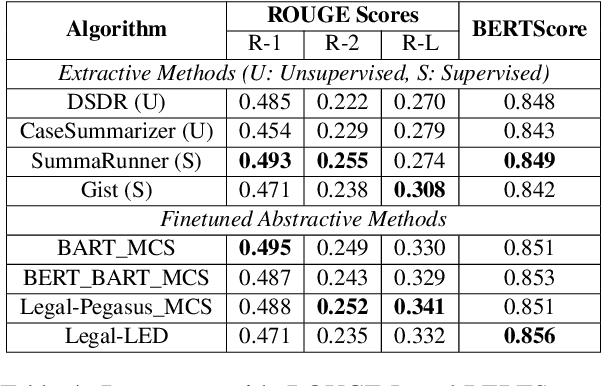
Summarization of legal case judgement documents is a challenging problem in Legal NLP. However, not much analyses exist on how different families of summarization models (e.g., extractive vs. abstractive) perform when applied to legal case documents. This question is particularly important since many recent transformer-based abstractive summarization models have restrictions on the number of input tokens, and legal documents are known to be very long. Also, it is an open question on how best to evaluate legal case document summarization systems. In this paper, we carry out extensive experiments with several extractive and abstractive summarization methods (both supervised and unsupervised) over three legal summarization datasets that we have developed. Our analyses, that includes evaluation by law practitioners, lead to several interesting insights on legal summarization in specific and long document summarization in general.
ETMS@IITKGP at SemEval-2022 Task 10: Structured Sentiment Analysis Using A Generative Approach
May 01, 2022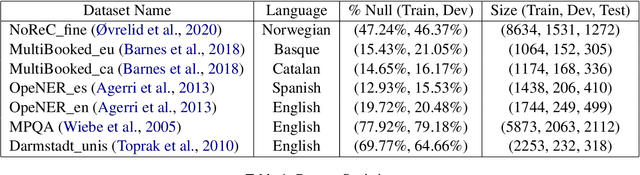

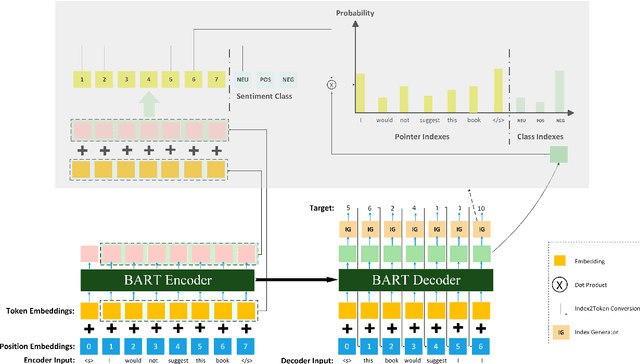
Structured Sentiment Analysis (SSA) deals with extracting opinion tuples in a text, where each tuple (h, e, t, p) consists of h, the holder, who expresses a sentiment polarity p towards a target t through a sentiment expression e. While prior works explore graph-based or sequence labeling-based approaches for the task, we in this paper present a novel unified generative method to solve SSA, a SemEval2022 shared task. We leverage a BART-based encoder-decoder architecture and suitably modify it to generate, given a sentence, a sequence of opinion tuples. Each generated tuple consists of seven integers respectively representing the indices corresponding to the start and end positions of the holder, target, and expression spans, followed by the sentiment polarity class associated between the target and the sentiment expression. We perform rigorous experiments for both Monolingual and Cross-lingual subtasks, and achieve competitive Sentiment F1 scores on the leaderboard in both settings.
CAVES: A Dataset to facilitate Explainable Classification and Summarization of Concerns towards COVID Vaccines
Apr 28, 2022
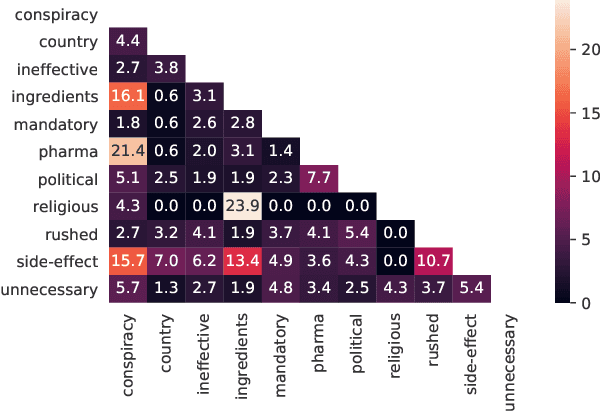
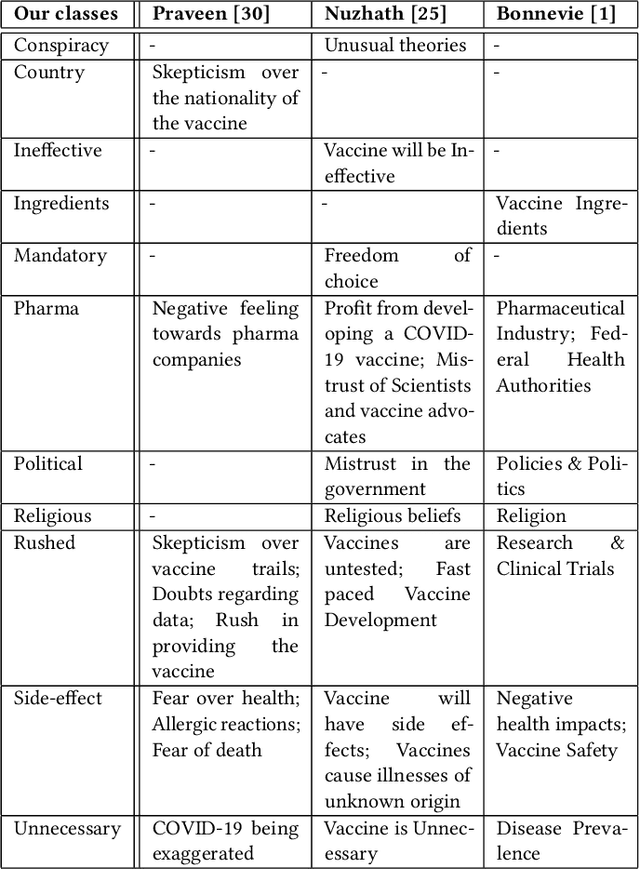
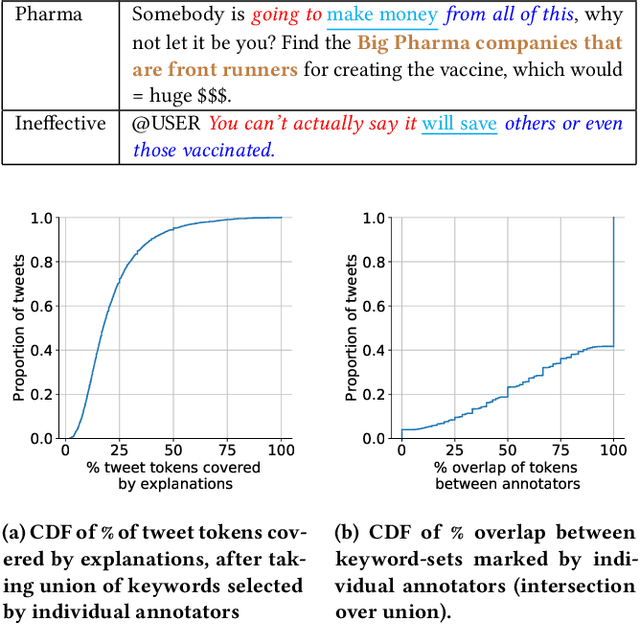
Convincing people to get vaccinated against COVID-19 is a key societal challenge in the present times. As a first step towards this goal, many prior works have relied on social media analysis to understand the specific concerns that people have towards these vaccines, such as potential side-effects, ineffectiveness, political factors, and so on. Though there are datasets that broadly classify social media posts into Anti-vax and Pro-Vax labels, there is no dataset (to our knowledge) that labels social media posts according to the specific anti-vaccine concerns mentioned in the posts. In this paper, we have curated CAVES, the first large-scale dataset containing about 10k COVID-19 anti-vaccine tweets labelled into various specific anti-vaccine concerns in a multi-label setting. This is also the first multi-label classification dataset that provides explanations for each of the labels. Additionally, the dataset also provides class-wise summaries of all the tweets. We also perform preliminary experiments on the dataset and show that this is a very challenging dataset for multi-label explainable classification and tweet summarization, as is evident by the moderate scores achieved by some state-of-the-art models. Our dataset and codes are available at: https://github.com/sohampoddar26/caves-data
MTLTS: A Multi-Task Framework To Obtain Trustworthy Summaries From Crisis-Related Microblogs
Dec 10, 2021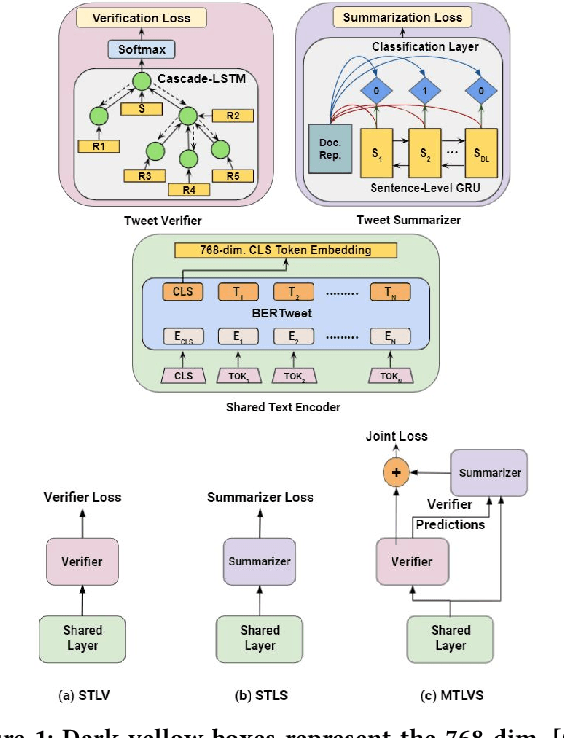
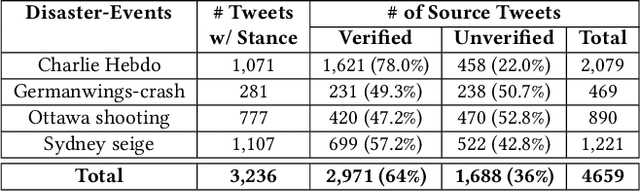
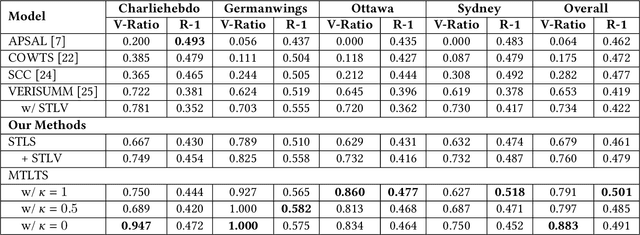
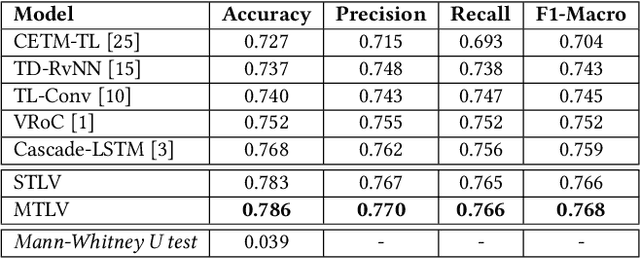
Occurrences of catastrophes such as natural or man-made disasters trigger the spread of rumours over social media at a rapid pace. Presenting a trustworthy and summarized account of the unfolding event in near real-time to the consumers of such potentially unreliable information thus becomes an important task. In this work, we propose MTLTS, the first end-to-end solution for the task that jointly determines the credibility and summary-worthiness of tweets. Our credibility verifier is designed to recursively learn the structural properties of a Twitter conversation cascade, along with the stances of replies towards the source tweet. We then take a hierarchical multi-task learning approach, where the verifier is trained at a lower layer, and the summarizer is trained at a deeper layer where it utilizes the verifier predictions to determine the salience of a tweet. Different from existing disaster-specific summarizers, we model tweet summarization as a supervised task. Such an approach can automatically learn summary-worthy features, and can therefore generalize well across domains. When trained on the PHEME dataset [29], not only do we outperform the strongest baselines for the auxiliary task of verification/rumour detection, we also achieve 21 - 35% gains in the verified ratio of summary tweets, and 16 - 20% gains in ROUGE1-F1 scores over the existing state-of-the-art solutions for the primary task of trustworthy summarization.