 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrevity is the soul of sustainability: Characterizing LLM response lengths
Jun 10, 2025



A significant portion of the energy consumed by Large Language Models (LLMs) arises from their inference processes; hence developing energy-efficient methods for inference is crucial. While several techniques exist for inference optimization, output compression remains relatively unexplored, with only a few preliminary efforts addressing this aspect. In this work, we first benchmark 12 decoder-only LLMs across 5 datasets, revealing that these models often produce responses that are substantially longer than necessary. We then conduct a comprehensive quality assessment of LLM responses, formally defining six information categories present in LLM responses. We show that LLMs often tend to include redundant or additional information besides the minimal answer. To address this issue of long responses by LLMs, we explore several simple and intuitive prompt-engineering strategies. Empirical evaluation shows that appropriate prompts targeting length reduction and controlling information content can achieve significant energy optimization between 25-60\% by reducing the response length while preserving the quality of LLM responses.
Towards Sustainable NLP: Insights from Benchmarking Inference Energy in Large Language Models
Feb 08, 2025



Large language models (LLMs) are increasingly recognized for their exceptional generative capabilities and versatility across various tasks. However, the high inference costs associated with these models have not received adequate attention, particularly when compared to the focus on training costs in existing research. In response to this gap, our study conducts a comprehensive benchmarking of LLM inference energy across a wide range of NLP tasks, where we analyze the impact of different models, tasks, prompts, and system-related factors on inference energy. Specifically, our experiments reveal several interesting insights, including strong correlation of inference energy with output token length and response time. Also, we find that quantization and optimal batch sizes, along with targeted prompt phrases, can significantly reduce energy usage. This study is the first to thoroughly benchmark LLM inference across such a diverse range of aspects, providing insights and offering several recommendations for improving energy efficiency in model deployment.
ICPR 2024 Competition on Multilingual Claim-Span Identification
Nov 29, 2024A lot of claims are made in social media posts, which may contain misinformation or fake news. Hence, it is crucial to identify claims as a first step towards claim verification. Given the huge number of social media posts, the task of identifying claims needs to be automated. This competition deals with the task of 'Claim Span Identification' in which, given a text, parts / spans that correspond to claims are to be identified. This task is more challenging than the traditional binary classification of text into claim or not-claim, and requires state-of-the-art methods in Pattern Recognition, Natural Language Processing and Machine Learning. For this competition, we used a newly developed dataset called HECSI containing about 8K posts in English and about 8K posts in Hindi with claim-spans marked by human annotators. This paper gives an overview of the competition, and the solutions developed by the participating teams.
Legal Case Document Summarization: Extractive and Abstractive Methods and their Evaluation
Oct 14, 2022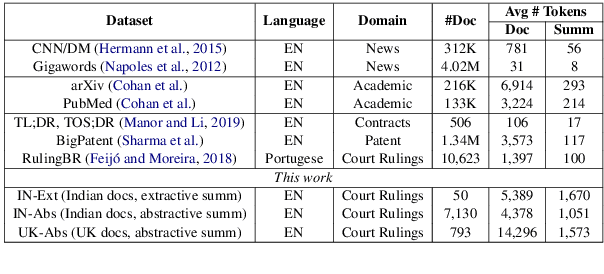
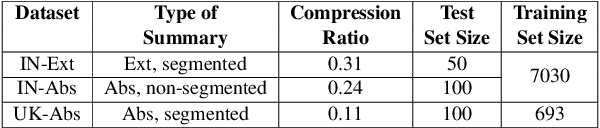
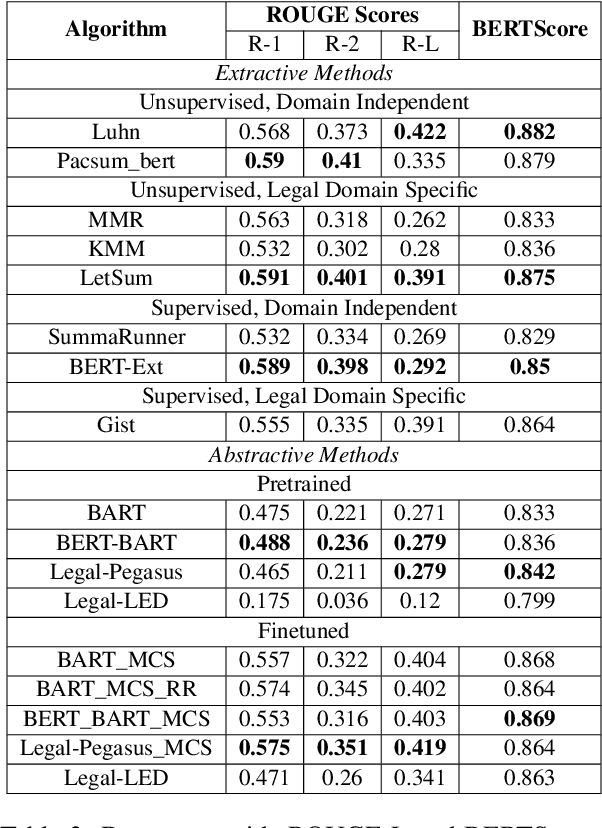
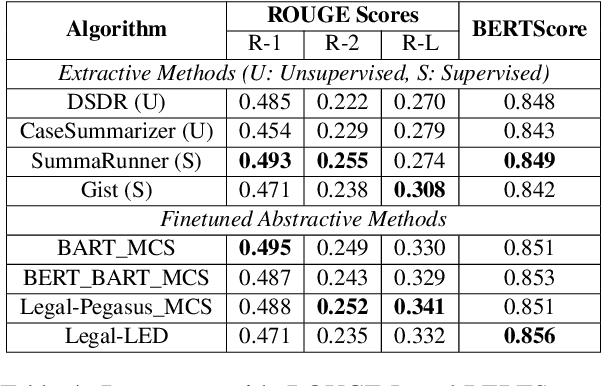
Summarization of legal case judgement documents is a challenging problem in Legal NLP. However, not much analyses exist on how different families of summarization models (e.g., extractive vs. abstractive) perform when applied to legal case documents. This question is particularly important since many recent transformer-based abstractive summarization models have restrictions on the number of input tokens, and legal documents are known to be very long. Also, it is an open question on how best to evaluate legal case document summarization systems. In this paper, we carry out extensive experiments with several extractive and abstractive summarization methods (both supervised and unsupervised) over three legal summarization datasets that we have developed. Our analyses, that includes evaluation by law practitioners, lead to several interesting insights on legal summarization in specific and long document summarization in general.
CAVES: A Dataset to facilitate Explainable Classification and Summarization of Concerns towards COVID Vaccines
Apr 28, 2022
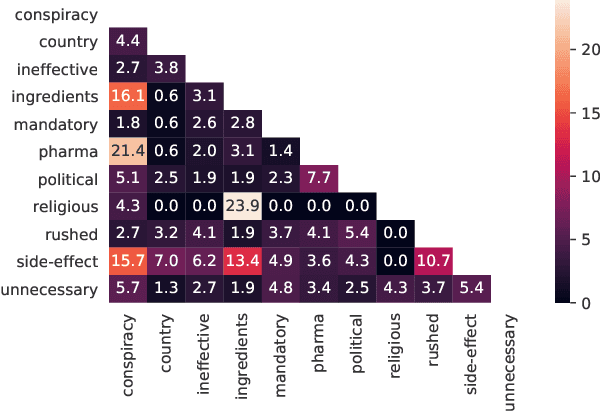
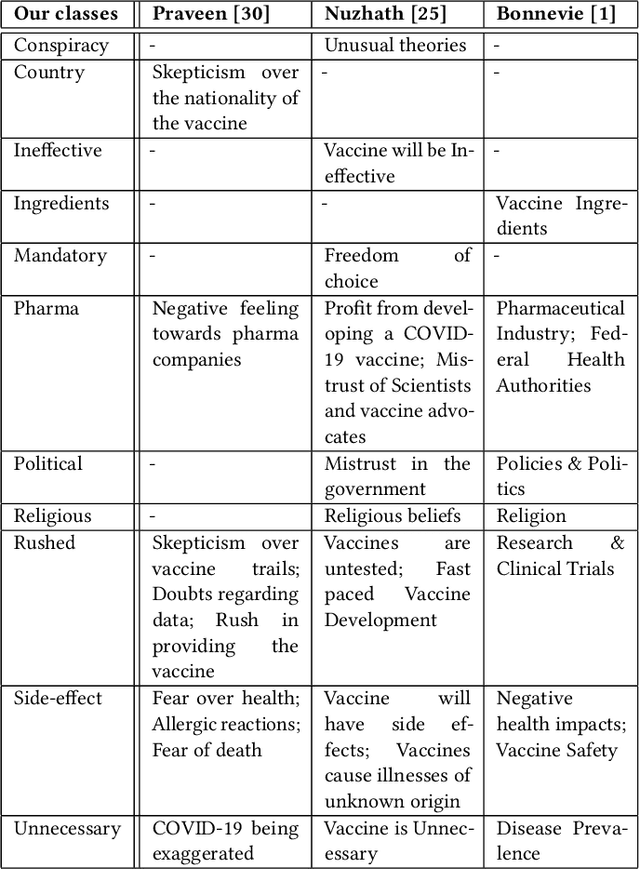
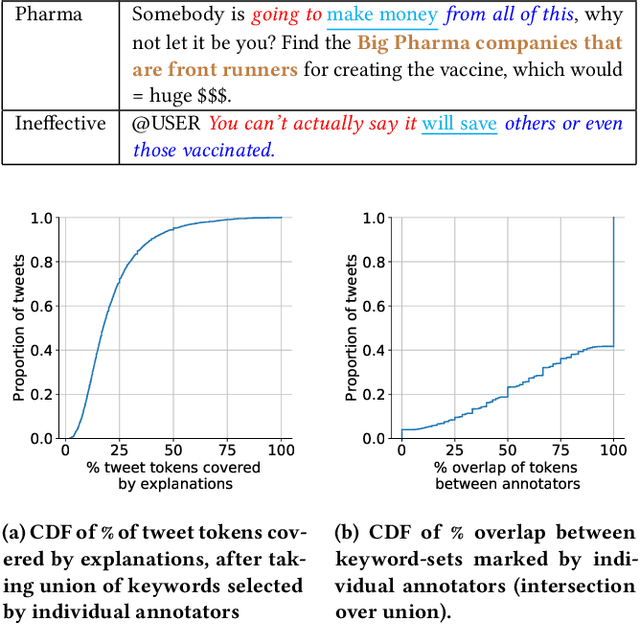
Convincing people to get vaccinated against COVID-19 is a key societal challenge in the present times. As a first step towards this goal, many prior works have relied on social media analysis to understand the specific concerns that people have towards these vaccines, such as potential side-effects, ineffectiveness, political factors, and so on. Though there are datasets that broadly classify social media posts into Anti-vax and Pro-Vax labels, there is no dataset (to our knowledge) that labels social media posts according to the specific anti-vaccine concerns mentioned in the posts. In this paper, we have curated CAVES, the first large-scale dataset containing about 10k COVID-19 anti-vaccine tweets labelled into various specific anti-vaccine concerns in a multi-label setting. This is also the first multi-label classification dataset that provides explanations for each of the labels. Additionally, the dataset also provides class-wise summaries of all the tweets. We also perform preliminary experiments on the dataset and show that this is a very challenging dataset for multi-label explainable classification and tweet summarization, as is evident by the moderate scores achieved by some state-of-the-art models. Our dataset and codes are available at: https://github.com/sohampoddar26/caves-data
Incorporating Domain Knowledge for Extractive Summarization of Legal Case Documents
Jun 30, 2021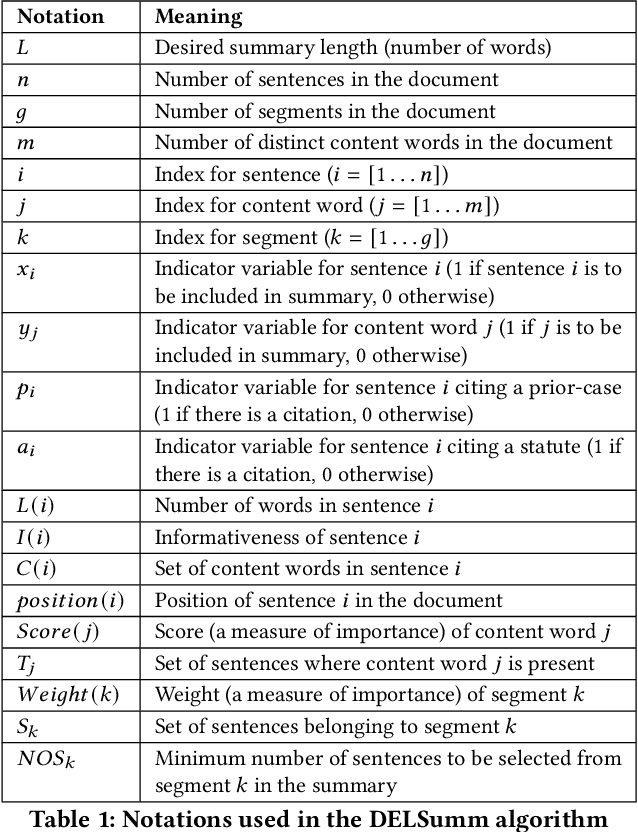


Automatic summarization of legal case documents is an important and practical challenge. Apart from many domain-independent text summarization algorithms that can be used for this purpose, several algorithms have been developed specifically for summarizing legal case documents. However, most of the existing algorithms do not systematically incorporate domain knowledge that specifies what information should ideally be present in a legal case document summary. To address this gap, we propose an unsupervised summarization algorithm DELSumm which is designed to systematically incorporate guidelines from legal experts into an optimization setup. We conduct detailed experiments over case documents from the Indian Supreme Court. The experiments show that our proposed unsupervised method outperforms several strong baselines in terms of ROUGE scores, including both general summarization algorithms and legal-specific ones. In fact, though our proposed algorithm is unsupervised, it outperforms several supervised summarization models that are trained over thousands of document-summary pairs.