 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Emotion-Aware Multi-Task Approach to Fake News and Rumour Detection using Transfer Learning
Dec 07, 2022Social networking sites, blogs, and online articles are instant sources of news for internet users globally. However, in the absence of strict regulations mandating the genuineness of every text on social media, it is probable that some of these texts are fake news or rumours. Their deceptive nature and ability to propagate instantly can have an adverse effect on society. This necessitates the need for more effective detection of fake news and rumours on the web. In this work, we annotate four fake news detection and rumour detection datasets with their emotion class labels using transfer learning. We show the correlation between the legitimacy of a text with its intrinsic emotion for fake news and rumour detection, and prove that even within the same emotion class, fake and real news are often represented differently, which can be used for improved feature extraction. Based on this, we propose a multi-task framework for fake news and rumour detection, predicting both the emotion and legitimacy of the text. We train a variety of deep learning models in single-task and multi-task settings for a more comprehensive comparison. We further analyze the performance of our multi-task approach for fake news detection in cross-domain settings to verify its efficacy for better generalization across datasets, and to verify that emotions act as a domain-independent feature. Experimental results verify that our multi-task models consistently outperform their single-task counterparts in terms of accuracy, precision, recall, and F1 score, both for in-domain and cross-domain settings. We also qualitatively analyze the difference in performance in single-task and multi-task learning models.
Ceasing hate withMoH: Hate Speech Detection in Hindi-English Code-Switched Language
Oct 18, 2021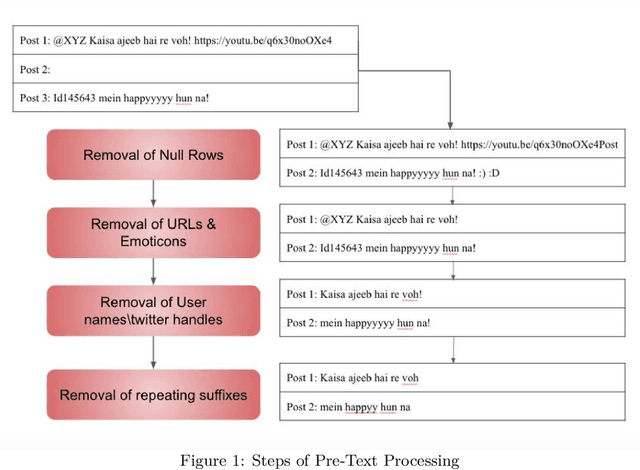


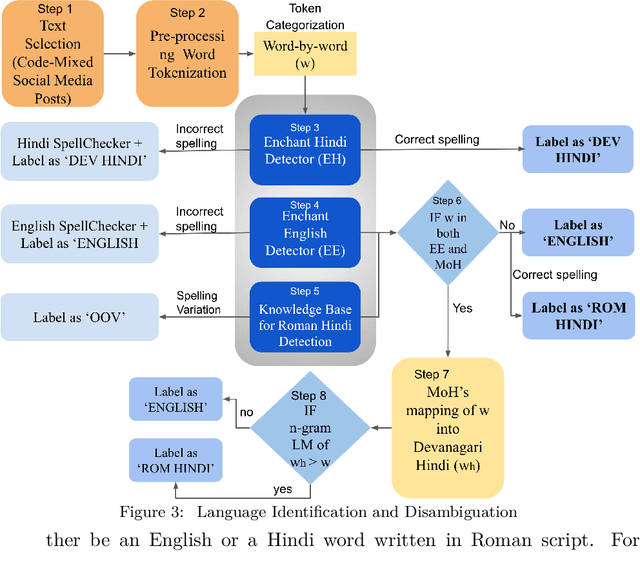
Social media has become a bedrock for people to voice their opinions worldwide. Due to the greater sense of freedom with the anonymity feature, it is possible to disregard social etiquette online and attack others without facing severe consequences, inevitably propagating hate speech. The current measures to sift the online content and offset the hatred spread do not go far enough. One factor contributing to this is the prevalence of regional languages in social media and the paucity of language flexible hate speech detectors. The proposed work focuses on analyzing hate speech in Hindi-English code-switched language. Our method explores transformation techniques to capture precise text representation. To contain the structure of data and yet use it with existing algorithms, we developed MoH or Map Only Hindi, which means "Love" in Hindi. MoH pipeline consists of language identification, Roman to Devanagari Hindi transliteration using a knowledge base of Roman Hindi words. Finally, it employs the fine-tuned Multilingual Bert and MuRIL language models. We conducted several quantitative experiment studies on three datasets and evaluated performance using Precision, Recall, and F1 metrics. The first experiment studies MoH mapped text's performance with classical machine learning models and shows an average increase of 13% in F1 scores. The second compares the proposed work's scores with those of the baseline models and offers a rise in performance by 6%. Finally, the third reaches the proposed MoH technique with various data simulations using the existing transliteration library. Here, MoH outperforms the rest by 15%. Our results demonstrate a significant improvement in the state-of-the-art scores on all three datasets.