 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAD++: Improved Data-free Test Time Adversarial Defense
Sep 10, 2023With the increasing deployment of deep neural networks in safety-critical applications such as self-driving cars, medical imaging, anomaly detection, etc., adversarial robustness has become a crucial concern in the reliability of these networks in real-world scenarios. A plethora of works based on adversarial training and regularization-based techniques have been proposed to make these deep networks robust against adversarial attacks. However, these methods require either retraining models or training them from scratch, making them infeasible to defend pre-trained models when access to training data is restricted. To address this problem, we propose a test time Data-free Adversarial Defense (DAD) containing detection and correction frameworks. Moreover, to further improve the efficacy of the correction framework in cases when the detector is under-confident, we propose a soft-detection scheme (dubbed as "DAD++"). We conduct a wide range of experiments and ablations on several datasets and network architectures to show the efficacy of our proposed approach. Furthermore, we demonstrate the applicability of our approach in imparting adversarial defense at test time under data-free (or data-efficient) applications/setups, such as Data-free Knowledge Distillation and Source-free Unsupervised Domain Adaptation, as well as Semi-supervised classification frameworks. We observe that in all the experiments and applications, our DAD++ gives an impressive performance against various adversarial attacks with a minimal drop in clean accuracy. The source code is available at: https://github.com/vcl-iisc/Improved-Data-free-Test-Time-Adversarial-Defense
Adversarial Adaptation for French Named Entity Recognition
Jan 12, 2023

Named Entity Recognition (NER) is the task of identifying and classifying named entities in large-scale texts into predefined classes. NER in French and other relatively limited-resource languages cannot always benefit from approaches proposed for languages like English due to a dearth of large, robust datasets. In this paper, we present our work that aims to mitigate the effects of this dearth of large, labeled datasets. We propose a Transformer-based NER approach for French, using adversarial adaptation to similar domain or general corpora to improve feature extraction and enable better generalization. Our approach allows learning better features using large-scale unlabeled corpora from the same domain or mixed domains to introduce more variations during training and reduce overfitting. Experimental results on three labeled datasets show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of Transformer models, source datasets, and target corpora. We also show that adversarial adaptation to large-scale unlabeled corpora can help mitigate the performance dip incurred on using Transformer models pre-trained on smaller corpora.
An Emotion-Aware Multi-Task Approach to Fake News and Rumour Detection using Transfer Learning
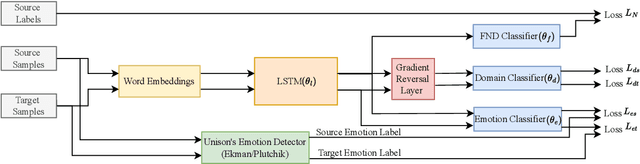
Dec 07, 2022Social networking sites, blogs, and online articles are instant sources of news for internet users globally. However, in the absence of strict regulations mandating the genuineness of every text on social media, it is probable that some of these texts are fake news or rumours. Their deceptive nature and ability to propagate instantly can have an adverse effect on society. This necessitates the need for more effective detection of fake news and rumours on the web. In this work, we annotate four fake news detection and rumour detection datasets with their emotion class labels using transfer learning. We show the correlation between the legitimacy of a text with its intrinsic emotion for fake news and rumour detection, and prove that even within the same emotion class, fake and real news are often represented differently, which can be used for improved feature extraction. Based on this, we propose a multi-task framework for fake news and rumour detection, predicting both the emotion and legitimacy of the text. We train a variety of deep learning models in single-task and multi-task settings for a more comprehensive comparison. We further analyze the performance of our multi-task approach for fake news detection in cross-domain settings to verify its efficacy for better generalization across datasets, and to verify that emotions act as a domain-independent feature. Experimental results verify that our multi-task models consistently outperform their single-task counterparts in terms of accuracy, precision, recall, and F1 score, both for in-domain and cross-domain settings. We also qualitatively analyze the difference in performance in single-task and multi-task learning models.
Transformer-Based Named Entity Recognition for French Using Adversarial Adaptation to Similar Domain Corpora
Dec 05, 2022
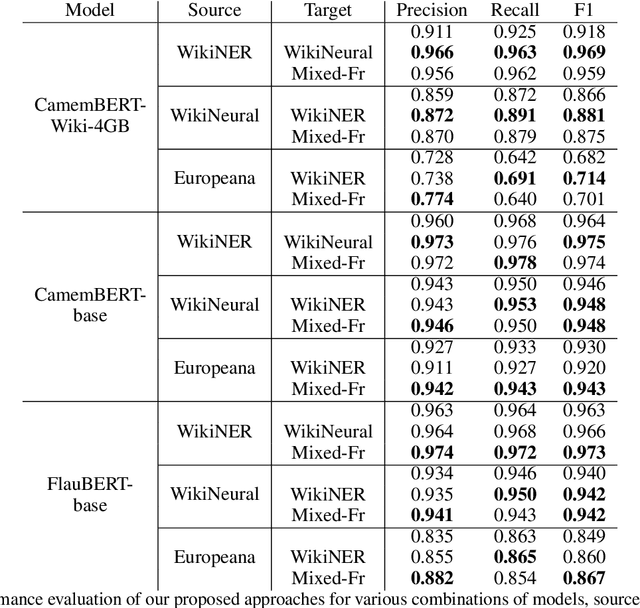
Named Entity Recognition (NER) involves the identification and classification of named entities in unstructured text into predefined classes. NER in languages with limited resources, like French, is still an open problem due to the lack of large, robust, labelled datasets. In this paper, we propose a transformer-based NER approach for French using adversarial adaptation to similar domain or general corpora for improved feature extraction and better generalization. We evaluate our approach on three labelled datasets and show that our adaptation framework outperforms the corresponding non-adaptive models for various combinations of transformer models, source datasets and target corpora.
An Emotion-guided Approach to Domain Adaptive Fake News Detection using Adversarial Learning
Nov 26, 2022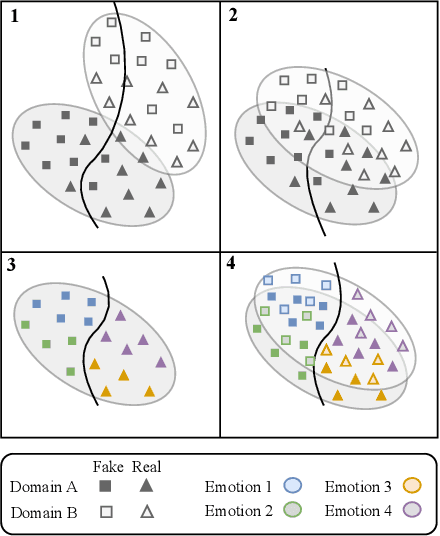

Recent works on fake news detection have shown the efficacy of using emotions as a feature for improved performance. However, the cross-domain impact of emotion-guided features for fake news detection still remains an open problem. In this work, we propose an emotion-guided, domain-adaptive, multi-task approach for cross-domain fake news detection, proving the efficacy of emotion-guided models in cross-domain settings for various datasets.
Emotion-guided Cross-domain Fake News Detection using Adversarial Domain Adaptation
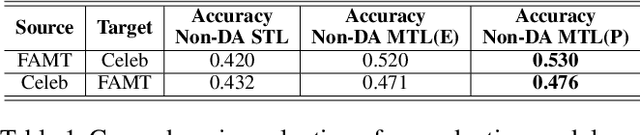
Nov 24, 2022Recent works on fake news detection have shown the efficacy of using emotions as a feature or emotions-based features for improved performance. However, the impact of these emotion-guided features for fake news detection in cross-domain settings, where we face the problem of domain shift, is still largely unexplored. In this work, we evaluate the impact of emotion-guided features for cross-domain fake news detection, and further propose an emotion-guided, domain-adaptive approach using adversarial learning. We prove the efficacy of emotion-guided models in cross-domain settings for various combinations of source and target datasets from FakeNewsAMT, Celeb, Politifact and Gossipcop datasets.
A Spreader Ranking Algorithm for Extremely Low-budget Influence Maximization in Social Networks using Community Bridge Nodes
Nov 17, 2022



In recent years, social networking platforms have gained significant popularity among the masses like connecting with people and propagating ones thoughts and opinions. This has opened the door to user-specific advertisements and recommendations on these platforms, bringing along a significant focus on Influence Maximisation (IM) on social networks due to its wide applicability in target advertising, viral marketing, and personalized recommendations. The aim of IM is to identify certain nodes in the network which can help maximize the spread of certain information through a diffusion cascade. While several works have been proposed for IM, most were inefficient in exploiting community structures to their full extent. In this work, we propose a community structures-based approach, which employs a K-Shell algorithm in order to generate a score for the connections between seed nodes and communities for low-budget scenarios. Further, our approach employs entropy within communities to ensure the proper spread of information within the communities. We choose the Independent Cascade (IC) model to simulate information spread and evaluate it on four evaluation metrics. We validate our proposed approach on eight publicly available networks and find that it significantly outperforms the baseline approaches on these metrics, while still being relatively efficient.
Robust Few-shot Learning Without Using any Adversarial Samples
Nov 03, 2022The high cost of acquiring and annotating samples has made the `few-shot' learning problem of prime importance. Existing works mainly focus on improving performance on clean data and overlook robustness concerns on the data perturbed with adversarial noise. Recently, a few efforts have been made to combine the few-shot problem with the robustness objective using sophisticated Meta-Learning techniques. These methods rely on the generation of adversarial samples in every episode of training, which further adds a computational burden. To avoid such time-consuming and complicated procedures, we propose a simple but effective alternative that does not require any adversarial samples. Inspired by the cognitive decision-making process in humans, we enforce high-level feature matching between the base class data and their corresponding low-frequency samples in the pretraining stage via self distillation. The model is then fine-tuned on the samples of novel classes where we additionally improve the discriminability of low-frequency query set features via cosine similarity. On a 1-shot setting of the CIFAR-FS dataset, our method yields a massive improvement of $60.55\%$ & $62.05\%$ in adversarial accuracy on the PGD and state-of-the-art Auto Attack, respectively, with a minor drop in clean accuracy compared to the baseline. Moreover, our method only takes $1.69\times$ of the standard training time while being $\approx$ $5\times$ faster than state-of-the-art adversarial meta-learning methods. The code is available at https://github.com/vcl-iisc/robust-few-shot-learning.
Data-free Defense of Black Box Models Against Adversarial Attacks
Nov 03, 2022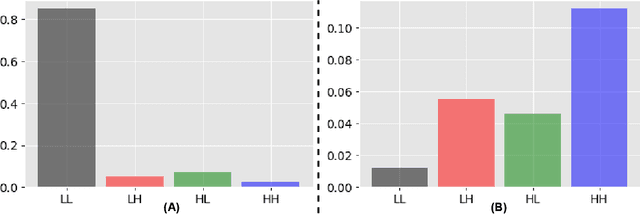


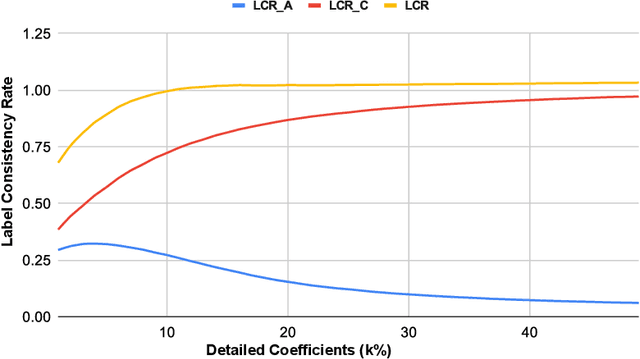
Several companies often safeguard their trained deep models (i.e. details of architecture, learnt weights, training details etc.) from third-party users by exposing them only as black boxes through APIs. Moreover, they may not even provide access to the training data due to proprietary reasons or sensitivity concerns. We make the first attempt to provide adversarial robustness to the black box models in a data-free set up. We construct synthetic data via generative model and train surrogate network using model stealing techniques. To minimize adversarial contamination on perturbed samples, we propose `wavelet noise remover' (WNR) that performs discrete wavelet decomposition on input images and carefully select only a few important coefficients determined by our `wavelet coefficient selection module' (WCSM). To recover the high-frequency content of the image after noise removal via WNR, we further train a `regenerator' network with an objective to retrieve the coefficients such that the reconstructed image yields similar to original predictions on the surrogate model. At test time, WNR combined with trained regenerator network is prepended to the black box network, resulting in a high boost in adversarial accuracy. Our method improves the adversarial accuracy on CIFAR-10 by 38.98% and 32.01% on state-of-the-art Auto Attack compared to baseline, even when the attacker uses surrogate architecture (Alexnet-half and Alexnet) similar to the black box architecture (Alexnet) with same model stealing strategy as defender. The code is available at https://github.com/vcl-iisc/data-free-black-box-defense