 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVyAnG-Net: A Novel Multi-Modal Sarcasm Recognition Model by Uncovering Visual, Acoustic and Glossary Features
Paper and Code
Aug 05, 2024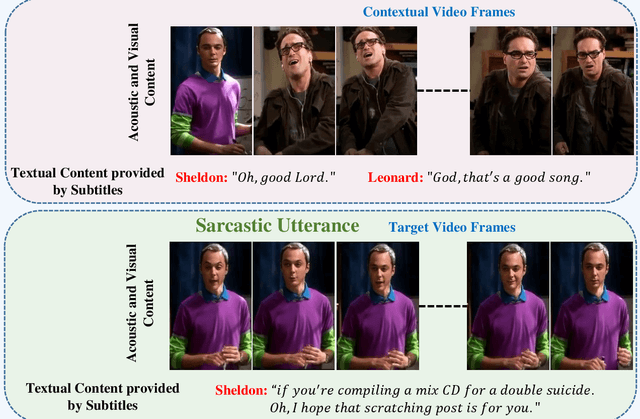

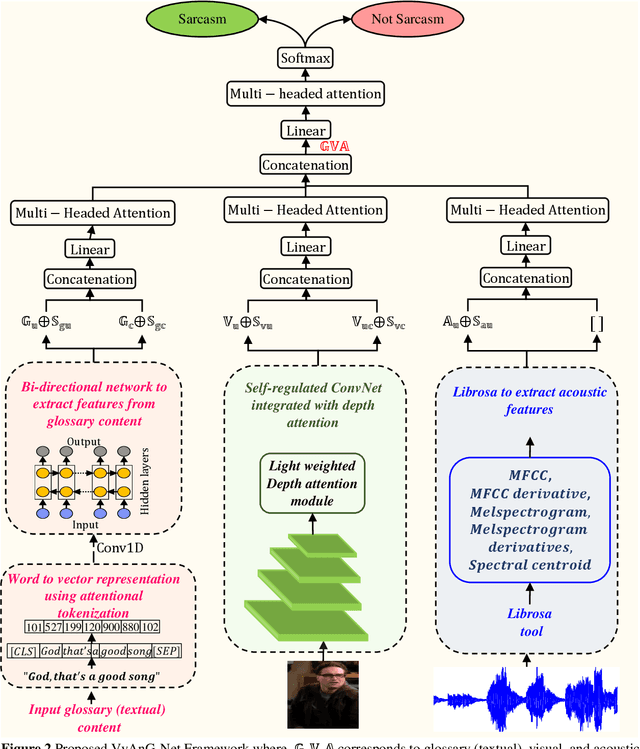
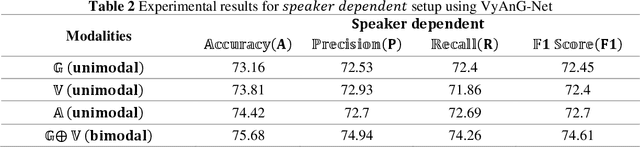
Various linguistic and non-linguistic clues, such as excessive emphasis on a word, a shift in the tone of voice, or an awkward expression, frequently convey sarcasm. The computer vision problem of sarcasm recognition in conversation aims to identify hidden sarcastic, criticizing, and metaphorical information embedded in everyday dialogue. Prior, sarcasm recognition has focused mainly on text. Still, it is critical to consider all textual information, audio stream, facial expression, and body position for reliable sarcasm identification. Hence, we propose a novel approach that combines a lightweight depth attention module with a self-regulated ConvNet to concentrate on the most crucial features of visual data and an attentional tokenizer based strategy to extract the most critical context-specific information from the textual data. The following is a list of the key contributions that our experimentation has made in response to performing the task of Multi-modal Sarcasm Recognition: an attentional tokenizer branch to get beneficial features from the glossary content provided by the subtitles; a visual branch for acquiring the most prominent features from the video frames; an utterance-level feature extraction from acoustic content and a multi-headed attention based feature fusion branch to blend features obtained from multiple modalities. Extensive testing on one of the benchmark video datasets, MUSTaRD, yielded an accuracy of 79.86% for speaker dependent and 76.94% for speaker independent configuration demonstrating that our approach is superior to the existing methods. We have also conducted a cross-dataset analysis to test the adaptability of VyAnG-Net with unseen samples of another dataset MUStARD++.