 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Case Document Summarization: Extractive and Abstractive Methods and their Evaluation
Paper and Code
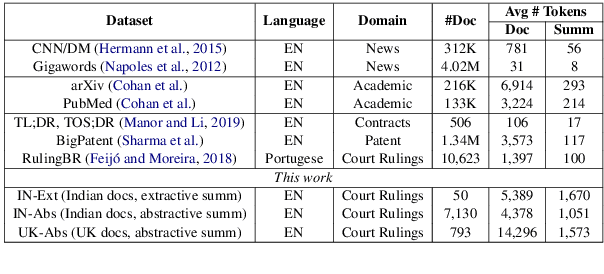
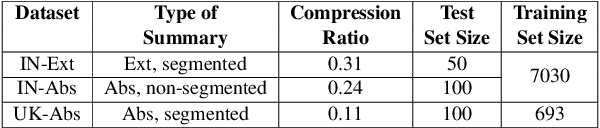
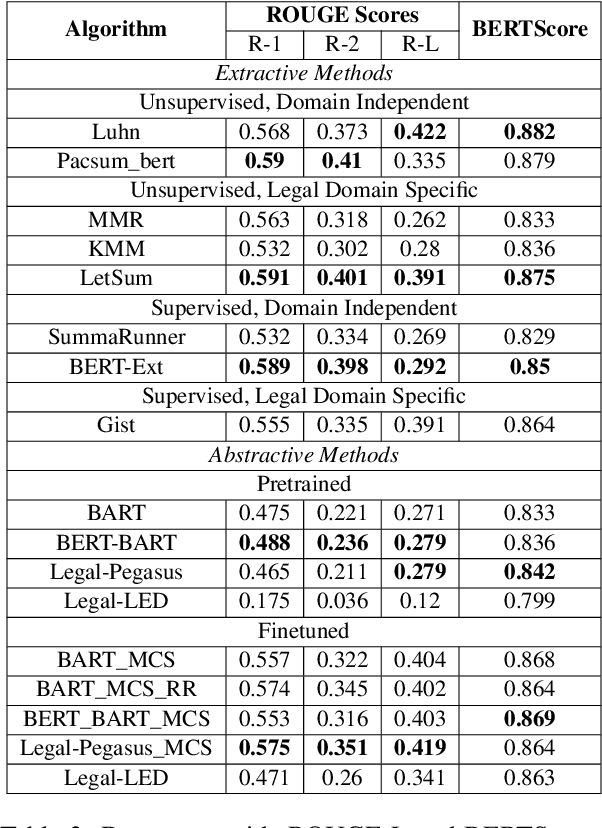
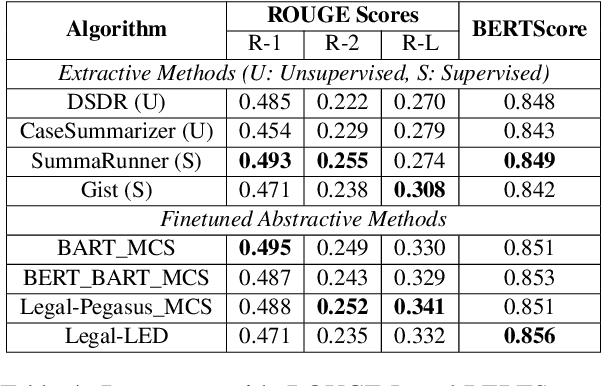
Summarization of legal case judgement documents is a challenging problem in Legal NLP. However, not much analyses exist on how different families of summarization models (e.g., extractive vs. abstractive) perform when applied to legal case documents. This question is particularly important since many recent transformer-based abstractive summarization models have restrictions on the number of input tokens, and legal documents are known to be very long. Also, it is an open question on how best to evaluate legal case document summarization systems. In this paper, we carry out extensive experiments with several extractive and abstractive summarization methods (both supervised and unsupervised) over three legal summarization datasets that we have developed. Our analyses, that includes evaluation by law practitioners, lead to several interesting insights on legal summarization in specific and long document summarization in general.