 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating Gender Cues in Academic Recommendation Letters: An Interpretability Case Study
Apr 14, 2026Letters of recommendation (LoRs) can carry patterns of implicitly gendered language that can inadvertently influence downstream decisions, e.g. in hiring and admissions. In this work, we investigate the extent to which Transformer-based encoder models as well as Large Language Models (LLMs) can infer the gender of applicants in academic LoRs submitted to an U.S. medical-residency program after explicit identifiers like names and pronouns are de-gendered. While using three models (DistilBERT, RoBERTa, and Llama 2) to classify the gender of anonymized and de-gendered LoRs, significant gender leakage was observed as evident from up to 68% classification accuracy. Text interpretation methods, like TF-IDF and SHAP, demonstrate that certain linguistic patterns are strong proxies for gender, e.g. "emotional'' and "humanitarian'' are commonly associated with LoRs from female applicants. As an experiment in creating truly gender-neutral LoRs, these implicit gender cues were remove resulting in a drop of up to 5.5% accuracy and 2.7% macro $F_1$ score on re-training the classifiers. However, applicant gender prediction still remains better than chance. In this case study, our findings highlight that 1) LoRs contain gender-identifying cues that are hard to remove and may activate bias in decision-making and 2) while our technical framework may be a concrete step toward fairer academic and professional evaluations, future work is needed to interrogate the role that gender plays in LoR review. Taken together, our findings motivate upstream auditing of evaluative text in real-world academic letters of recommendation as a necessary complement to model-level fairness interventions.
Analyzing Latent Concepts in Code Language Models
Oct 01, 2025Interpreting the internal behavior of large language models trained on code remains a critical challenge, particularly for applications demanding trust, transparency, and semantic robustness. We propose Code Concept Analysis (CoCoA): a global post-hoc interpretability framework that uncovers emergent lexical, syntactic, and semantic structures in a code language model's representation space by clustering contextualized token embeddings into human-interpretable concept groups. We propose a hybrid annotation pipeline that combines static analysis tool-based syntactic alignment with prompt-engineered large language models (LLMs), enabling scalable labeling of latent concepts across abstraction levels. We analyse the distribution of concepts across layers and across three finetuning tasks. Emergent concept clusters can help identify unexpected latent interactions and be used to identify trends and biases within the model's learned representations. We further integrate LCA with local attribution methods to produce concept-grounded explanations, improving the coherence and interpretability of token-level saliency. Empirical evaluations across multiple models and tasks show that LCA discovers concepts that remain stable under semantic-preserving perturbations (average Cluster Sensitivity Index, CSI = 0.288) and evolve predictably with fine-tuning. In a user study, concept-augmented explanations disambiguate token roles. In a user study on the programming-language classification task, concept-augmented explanations disambiguated token roles and improved human-centric explainability by 37 percentage points compared with token-level attributions using Integrated Gradients.
Argumentative Stance Prediction: An Exploratory Study on Multimodality and Few-Shot Learning
Oct 11, 2023To advance argumentative stance prediction as a multimodal problem, the First Shared Task in Multimodal Argument Mining hosted stance prediction in crucial social topics of gun control and abortion. Our exploratory study attempts to evaluate the necessity of images for stance prediction in tweets and compare out-of-the-box text-based large-language models (LLM) in few-shot settings against fine-tuned unimodal and multimodal models. Our work suggests an ensemble of fine-tuned text-based language models (0.817 F1-score) outperforms both the multimodal (0.677 F1-score) and text-based few-shot prediction using a recent state-of-the-art LLM (0.550 F1-score). In addition to the differences in performance, our findings suggest that the multimodal models tend to perform better when image content is summarized as natural language over their native pixel structure and, using in-context examples improves few-shot performance of LLMs.
Interpreting Pretrained Source-code Models using Neuron Redundancy Analyses
May 01, 2023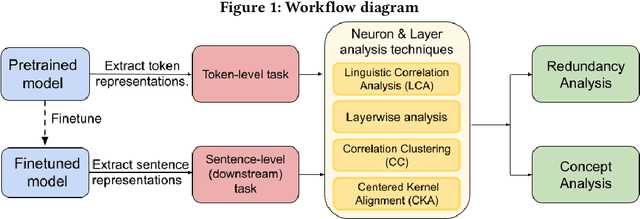



Neural code intelligence models continue to be 'black boxes' to the human programmer. This opacity limits their application towards code intelligence tasks, particularly for applications like vulnerability detection where a model's reliance on spurious correlations can be safety-critical. We introduce a neuron-level approach to interpretability of neural code intelligence models which eliminates redundancy due to highly similar or task-irrelevant neurons within these networks. We evaluate the remaining important neurons using probing classifiers which are often used to ascertain whether certain properties have been encoded within the latent representations of neural intelligence models. However, probing accuracies may be artificially inflated due to repetitive and deterministic nature of tokens in code datasets. Therefore, we adapt the selectivity metric originally introduced in NLP to account for probe memorization, to formulate our source-code probing tasks. Through our neuron analysis, we find that more than 95\% of the neurons are redundant wrt. our code intelligence tasks and can be eliminated without significant loss in accuracy. We further trace individual and subsets of important neurons to specific code properties which could be used to influence model predictions. We demonstrate that it is possible to identify 'number' neurons, 'string' neurons, and higher level 'text' neurons which are responsible for specific code properties. This could potentially be used to modify neurons responsible for predictions based on incorrect signals. Additionally, the distribution and concentration of the important neurons within different source code embeddings can be used as measures of task complexity, to compare source-code embeddings and guide training choices for transfer learning over similar tasks.
Ceasing hate withMoH: Hate Speech Detection in Hindi-English Code-Switched Language
Oct 18, 2021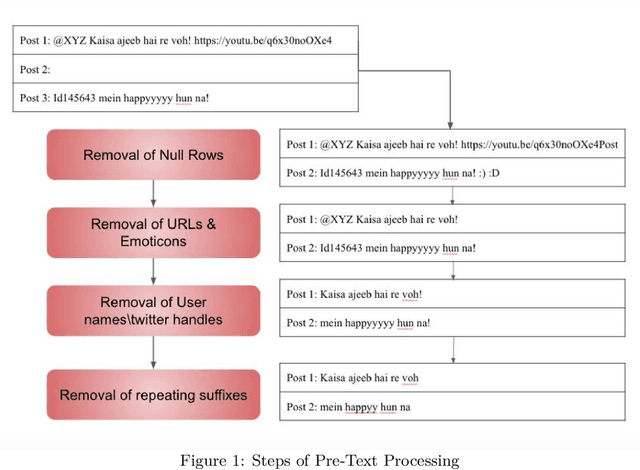


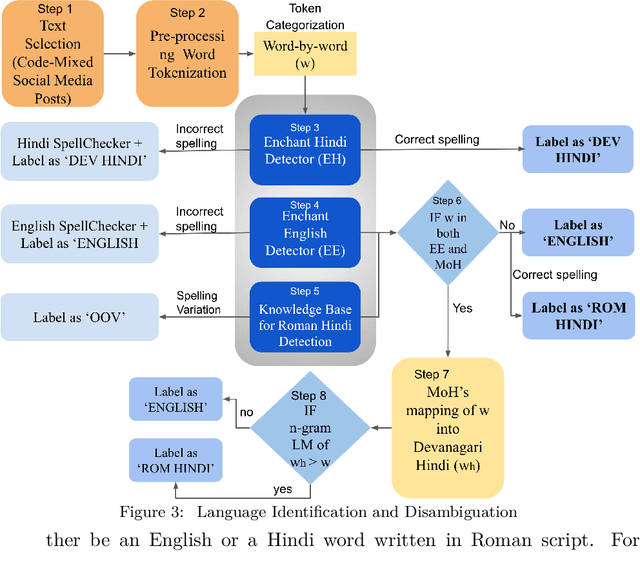
Social media has become a bedrock for people to voice their opinions worldwide. Due to the greater sense of freedom with the anonymity feature, it is possible to disregard social etiquette online and attack others without facing severe consequences, inevitably propagating hate speech. The current measures to sift the online content and offset the hatred spread do not go far enough. One factor contributing to this is the prevalence of regional languages in social media and the paucity of language flexible hate speech detectors. The proposed work focuses on analyzing hate speech in Hindi-English code-switched language. Our method explores transformation techniques to capture precise text representation. To contain the structure of data and yet use it with existing algorithms, we developed MoH or Map Only Hindi, which means "Love" in Hindi. MoH pipeline consists of language identification, Roman to Devanagari Hindi transliteration using a knowledge base of Roman Hindi words. Finally, it employs the fine-tuned Multilingual Bert and MuRIL language models. We conducted several quantitative experiment studies on three datasets and evaluated performance using Precision, Recall, and F1 metrics. The first experiment studies MoH mapped text's performance with classical machine learning models and shows an average increase of 13% in F1 scores. The second compares the proposed work's scores with those of the baseline models and offers a rise in performance by 6%. Finally, the third reaches the proposed MoH technique with various data simulations using the existing transliteration library. Here, MoH outperforms the rest by 15%. Our results demonstrate a significant improvement in the state-of-the-art scores on all three datasets.