 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHate Content Detection via Novel Pre-Processing Sequencing and Ensemble Methods
Sep 08, 2024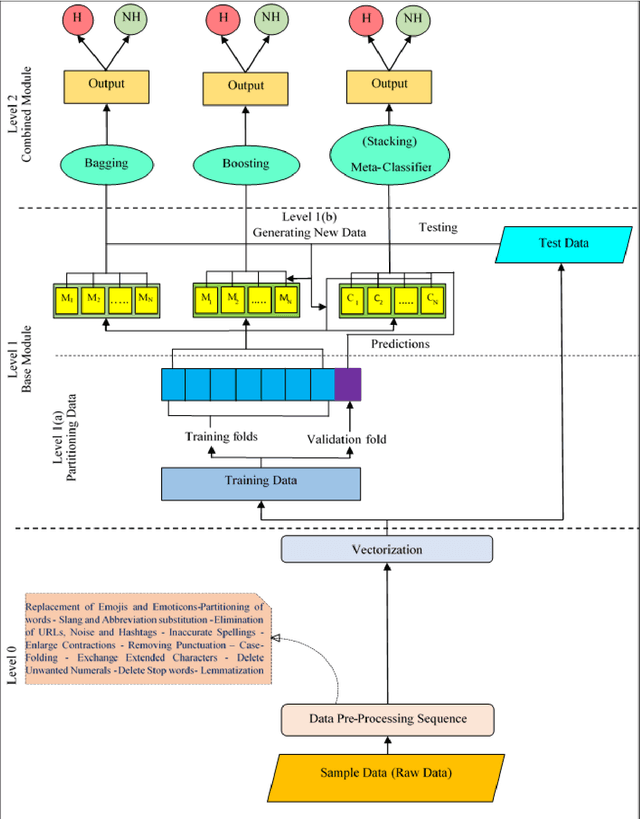

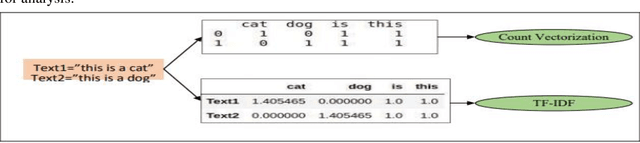

Social media, particularly Twitter, has seen a significant increase in incidents like trolling and hate speech. Thus, identifying hate speech is the need of the hour. This paper introduces a computational framework to curb the hate content on the web. Specifically, this study presents an exhaustive study of pre-processing approaches by studying the impact of changing the sequence of text pre-processing operations for the identification of hate content. The best-performing pre-processing sequence, when implemented with popular classification approaches like Support Vector Machine, Random Forest, Decision Tree, Logistic Regression and K-Neighbor provides a considerable boost in performance. Additionally, the best pre-processing sequence is used in conjunction with different ensemble methods, such as bagging, boosting and stacking to improve the performance further. Three publicly available benchmark datasets (WZ-LS, DT, and FOUNTA), were used to evaluate the proposed approach for hate speech identification. The proposed approach achieves a maximum accuracy of 95.14% highlighting the effectiveness of the unique pre-processing approach along with an ensemble classifier.
MHS-STMA: Multimodal Hate Speech Detection via Scalable Transformer-Based Multilevel Attention Framework
Sep 08, 2024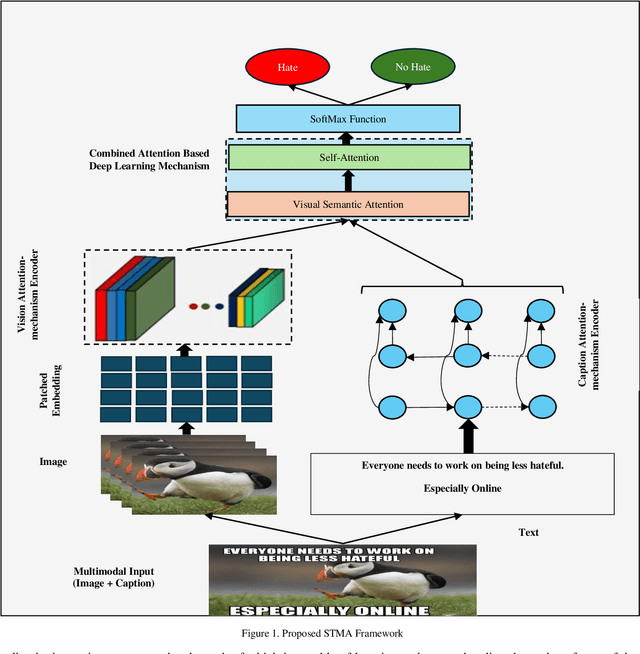


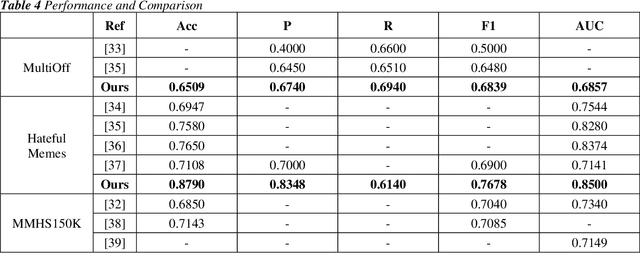
Social media has a significant impact on people's lives. Hate speech on social media has emerged as one of society's most serious issues recently. Text and pictures are two forms of multimodal data distributed within articles. Unimodal analysis has been the primary emphasis of earlier approaches. Additionally, when doing multimodal analysis, researchers neglect to preserve the distinctive qualities associated with each modality. The present article suggests a scalable architecture for multimodal hate content detection called transformer-based multilevel attention (STMA) to address these shortcomings. This architecture consists of three main parts: a combined attention-based deep learning mechanism, a vision attention mechanism encoder, and a caption attention-mechanism encoder. To identify hate content, each component uses various attention processes and uniquely handles multimodal data. Several studies employing multiple assessment criteria on three hate speech datasets: Hateful memes, MultiOff, and MMHS150K, validate the suggested architecture's efficacy. The outcomes demonstrate that on all three datasets, the suggested strategy performs better than the baseline approaches.
A Noise and Edge extraction-based dual-branch method for Shallowfake and Deepfake Localization
Sep 02, 2024The trustworthiness of multimedia is being increasingly evaluated by advanced Image Manipulation Localization (IML) techniques, resulting in the emergence of the IML field. An effective manipulation model necessitates the extraction of non-semantic differential features between manipulated and legitimate sections to utilize artifacts. This requires direct comparisons between the two regions.. Current models employ either feature approaches based on handcrafted features, convolutional neural networks (CNNs), or a hybrid approach that combines both. Handcrafted feature approaches presuppose tampering in advance, hence restricting their effectiveness in handling various tampering procedures, but CNNs capture semantic information, which is insufficient for addressing manipulation artifacts. In order to address these constraints, we have developed a dual-branch model that integrates manually designed feature noise with conventional CNN features. This model employs a dual-branch strategy, where one branch integrates noise characteristics and the other branch integrates RGB features using the hierarchical ConvNext Module. In addition, the model utilizes edge supervision loss to acquire boundary manipulation information, resulting in accurate localization at the edges. Furthermore, this architecture utilizes a feature augmentation module to optimize and refine the presentation of attributes. The shallowfakes dataset (CASIA, COVERAGE, COLUMBIA, NIST16) and deepfake dataset Faceforensics++ (FF++) underwent thorough testing to demonstrate their outstanding ability to extract features and their superior performance compared to other baseline models. The AUC score achieved an astounding 99%. The model is superior in comparison and easily outperforms the existing state-of-the-art (SoTA) models.
Tex-ViT: A Generalizable, Robust, Texture-based dual-branch cross-attention deepfake detector
Aug 29, 2024



Deepfakes, which employ GAN to produce highly realistic facial modification, are widely regarded as the prevailing method. Traditional CNN have been able to identify bogus media, but they struggle to perform well on different datasets and are vulnerable to adversarial attacks due to their lack of robustness. Vision transformers have demonstrated potential in the realm of image classification problems, but they require enough training data. Motivated by these limitations, this publication introduces Tex-ViT (Texture-Vision Transformer), which enhances CNN features by combining ResNet with a vision transformer. The model combines traditional ResNet features with a texture module that operates in parallel on sections of ResNet before each down-sampling operation. The texture module then serves as an input to the dual branch of the cross-attention vision transformer. It specifically focuses on improving the global texture module, which extracts feature map correlation. Empirical analysis reveals that fake images exhibit smooth textures that do not remain consistent over long distances in manipulations. Experiments were performed on different categories of FF++, such as DF, f2f, FS, and NT, together with other types of GAN datasets in cross-domain scenarios. Furthermore, experiments also conducted on FF++, DFDCPreview, and Celeb-DF dataset underwent several post-processing situations, such as blurring, compression, and noise. The model surpassed the most advanced models in terms of generalization, achieving a 98% accuracy in cross-domain scenarios. This demonstrates its ability to learn the shared distinguishing textural characteristics in the manipulated samples. These experiments provide evidence that the proposed model is capable of being applied to various situations and is resistant to many post-processing procedures.
VyAnG-Net: A Novel Multi-Modal Sarcasm Recognition Model by Uncovering Visual, Acoustic and Glossary Features
Aug 05, 2024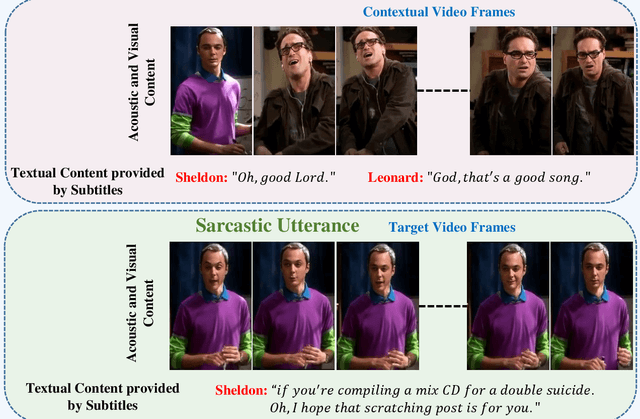

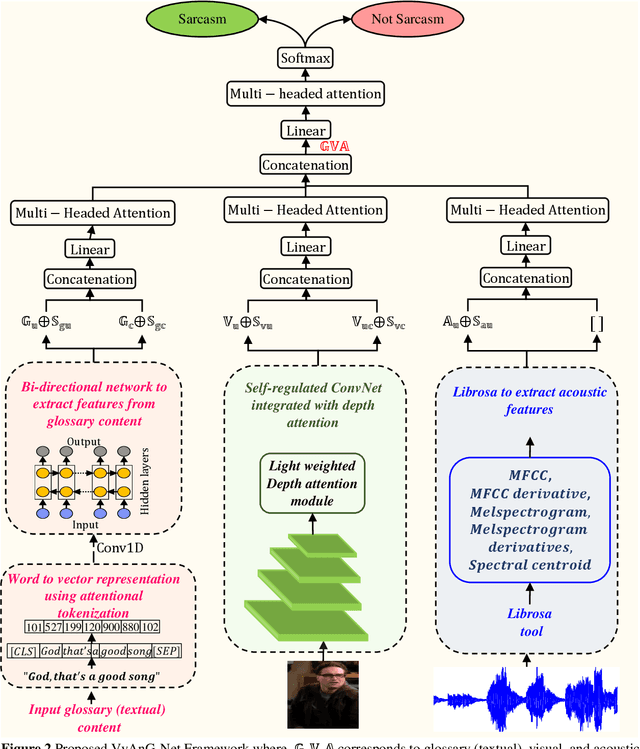
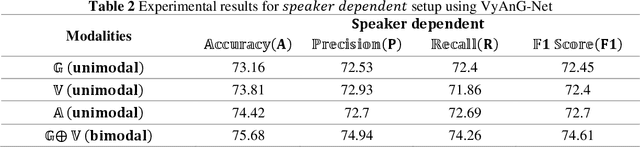
Various linguistic and non-linguistic clues, such as excessive emphasis on a word, a shift in the tone of voice, or an awkward expression, frequently convey sarcasm. The computer vision problem of sarcasm recognition in conversation aims to identify hidden sarcastic, criticizing, and metaphorical information embedded in everyday dialogue. Prior, sarcasm recognition has focused mainly on text. Still, it is critical to consider all textual information, audio stream, facial expression, and body position for reliable sarcasm identification. Hence, we propose a novel approach that combines a lightweight depth attention module with a self-regulated ConvNet to concentrate on the most crucial features of visual data and an attentional tokenizer based strategy to extract the most critical context-specific information from the textual data. The following is a list of the key contributions that our experimentation has made in response to performing the task of Multi-modal Sarcasm Recognition: an attentional tokenizer branch to get beneficial features from the glossary content provided by the subtitles; a visual branch for acquiring the most prominent features from the video frames; an utterance-level feature extraction from acoustic content and a multi-headed attention based feature fusion branch to blend features obtained from multiple modalities. Extensive testing on one of the benchmark video datasets, MUSTaRD, yielded an accuracy of 79.86% for speaker dependent and 76.94% for speaker independent configuration demonstrating that our approach is superior to the existing methods. We have also conducted a cross-dataset analysis to test the adaptability of VyAnG-Net with unseen samples of another dataset MUStARD++.
Contrastive Learning-based Multi Modal Architecture for Emoticon Prediction by Employing Image-Text Pairs
Aug 05, 2024



The emoticons are symbolic representations that generally accompany the textual content to visually enhance or summarize the true intention of a written message. Although widely utilized in the realm of social media, the core semantics of these emoticons have not been extensively explored based on multiple modalities. Incorporating textual and visual information within a single message develops an advanced way of conveying information. Hence, this research aims to analyze the relationship among sentences, visuals, and emoticons. For an orderly exposition, this paper initially provides a detailed examination of the various techniques for extracting multimodal features, emphasizing the pros and cons of each method. Through conducting a comprehensive examination of several multimodal algorithms, with specific emphasis on the fusion approaches, we have proposed a novel contrastive learning based multimodal architecture. The proposed model employs the joint training of dual-branch encoder along with the contrastive learning to accurately map text and images into a common latent space. Our key finding is that by integrating the principle of contrastive learning with that of the other two branches yields superior results. The experimental results demonstrate that our suggested methodology surpasses existing multimodal approaches in terms of accuracy and robustness. The proposed model attained an accuracy of 91% and an MCC-score of 90% while assessing emoticons using the Multimodal-Twitter Emoticon dataset acquired from Twitter. We provide evidence that deep features acquired by contrastive learning are more efficient, suggesting that the proposed fusion technique also possesses strong generalisation capabilities for recognising emoticons across several modes.
Target-Dependent Multimodal Sentiment Analysis Via Employing Visual-to Emotional-Caption Translation Network using Visual-Caption Pairs
Aug 05, 2024

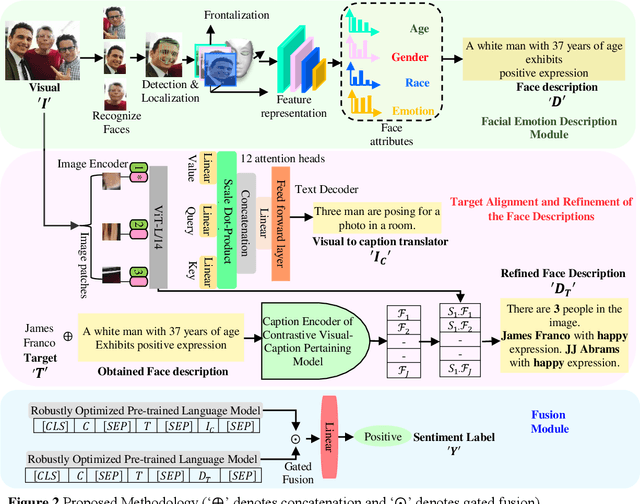
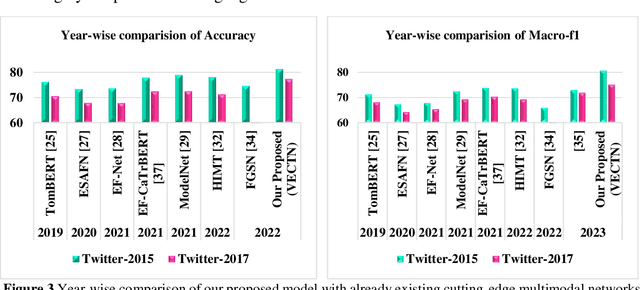
The natural language processing and multimedia field has seen a notable surge in interest in multimodal sentiment recognition. Hence, this study aims to employ Target-Dependent Multimodal Sentiment Analysis (TDMSA) to identify the level of sentiment associated with every target (aspect) stated within a multimodal post consisting of a visual-caption pair. Despite the recent advancements in multimodal sentiment recognition, there has been a lack of explicit incorporation of emotional clues from the visual modality, specifically those pertaining to facial expressions. The challenge at hand is to proficiently obtain visual and emotional clues and subsequently synchronise them with the textual content. In light of this fact, this study presents a novel approach called the Visual-to-Emotional-Caption Translation Network (VECTN) technique. The primary objective of this strategy is to effectively acquire visual sentiment clues by analysing facial expressions. Additionally, it effectively aligns and blends the obtained emotional clues with the target attribute of the caption mode. The experimental findings demonstrate that our methodology is capable of producing ground-breaking outcomes when applied to two publicly accessible multimodal Twitter datasets, namely, Twitter-2015 and Twitter-2017. The experimental results show that the suggested model achieves an accuracy of 81.23% and a macro-F1 of 80.61% on the Twitter-15 dataset, while 77.42% and 75.19% on the Twitter-17 dataset, respectively. The observed improvement in performance reveals that our model is better than others when it comes to collecting target-level sentiment in multimodal data using the expressions of the face.
Modelling Visual Semantics via Image Captioning to extract Enhanced Multi-Level Cross-Modal Semantic Incongruity Representation with Attention for Multimodal Sarcasm Detection
Aug 05, 2024



Sarcasm is a type of irony, characterized by an inherent mismatch between the literal interpretation and the intended connotation. Though sarcasm detection in text has been extensively studied, there are situations in which textual input alone might be insufficient to perceive sarcasm. The inclusion of additional contextual cues, such as images, is essential to recognize sarcasm in social media data effectively. This study presents a novel framework for multimodal sarcasm detection that can process input triplets. Two components of these triplets comprise the input text and its associated image, as provided in the datasets. Additionally, a supplementary modality is introduced in the form of descriptive image captions. The motivation behind incorporating this visual semantic representation is to more accurately capture the discrepancies between the textual and visual content, which are fundamental to the sarcasm detection task. The primary contributions of this study are: (1) a robust textual feature extraction branch that utilizes a cross-lingual language model; (2) a visual feature extraction branch that incorporates a self-regulated residual ConvNet integrated with a lightweight spatially aware attention module; (3) an additional modality in the form of image captions generated using an encoder-decoder architecture capable of reading text embedded in images; (4) distinct attention modules to effectively identify the incongruities between the text and two levels of image representations; (5) multi-level cross-domain semantic incongruity representation achieved through feature fusion. Compared with cutting-edge baselines, the proposed model achieves the best accuracy of 92.89% and 64.48%, respectively, on the Twitter multimodal sarcasm and MultiBully datasets.
Towards Effective Image Forensics via A Novel Computationally Efficient Framework and A New Image Splice Dataset
Jan 13, 2024Splice detection models are the need of the hour since splice manipulations can be used to mislead, spread rumors and create disharmony in society. However, there is a severe lack of image splicing datasets, which restricts the capabilities of deep learning models to extract discriminative features without overfitting. This manuscript presents two-fold contributions toward splice detection. Firstly, a novel splice detection dataset is proposed having two variants. The two variants include spliced samples generated from code and through manual editing. Spliced images in both variants have corresponding binary masks to aid localization approaches. Secondly, a novel Spatio-Compression Lightweight Splice Detection Framework is proposed for accurate splice detection with minimum computational cost. The proposed dual-branch framework extracts discriminative spatial features from a lightweight spatial branch. It uses original resolution compression data to extract double compression artifacts from the second branch, thereby making it 'information preserving.' Several CNNs are tested in combination with the proposed framework on a composite dataset of images from the proposed dataset and the CASIA v2.0 dataset. The best model accuracy of 0.9382 is achieved and compared with similar state-of-the-art methods, demonstrating the superiority of the proposed framework.
Datasets, Clues and State-of-the-Arts for Multimedia Forensics: An Extensive Review
Jan 13, 2024With the large chunks of social media data being created daily and the parallel rise of realistic multimedia tampering methods, detecting and localising tampering in images and videos has become essential. This survey focusses on approaches for tampering detection in multimedia data using deep learning models. Specifically, it presents a detailed analysis of benchmark datasets for malicious manipulation detection that are publicly available. It also offers a comprehensive list of tampering clues and commonly used deep learning architectures. Next, it discusses the current state-of-the-art tampering detection methods, categorizing them into meaningful types such as deepfake detection methods, splice tampering detection methods, copy-move tampering detection methods, etc. and discussing their strengths and weaknesses. Top results achieved on benchmark datasets, comparison of deep learning approaches against traditional methods and critical insights from the recent tampering detection methods are also discussed. Lastly, the research gaps, future direction and conclusion are discussed to provide an in-depth understanding of the tampering detection research arena.