 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online RFT with Plug-and-Play LLM Judges: Unlocking State-of-the-Art Performance
Jun 06, 2025Reward-model training is the cost bottleneck in modern Reinforcement Learning Human Feedback (RLHF) pipelines, often requiring tens of billions of parameters and an offline preference-tuning phase. In the proposed method, a frozen, instruction-tuned 7B LLM is augmented with only a one line JSON rubric and a rank-16 LoRA adapter (affecting just 0.8% of the model's parameters), enabling it to serve as a complete substitute for the previously used heavyweight evaluation models. The plug-and-play judge achieves 96.2% accuracy on RewardBench, outperforming specialized reward networks ranging from 27B to 70B parameters. Additionally, it allows a 7B actor to outperform the top 70B DPO baseline, which scores 61.8%, by achieving 92% exact match accuracy on GSM-8K utilizing online PPO. Thorough ablations indicate that (i) six in context demonstrations deliver the majority of the zero-to-few-shot improvements (+2pp), and (ii) the LoRA effectively addresses the remaining disparity, particularly in the safety and adversarial Chat-Hard segments. The proposed model introduces HH-Rationales, a subset of 10,000 pairs from Anthropic HH-RLHF, to examine interpretability, accompanied by human generated justifications. GPT-4 scoring indicates that our LoRA judge attains approximately = 9/10 in similarity to human explanations, while zero-shot judges score around =5/10. These results indicate that the combination of prompt engineering and tiny LoRA produces a cost effective, transparent, and easily adjustable reward function, removing the offline phase while achieving new state-of-the-art outcomes for both static evaluation and online RLHF.
VyAnG-Net: A Novel Multi-Modal Sarcasm Recognition Model by Uncovering Visual, Acoustic and Glossary Features
Aug 05, 2024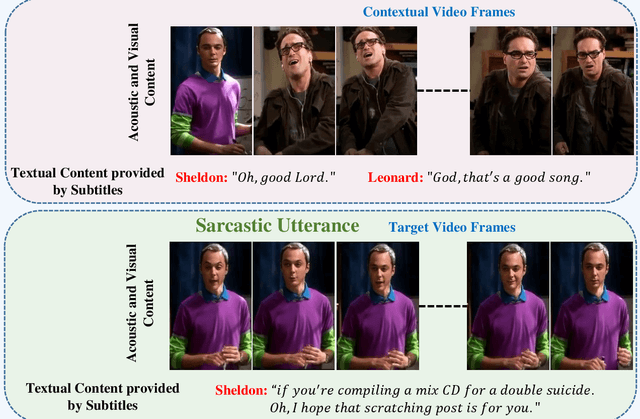

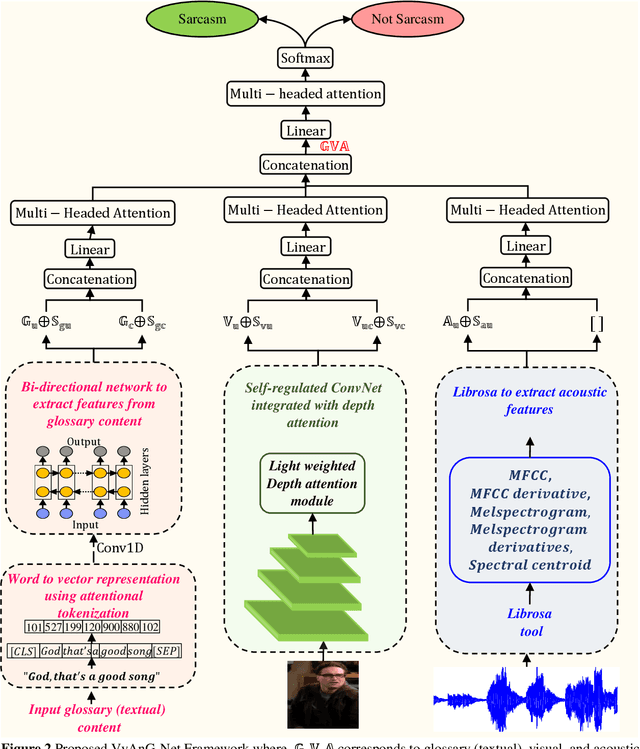
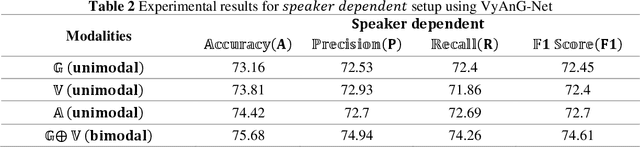
Various linguistic and non-linguistic clues, such as excessive emphasis on a word, a shift in the tone of voice, or an awkward expression, frequently convey sarcasm. The computer vision problem of sarcasm recognition in conversation aims to identify hidden sarcastic, criticizing, and metaphorical information embedded in everyday dialogue. Prior, sarcasm recognition has focused mainly on text. Still, it is critical to consider all textual information, audio stream, facial expression, and body position for reliable sarcasm identification. Hence, we propose a novel approach that combines a lightweight depth attention module with a self-regulated ConvNet to concentrate on the most crucial features of visual data and an attentional tokenizer based strategy to extract the most critical context-specific information from the textual data. The following is a list of the key contributions that our experimentation has made in response to performing the task of Multi-modal Sarcasm Recognition: an attentional tokenizer branch to get beneficial features from the glossary content provided by the subtitles; a visual branch for acquiring the most prominent features from the video frames; an utterance-level feature extraction from acoustic content and a multi-headed attention based feature fusion branch to blend features obtained from multiple modalities. Extensive testing on one of the benchmark video datasets, MUSTaRD, yielded an accuracy of 79.86% for speaker dependent and 76.94% for speaker independent configuration demonstrating that our approach is superior to the existing methods. We have also conducted a cross-dataset analysis to test the adaptability of VyAnG-Net with unseen samples of another dataset MUStARD++.
Target-Dependent Multimodal Sentiment Analysis Via Employing Visual-to Emotional-Caption Translation Network using Visual-Caption Pairs
Aug 05, 2024

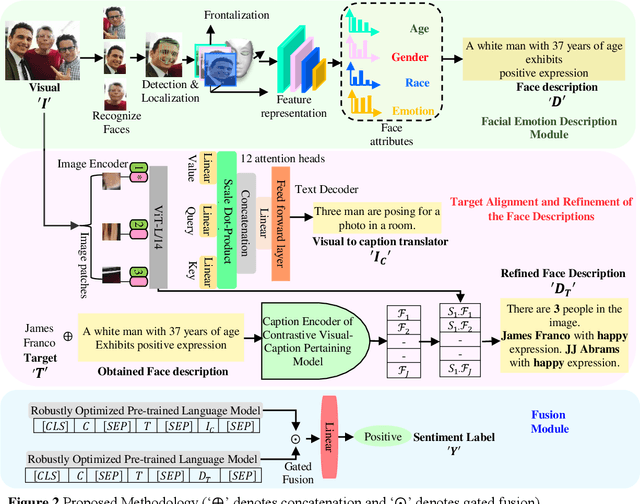
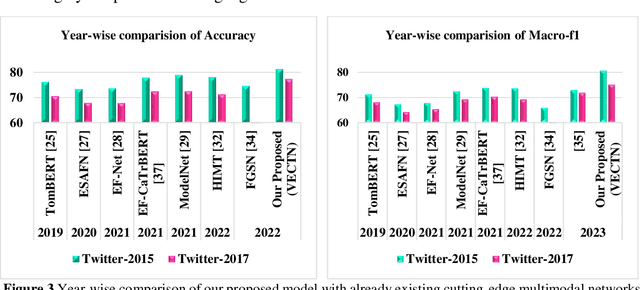
The natural language processing and multimedia field has seen a notable surge in interest in multimodal sentiment recognition. Hence, this study aims to employ Target-Dependent Multimodal Sentiment Analysis (TDMSA) to identify the level of sentiment associated with every target (aspect) stated within a multimodal post consisting of a visual-caption pair. Despite the recent advancements in multimodal sentiment recognition, there has been a lack of explicit incorporation of emotional clues from the visual modality, specifically those pertaining to facial expressions. The challenge at hand is to proficiently obtain visual and emotional clues and subsequently synchronise them with the textual content. In light of this fact, this study presents a novel approach called the Visual-to-Emotional-Caption Translation Network (VECTN) technique. The primary objective of this strategy is to effectively acquire visual sentiment clues by analysing facial expressions. Additionally, it effectively aligns and blends the obtained emotional clues with the target attribute of the caption mode. The experimental findings demonstrate that our methodology is capable of producing ground-breaking outcomes when applied to two publicly accessible multimodal Twitter datasets, namely, Twitter-2015 and Twitter-2017. The experimental results show that the suggested model achieves an accuracy of 81.23% and a macro-F1 of 80.61% on the Twitter-15 dataset, while 77.42% and 75.19% on the Twitter-17 dataset, respectively. The observed improvement in performance reveals that our model is better than others when it comes to collecting target-level sentiment in multimodal data using the expressions of the face.
Modelling Visual Semantics via Image Captioning to extract Enhanced Multi-Level Cross-Modal Semantic Incongruity Representation with Attention for Multimodal Sarcasm Detection
Aug 05, 2024



Sarcasm is a type of irony, characterized by an inherent mismatch between the literal interpretation and the intended connotation. Though sarcasm detection in text has been extensively studied, there are situations in which textual input alone might be insufficient to perceive sarcasm. The inclusion of additional contextual cues, such as images, is essential to recognize sarcasm in social media data effectively. This study presents a novel framework for multimodal sarcasm detection that can process input triplets. Two components of these triplets comprise the input text and its associated image, as provided in the datasets. Additionally, a supplementary modality is introduced in the form of descriptive image captions. The motivation behind incorporating this visual semantic representation is to more accurately capture the discrepancies between the textual and visual content, which are fundamental to the sarcasm detection task. The primary contributions of this study are: (1) a robust textual feature extraction branch that utilizes a cross-lingual language model; (2) a visual feature extraction branch that incorporates a self-regulated residual ConvNet integrated with a lightweight spatially aware attention module; (3) an additional modality in the form of image captions generated using an encoder-decoder architecture capable of reading text embedded in images; (4) distinct attention modules to effectively identify the incongruities between the text and two levels of image representations; (5) multi-level cross-domain semantic incongruity representation achieved through feature fusion. Compared with cutting-edge baselines, the proposed model achieves the best accuracy of 92.89% and 64.48%, respectively, on the Twitter multimodal sarcasm and MultiBully datasets.
Contrastive Learning-based Multi Modal Architecture for Emoticon Prediction by Employing Image-Text Pairs
Aug 05, 2024The emoticons are symbolic representations that generally accompany the textual content to visually enhance or summarize the true intention of a written message. Although widely utilized in the realm of social media, the core semantics of these emoticons have not been extensively explored based on multiple modalities. Incorporating textual and visual information within a single message develops an advanced way of conveying information. Hence, this research aims to analyze the relationship among sentences, visuals, and emoticons. For an orderly exposition, this paper initially provides a detailed examination of the various techniques for extracting multimodal features, emphasizing the pros and cons of each method. Through conducting a comprehensive examination of several multimodal algorithms, with specific emphasis on the fusion approaches, we have proposed a novel contrastive learning based multimodal architecture. The proposed model employs the joint training of dual-branch encoder along with the contrastive learning to accurately map text and images into a common latent space. Our key finding is that by integrating the principle of contrastive learning with that of the other two branches yields superior results. The experimental results demonstrate that our suggested methodology surpasses existing multimodal approaches in terms of accuracy and robustness. The proposed model attained an accuracy of 91% and an MCC-score of 90% while assessing emoticons using the Multimodal-Twitter Emoticon dataset acquired from Twitter. We provide evidence that deep features acquired by contrastive learning are more efficient, suggesting that the proposed fusion technique also possesses strong generalisation capabilities for recognising emoticons across several modes.