 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBEBench: A Multi-Step Programming by Examples Reasoning Benchmark inspired by Historical Linguistics
May 29, 2025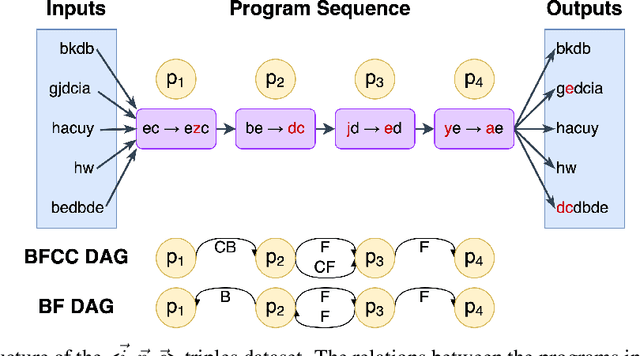
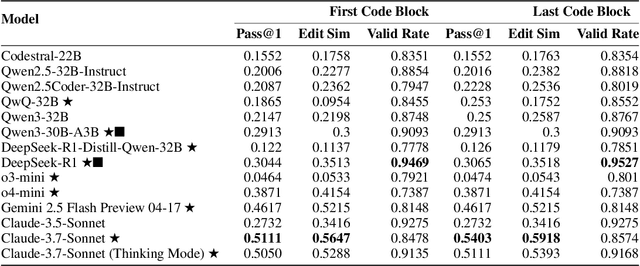
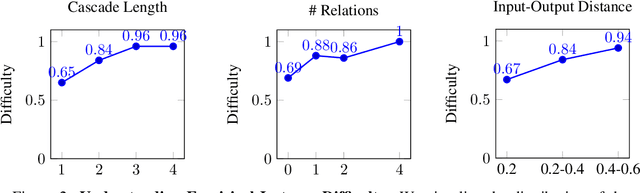
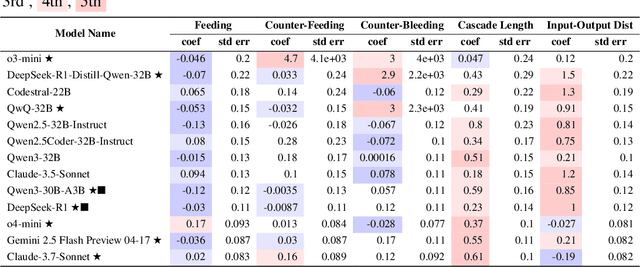
Recently, long chain of thought (LCoT), Large Language Models (LLMs), have taken the machine learning world by storm with their breathtaking reasoning capabilities. However, are the abstract reasoning abilities of these models general enough for problems of practical importance? Unlike past work, which has focused mainly on math, coding, and data wrangling, we focus on a historical linguistics-inspired inductive reasoning problem, formulated as Programming by Examples. We develop a fully automated pipeline for dynamically generating a benchmark for this task with controllable difficulty in order to tackle scalability and contamination issues to which many reasoning benchmarks are subject. Using our pipeline, we generate a test set with nearly 1k instances that is challenging for all state-of-the-art reasoning LLMs, with the best model (Claude-3.7-Sonnet) achieving a mere 54% pass rate, demonstrating that LCoT LLMs still struggle with a class or reasoning that is ubiquitous in historical linguistics as well as many other domains.
Program-Aided Reasoners Know What They Know
Nov 16, 2023Prior work shows that program-aided reasoning, in which large language models (LLMs) are combined with programs written in programming languages such as Python, can significantly improve accuracy on various reasoning tasks. However, while accuracy is essential, it is also important for such reasoners to "know what they know", which can be quantified through the calibration of the model. In this paper, we compare the calibration of Program Aided Language Models (PAL) and text-based Chain-of-thought (COT) prompting techniques over 5 datasets and 2 model types: LLaMA models and OpenAI models. Our results indicate that PAL leads to improved calibration in 75% of the instances. Our analysis uncovers that prompting styles that produce lesser diversity in generations also have more calibrated results, and thus we also experiment with inducing lower generation diversity using temperature scaling and find that for certain temperatures, PAL is not only more accurate but is also more calibrated than COT. Overall, we demonstrate that, in the majority of cases, program-aided reasoners better know what they know than text-based counterparts.
SummQA at MEDIQA-Chat 2023:In-Context Learning with GPT-4 for Medical Summarization
Jun 30, 2023



Medical dialogue summarization is challenging due to the unstructured nature of medical conversations, the use of medical terminology in gold summaries, and the need to identify key information across multiple symptom sets. We present a novel system for the Dialogue2Note Medical Summarization tasks in the MEDIQA 2023 Shared Task. Our approach for section-wise summarization (Task A) is a two-stage process of selecting semantically similar dialogues and using the top-k similar dialogues as in-context examples for GPT-4. For full-note summarization (Task B), we use a similar solution with k=1. We achieved 3rd place in Task A (2nd among all teams), 4th place in Task B Division Wise Summarization (2nd among all teams), 15th place in Task A Section Header Classification (9th among all teams), and 8th place among all teams in Task B. Our results highlight the effectiveness of few-shot prompting for this task, though we also identify several weaknesses of prompting-based approaches. We compare GPT-4 performance with several finetuned baselines. We find that GPT-4 summaries are more abstractive and shorter. We make our code publicly available.
Digital Image Forensics using Deep Learning
Oct 14, 2022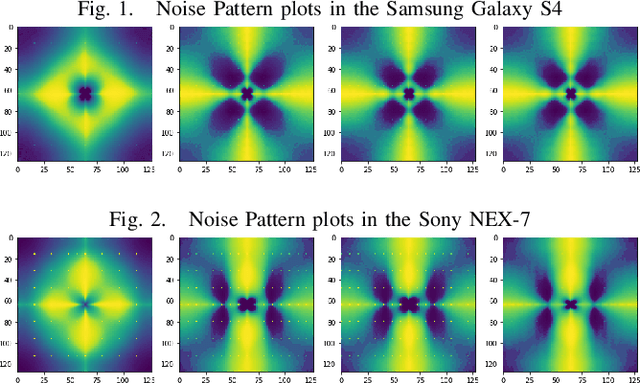
During the investigation of criminal activity when evidence is available, the issue at hand is determining the credibility of the video and ascertaining that the video is real. Today, one way to authenticate the footage is to identify the camera that was used to capture the image or video in question. While a very common way to do this is by using image meta-data, this data can easily be falsified by changing the video content or even splicing together content from two different cameras. Given the multitude of solutions proposed to this problem, it is yet to be sufficiently solved. The aim of our project is to build an algorithm that identifies which camera was used to capture an image using traces of information left intrinsically in the image, using filters, followed by a deep neural network on these filters. Solving this problem would have a big impact on the verification of evidence used in criminal and civil trials and even news reporting.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020
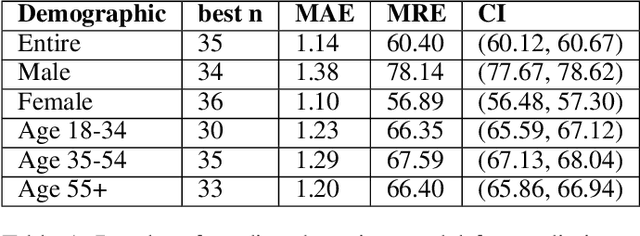
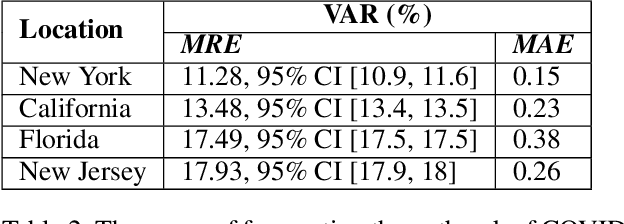
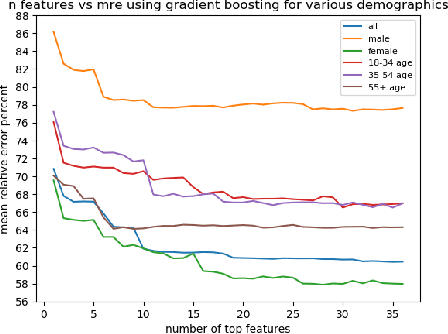
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.