 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring, Modeling, and Helping People Account for Privacy Risks in Online Self-Disclosures with AI
Dec 19, 2024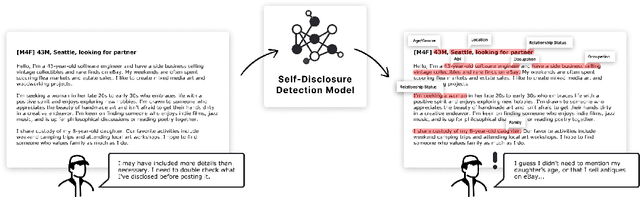
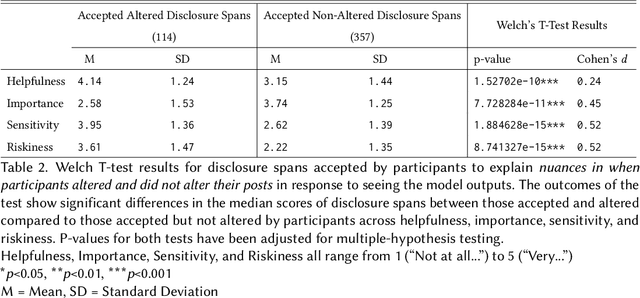
In pseudonymous online fora like Reddit, the benefits of self-disclosure are often apparent to users (e.g., I can vent about my in-laws to understanding strangers), but the privacy risks are more abstract (e.g., will my partner be able to tell that this is me?). Prior work has sought to develop natural language processing (NLP) tools that help users identify potentially risky self-disclosures in their text, but none have been designed for or evaluated with the users they hope to protect. Absent this assessment, these tools will be limited by the social-technical gap: users need assistive tools that help them make informed decisions, not paternalistic tools that tell them to avoid self-disclosure altogether. To bridge this gap, we conducted a study with N = 21 Reddit users; we had them use a state-of-the-art NLP disclosure detection model on two of their authored posts and asked them questions to understand if and how the model helped, where it fell short, and how it could be improved to help them make more informed decisions. Despite its imperfections, users responded positively to the model and highlighted its use as a tool that can help them catch mistakes, inform them of risks they were unaware of, and encourage self-reflection. However, our work also shows how, to be useful and usable, AI for supporting privacy decision-making must account for posting context, disclosure norms, and users' lived threat models, and provide explanations that help contextualize detected risks.
AI-LieDar: Examine the Trade-off Between Utility and Truthfulness in LLM Agents
Sep 13, 2024


To be safely and successfully deployed, LLMs must simultaneously satisfy truthfulness and utility goals. Yet, often these two goals compete (e.g., an AI agent assisting a used car salesman selling a car with flaws), partly due to ambiguous or misleading user instructions. We propose AI-LieDar, a framework to study how LLM-based agents navigate scenarios with utility-truthfulness conflicts in a multi-turn interactive setting. We design a set of realistic scenarios where language agents are instructed to achieve goals that are in conflict with being truthful during a multi-turn conversation with simulated human agents. To evaluate the truthfulness at large scale, we develop a truthfulness detector inspired by psychological literature to assess the agents' responses. Our experiment demonstrates that all models are truthful less than 50% of the time, although truthfulness and goal achievement (utility) rates vary across models. We further test the steerability of LLMs towards truthfulness, finding that models follow malicious instructions to deceive, and even truth-steered models can still lie. These findings reveal the complex nature of truthfulness in LLMs and underscore the importance of further research to ensure the safe and reliable deployment of LLMs and AI agents.
Program-Aided Reasoners Know What They Know
Nov 16, 2023Prior work shows that program-aided reasoning, in which large language models (LLMs) are combined with programs written in programming languages such as Python, can significantly improve accuracy on various reasoning tasks. However, while accuracy is essential, it is also important for such reasoners to "know what they know", which can be quantified through the calibration of the model. In this paper, we compare the calibration of Program Aided Language Models (PAL) and text-based Chain-of-thought (COT) prompting techniques over 5 datasets and 2 model types: LLaMA models and OpenAI models. Our results indicate that PAL leads to improved calibration in 75% of the instances. Our analysis uncovers that prompting styles that produce lesser diversity in generations also have more calibrated results, and thus we also experiment with inducing lower generation diversity using temperature scaling and find that for certain temperatures, PAL is not only more accurate but is also more calibrated than COT. Overall, we demonstrate that, in the majority of cases, program-aided reasoners better know what they know than text-based counterparts.
Reducing Privacy Risks in Online Self-Disclosures with Language Models
Nov 16, 2023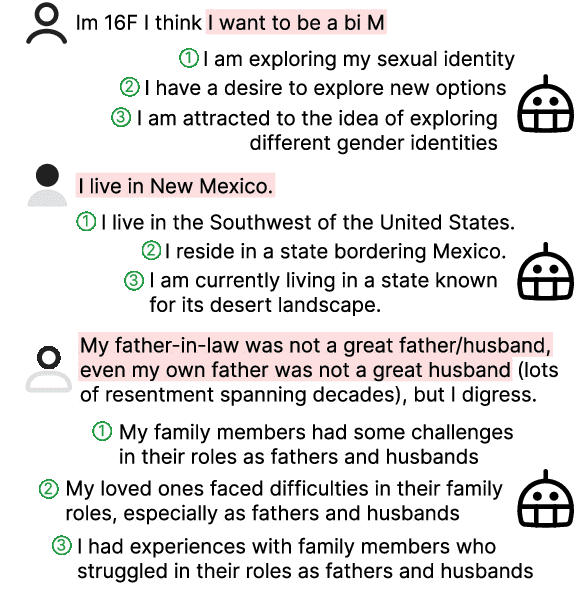

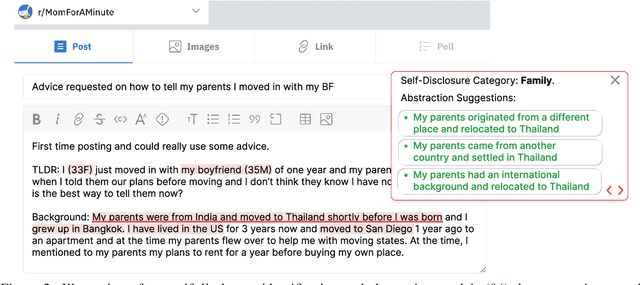
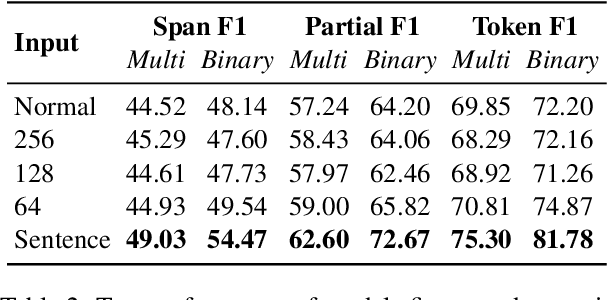
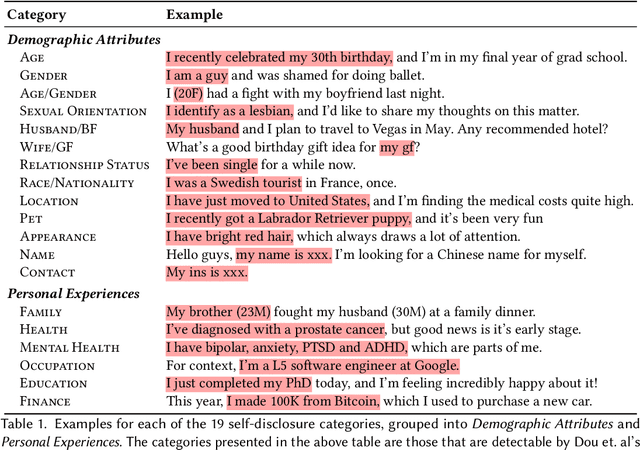
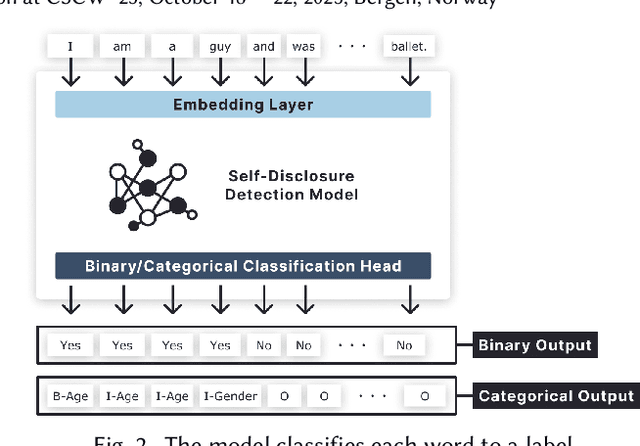
Self-disclosure, while being common and rewarding in social media interaction, also poses privacy risks. In this paper, we take the initiative to protect the user-side privacy associated with online self-disclosure through identification and abstraction. We develop a taxonomy of 19 self-disclosure categories, and curate a large corpus consisting of 4.8K annotated disclosure spans. We then fine-tune a language model for identification, achieving over 75% in Token F$_1$. We further conduct a HCI user study, with 82\% of participants viewing the model positively, highlighting its real world applicability. Motivated by the user feedback, we introduce the task of self-disclosure abstraction. We experiment with both one-span abstraction and three-span abstraction settings, and explore multiple fine-tuning strategies. Our best model can generate diverse abstractions that moderately reduce privacy risks while maintaining high utility according to human evaluation.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023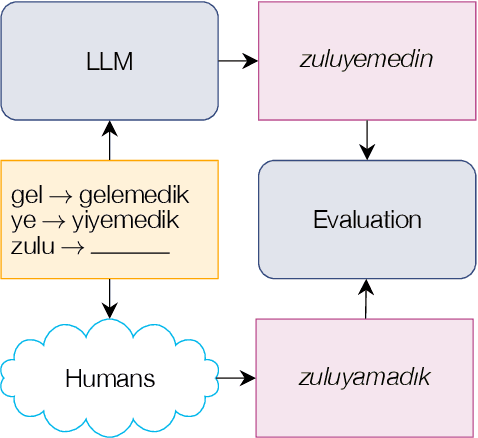
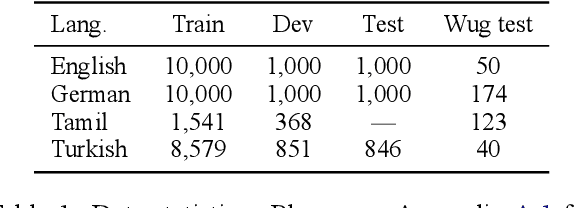
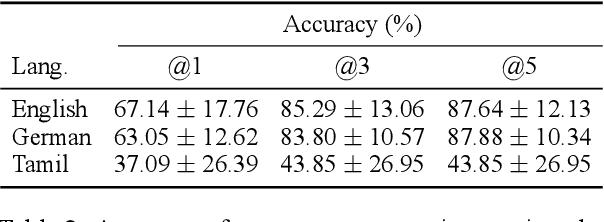
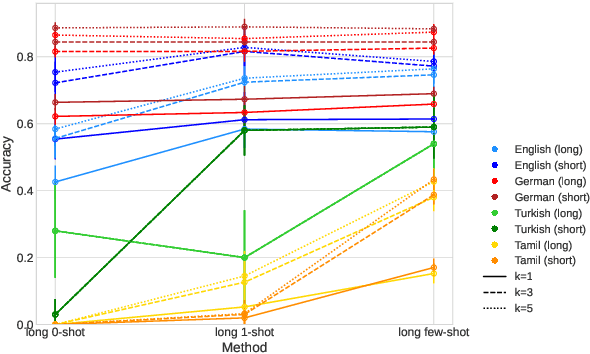
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.
Ceasing hate withMoH: Hate Speech Detection in Hindi-English Code-Switched Language
Oct 18, 2021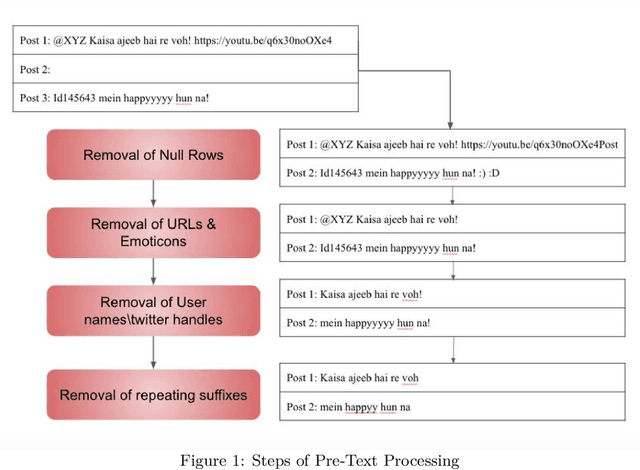


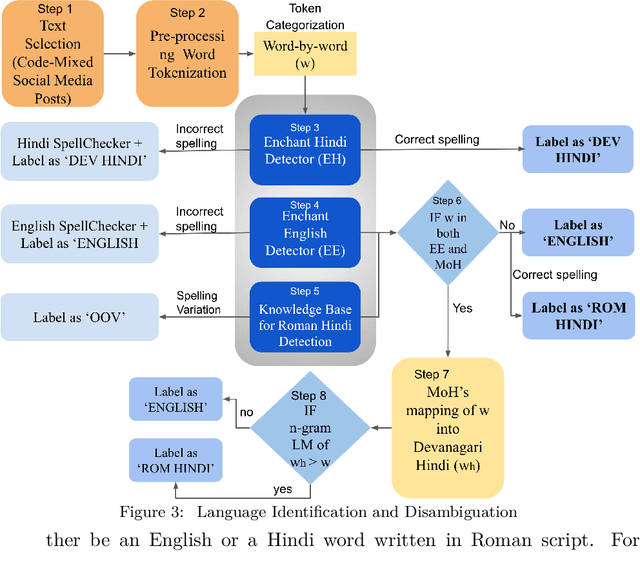
Social media has become a bedrock for people to voice their opinions worldwide. Due to the greater sense of freedom with the anonymity feature, it is possible to disregard social etiquette online and attack others without facing severe consequences, inevitably propagating hate speech. The current measures to sift the online content and offset the hatred spread do not go far enough. One factor contributing to this is the prevalence of regional languages in social media and the paucity of language flexible hate speech detectors. The proposed work focuses on analyzing hate speech in Hindi-English code-switched language. Our method explores transformation techniques to capture precise text representation. To contain the structure of data and yet use it with existing algorithms, we developed MoH or Map Only Hindi, which means "Love" in Hindi. MoH pipeline consists of language identification, Roman to Devanagari Hindi transliteration using a knowledge base of Roman Hindi words. Finally, it employs the fine-tuned Multilingual Bert and MuRIL language models. We conducted several quantitative experiment studies on three datasets and evaluated performance using Precision, Recall, and F1 metrics. The first experiment studies MoH mapped text's performance with classical machine learning models and shows an average increase of 13% in F1 scores. The second compares the proposed work's scores with those of the baseline models and offers a rise in performance by 6%. Finally, the third reaches the proposed MoH technique with various data simulations using the existing transliteration library. Here, MoH outperforms the rest by 15%. Our results demonstrate a significant improvement in the state-of-the-art scores on all three datasets.
Cluster Based Deep Contextual Reinforcement Learning for top-k Recommendations
Nov 29, 2020

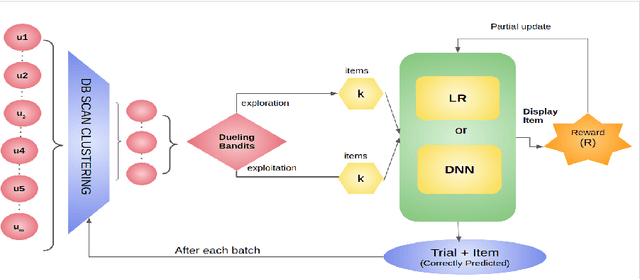
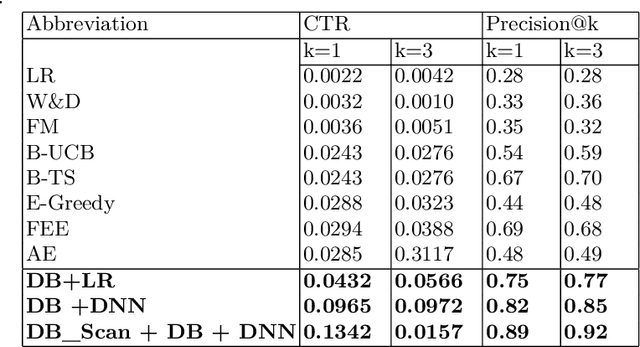
Rapid advancements in the E-commerce sector over the last few decades have led to an imminent need for personalised, efficient and dynamic recommendation systems. To sufficiently cater to this need, we propose a novel method for generating top-k recommendations by creating an ensemble of clustering with reinforcement learning. We have incorporated DB Scan clustering to tackle vast item space, hence in-creasing the efficiency multi-fold. Moreover, by using deep contextual reinforcement learning, our proposed work leverages the user features to its full potential. With partial updates and batch updates, the model learns user patterns continuously. The Duelling Bandit based exploration provides robust exploration as compared to the state-of-art strategies due to its adaptive nature. Detailed experiments conducted on a public dataset verify our claims about the efficiency of our technique as com-pared to existing techniques.
MixBoost: Synthetic Oversampling with Boosted Mixup for Handling Extreme Imbalance
Sep 03, 2020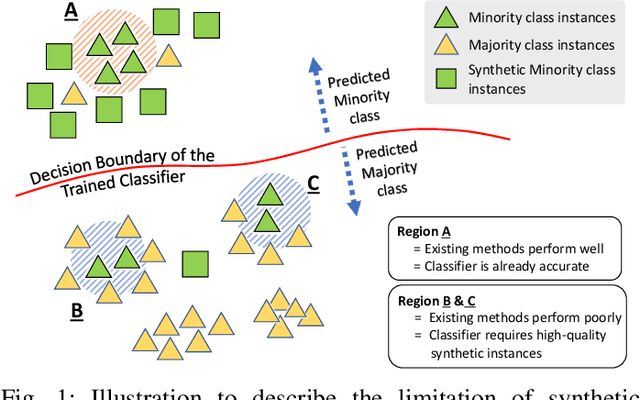
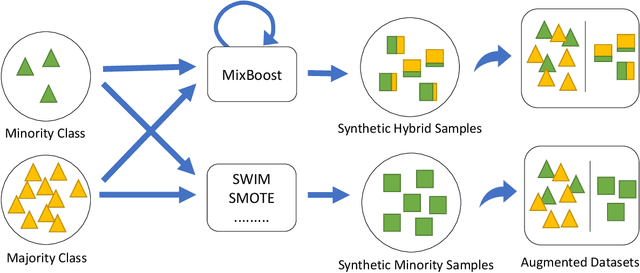
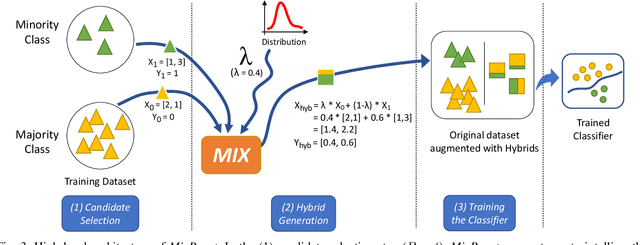
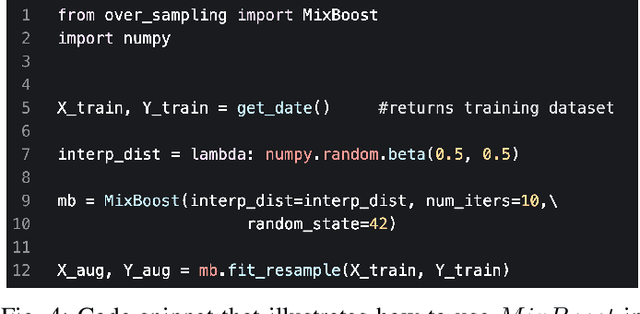
Training a classification model on a dataset where the instances of one class outnumber those of the other class is a challenging problem. Such imbalanced datasets are standard in real-world situations such as fraud detection, medical diagnosis, and computational advertising. We propose an iterative data augmentation method, MixBoost, which intelligently selects (Boost) and then combines (Mix) instances from the majority and minority classes to generate synthetic hybrid instances that have characteristics of both classes. We evaluate MixBoost on 20 benchmark datasets, show that it outperforms existing approaches, and test its efficacy through significance testing. We also present ablation studies to analyze the impact of the different components of MixBoost.
Calling Out Bluff: Attacking the Robustness of Automatic Scoring Systems with Simple Adversarial Testing
Jul 14, 2020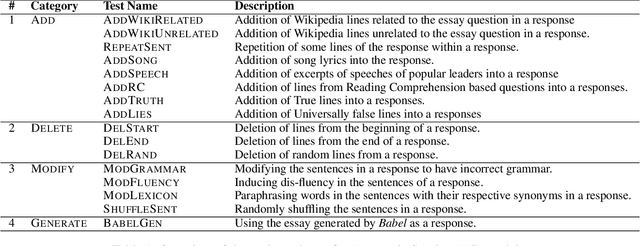

A significant progress has been made in deep-learning based Automatic Essay Scoring (AES) systems in the past two decades. The performance commonly measured by the standard performance metrics like Quadratic Weighted Kappa (QWK), and accuracy points to the same. However, testing on common-sense adversarial examples of these AES systems reveal their lack of natural language understanding capability. Inspired by common student behaviour during examinations, we propose a task agnostic adversarial evaluation scheme for AES systems to test their natural language understanding capabilities and overall robustness.