 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSima AIunty: Caste Audit in LLM-Driven Matchmaking
Mar 31, 2026Social and personal decisions in relational domains such as matchmaking are deeply entwined with cultural norms and historical hierarchies, and can potentially be shaped by algorithmic and AI-mediated assessments of compatibility, acceptance, and stability. In South Asian contexts, caste remains a central aspect of marital decision-making, yet little is known about how contemporary large language models (LLMs) reproduce or disrupt caste-based stratification in such settings. In this work, we conduct a controlled audit of caste bias in LLM-mediated matchmaking evaluations using real-world matrimonial profiles. We vary caste identity across Brahmin, Kshatriya, Vaishya, Shudra, and Dalit, and income across five buckets, and evaluate five LLM families (GPT, Gemini, Llama, Qwen, and BharatGPT). Models are prompted to assess profiles along dimensions of social acceptance, marital stability, and cultural compatibility. Our analysis reveals consistent hierarchical patterns across models: same-caste matches are rated most favorably, with average ratings up to 25% higher (on a 10-point scale) than inter-caste matches, which are further ordered according to traditional caste hierarchy. These findings highlight how existing caste hierarchies are reproduced in LLM decision-making and underscore the need for culturally grounded evaluation and intervention strategies in AI systems deployed in socially sensitive domains, where such systems risk reinforcing historical forms of exclusion.
ChartEditBench: Evaluating Grounded Multi-Turn Chart Editing in Multimodal Language Models
Feb 17, 2026While Multimodal Large Language Models (MLLMs) perform strongly on single-turn chart generation, their ability to support real-world exploratory data analysis remains underexplored. In practice, users iteratively refine visualizations through multi-turn interactions that require maintaining common ground, tracking prior edits, and adapting to evolving preferences. We introduce ChartEditBench, a benchmark for incremental, visually grounded chart editing via code, comprising 5,000 difficulty-controlled modification chains and a rigorously human-verified subset. Unlike prior one-shot benchmarks, ChartEditBench evaluates sustained, context-aware editing. We further propose a robust evaluation framework that mitigates limitations of LLM-as-a-Judge metrics by integrating execution-based fidelity checks, pixel-level visual similarity, and logical code verification. Experiments with state-of-the-art MLLMs reveal substantial degradation in multi-turn settings due to error accumulation and breakdowns in shared context, with strong performance on stylistic edits but frequent execution failures on data-centric transformations. ChartEditBench, establishes a challenging testbed for grounded, intent-aware multimodal programming.
PragWorld: A Benchmark Evaluating LLMs' Local World Model under Minimal Linguistic Alterations and Conversational Dynamics
Nov 17, 2025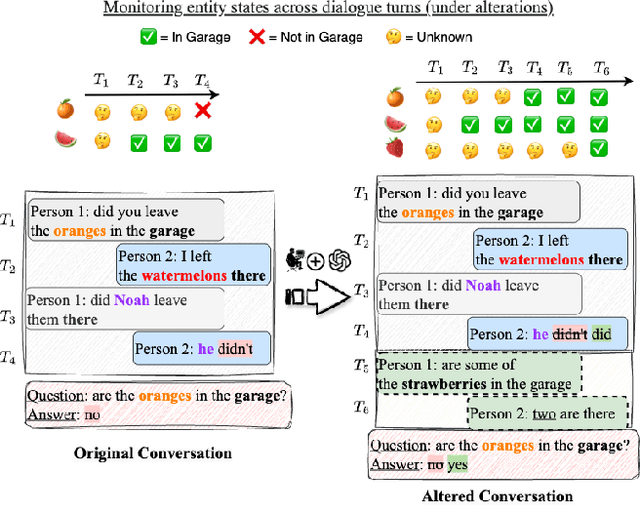
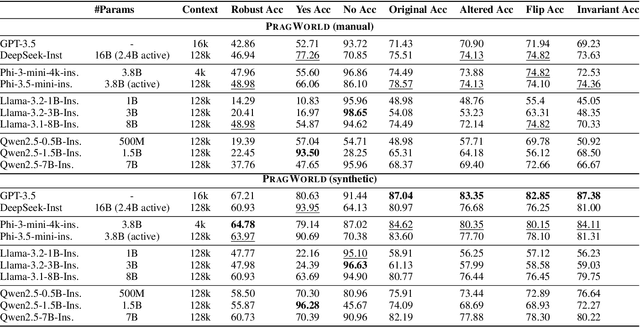
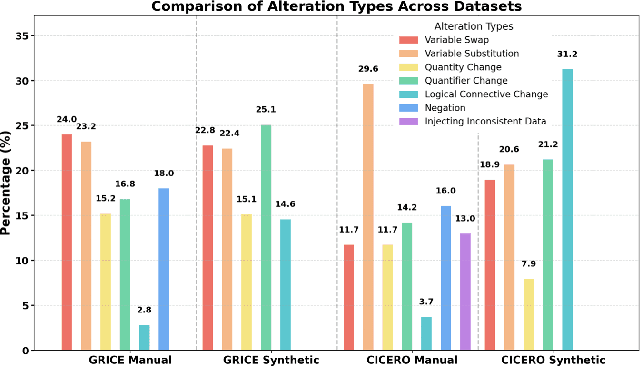
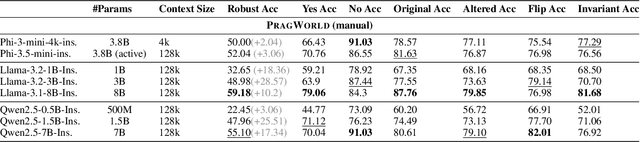
Real-world conversations are rich with pragmatic elements, such as entity mentions, references, and implicatures. Understanding such nuances is a requirement for successful natural communication, and often requires building a local world model which encodes such elements and captures the dynamics of their evolving states. However, it is not well-understood whether language models (LMs) construct or maintain a robust implicit representation of conversations. In this work, we evaluate the ability of LMs to encode and update their internal world model in dyadic conversations and test their malleability under linguistic alterations. To facilitate this, we apply seven minimal linguistic alterations to conversations sourced from popular datasets and construct two benchmarks comprising yes-no questions. We evaluate a wide range of open and closed source LMs and observe that they struggle to maintain robust accuracy. Our analysis unveils that LMs struggle to memorize crucial details, such as tracking entities under linguistic alterations to conversations. We then propose a dual-perspective interpretability framework which identifies transformer layers that are useful or harmful and highlights linguistic alterations most influenced by harmful layers, typically due to encoding spurious signals or relying on shortcuts. Inspired by these insights, we propose two layer-regularization based fine-tuning strategies that suppress the effect of the harmful layers.
MetaLint: Generalizable Idiomatic Code Quality Analysis through Instruction-Following and Easy-to-Hard Generalization
Jul 15, 2025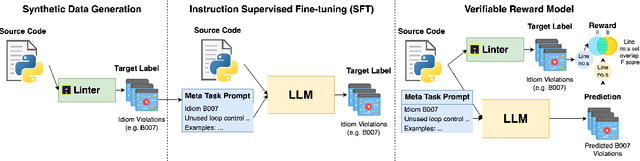
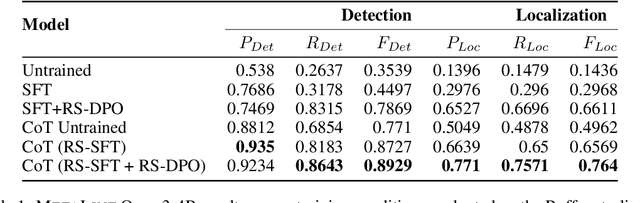
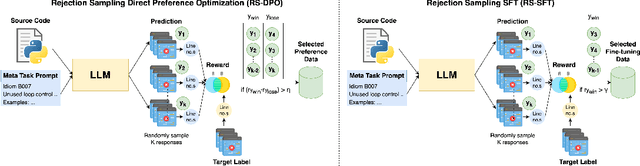

Large Language Models, though successful in code generation, struggle with code quality analysis because they are limited by static training data and can't easily adapt to evolving best practices. We introduce MetaLint, a new instruction-following framework that formulates code quality analysis as the task of detecting and fixing problematic semantic code fragments or code idioms based on high-level specifications. Unlike conventional approaches that train models on static, rule-based data, MetaLint employs instruction tuning on synthetic linter-generated data to support easy-to-hard generalization, enabling models to adapt to novel or complex code patterns without retraining. To evaluate this, we construct a benchmark of challenging idioms inspired by real-world coding standards such as Python Enhancement Proposals (PEPs) and assess whether MetaLint-trained models reason adaptively or simply memorize. Our results show that MetaLint improves generalization to unseen PEP idioms, achieving a 70.37% F-score on idiom detection with the highest recall (70.43%) among all evaluated models. It also achieves 26.73% on localization, competitive for its 4B parameter size and comparable to larger state-of-the-art models like o3-mini, highlighting its potential for future-proof code quality analysis.
PBEBench: A Multi-Step Programming by Examples Reasoning Benchmark inspired by Historical Linguistics
May 29, 2025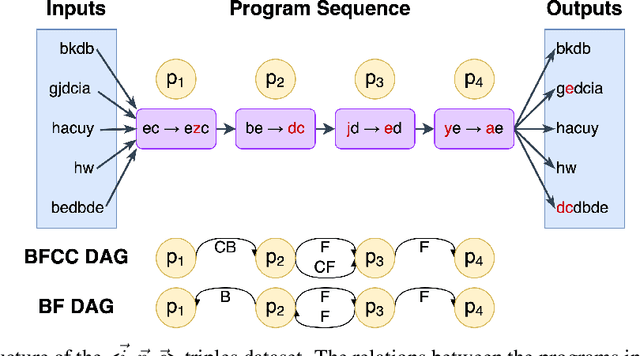
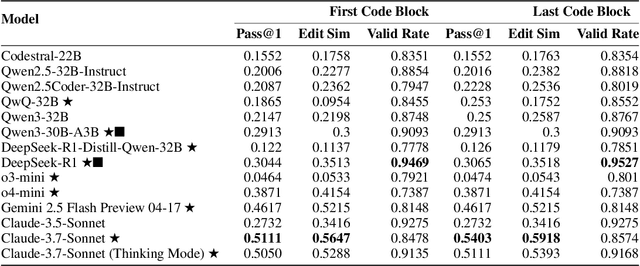
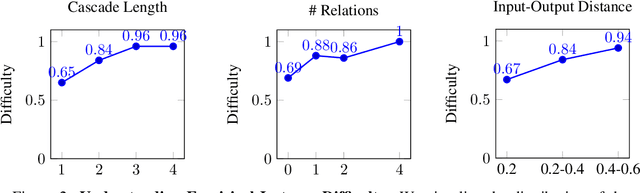
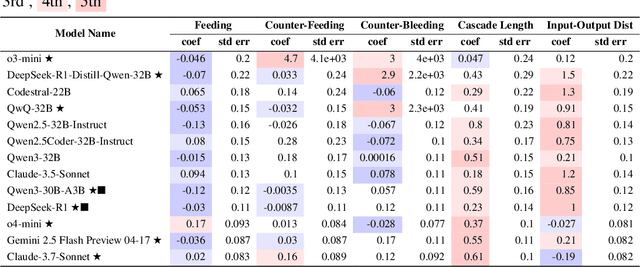
Recently, long chain of thought (LCoT), Large Language Models (LLMs), have taken the machine learning world by storm with their breathtaking reasoning capabilities. However, are the abstract reasoning abilities of these models general enough for problems of practical importance? Unlike past work, which has focused mainly on math, coding, and data wrangling, we focus on a historical linguistics-inspired inductive reasoning problem, formulated as Programming by Examples. We develop a fully automated pipeline for dynamically generating a benchmark for this task with controllable difficulty in order to tackle scalability and contamination issues to which many reasoning benchmarks are subject. Using our pipeline, we generate a test set with nearly 1k instances that is challenging for all state-of-the-art reasoning LLMs, with the best model (Claude-3.7-Sonnet) achieving a mere 54% pass rate, demonstrating that LCoT LLMs still struggle with a class or reasoning that is ubiquitous in historical linguistics as well as many other domains.
An Empirical Study on Strong-Weak Model Collaboration for Repo-level Code Generation
May 26, 2025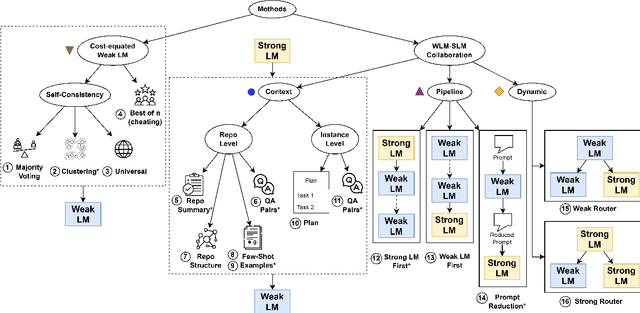
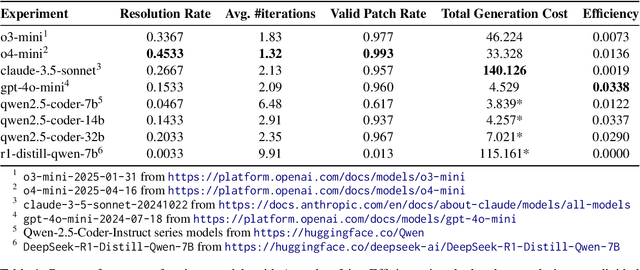
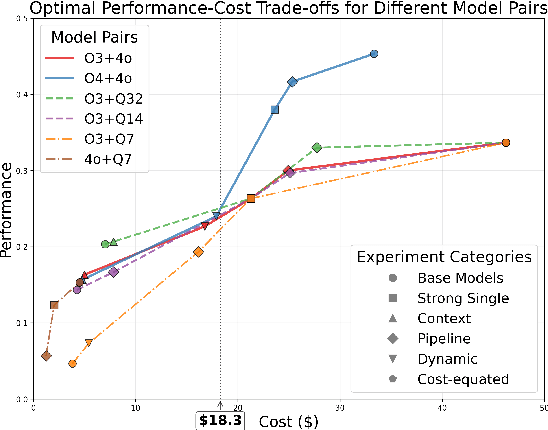
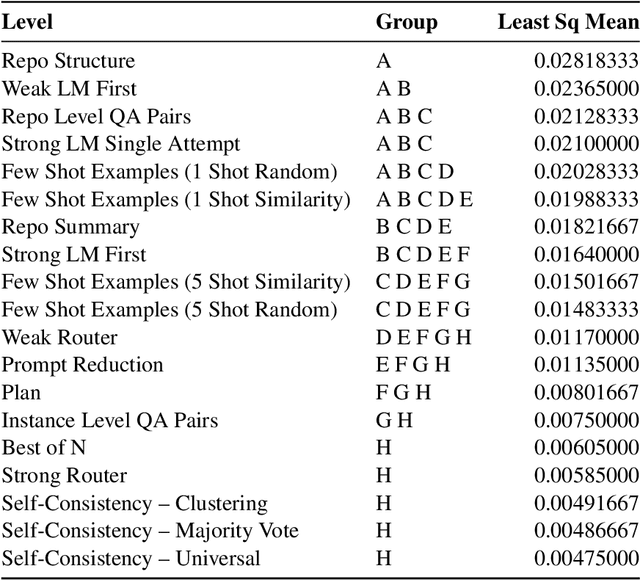
We study cost-efficient collaboration between strong and weak language models for repository-level code generation, where the weak model handles simpler tasks at lower cost, and the most challenging tasks are delegated to the strong model. While many works propose architectures for this task, few analyze performance relative to cost. We evaluate a broad spectrum of collaboration strategies: context-based, pipeline-based, and dynamic, on GitHub issue resolution. Our most effective collaborative strategy achieves equivalent performance to the strong model while reducing the cost by 40%. Based on our findings, we offer actionable guidelines for choosing collaboration strategies under varying budget and performance constraints. Our results show that strong-weak collaboration substantially boosts the weak model's performance at a fraction of the cost, pipeline and context-based methods being most efficient. We release the code for our work at https://github.com/shubhamrgandhi/codegen-strong-weak-collab.
Programming by Examples Meets Historical Linguistics: A Large Language Model Based Approach to Sound Law Induction
Jan 27, 2025



Historical linguists have long written "programs" that convert reconstructed words in an ancestor language into their attested descendants via ordered string rewrite functions (called sound laws) However, writing these programs is time-consuming, motivating the development of automated Sound Law Induction (SLI) which we formulate as Programming by Examples (PBE) with Large Language Models (LLMs) in this paper. While LLMs have been effective for code generation, recent work has shown that PBE is challenging but improvable by fine-tuning, especially with training data drawn from the same distribution as evaluation data. In this paper, we create a conceptual framework of what constitutes a "similar distribution" for SLI and propose four kinds of synthetic data generation methods with varying amounts of inductive bias to investigate what leads to the best performance. Based on the results we create a SOTA open-source model for SLI as PBE (+6% pass rate with a third of the parameters of the second-best LLM) and also highlight exciting future directions for PBE research.
CRScore: Grounding Automated Evaluation of Code Review Comments in Code Claims and Smells
Sep 29, 2024
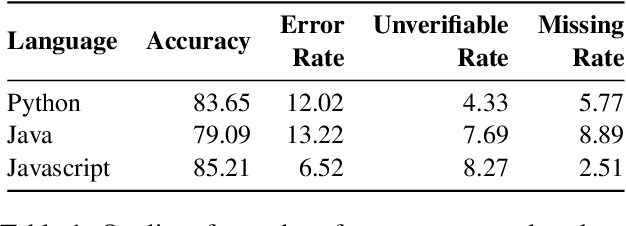
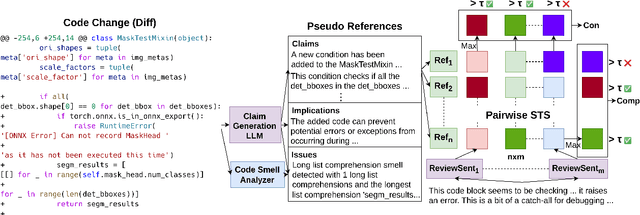
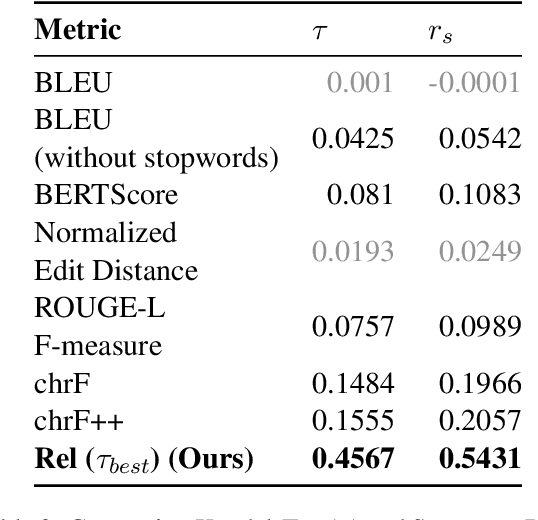
The task of automated code review has recently gained a lot of attention from the machine learning community. However, current review comment evaluation metrics rely on comparisons with a human-written reference for a given code change (also called a diff), even though code review is a one-to-many problem like generation and summarization with many "valid reviews" for a diff. To tackle these issues we develop a CRScore - a reference-free metric to measure dimensions of review quality like conciseness, comprehensiveness, and relevance. We design CRScore to evaluate reviews in a way that is grounded in claims and potential issues detected in the code by LLMs and static analyzers. We demonstrate that CRScore can produce valid, fine-grained scores of review quality that have the greatest alignment with human judgment (0.54 Spearman correlation) and are more sensitive than reference-based metrics. We also release a corpus of 2.6k human-annotated review quality scores for machine-generated and GitHub review comments to support the development of automated metrics.
Can Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
Generating Situated Reflection Triggers about Alternative Solution Paths: A Case Study of Generative AI for Computer-Supported Collaborative Learning
Apr 28, 2024



An advantage of Large Language Models (LLMs) is their contextualization capability - providing different responses based on student inputs like solution strategy or prior discussion, to potentially better engage students than standard feedback. We present a design and evaluation of a proof-of-concept LLM application to offer students dynamic and contextualized feedback. Specifically, we augment an Online Programming Exercise bot for a college-level Cloud Computing course with ChatGPT, which offers students contextualized reflection triggers during a collaborative query optimization task in database design. We demonstrate that LLMs can be used to generate highly situated reflection triggers that incorporate details of the collaborative discussion happening in context. We discuss in depth the exploration of the design space of the triggers and their correspondence with the learning objectives as well as the impact on student learning in a pilot study with 34 students.