 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHS-STMA: Multimodal Hate Speech Detection via Scalable Transformer-Based Multilevel Attention Framework
Sep 08, 2024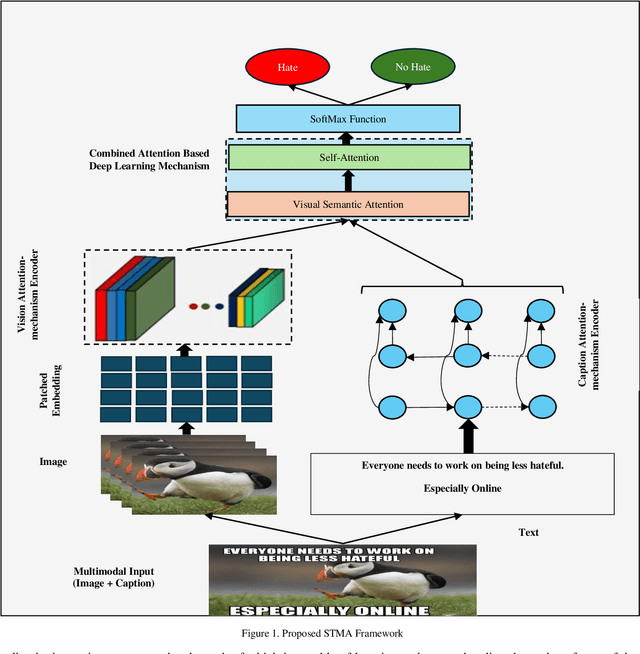


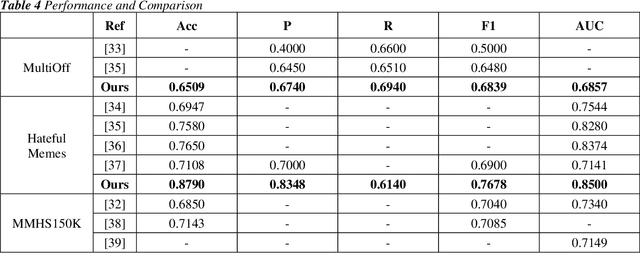
Social media has a significant impact on people's lives. Hate speech on social media has emerged as one of society's most serious issues recently. Text and pictures are two forms of multimodal data distributed within articles. Unimodal analysis has been the primary emphasis of earlier approaches. Additionally, when doing multimodal analysis, researchers neglect to preserve the distinctive qualities associated with each modality. The present article suggests a scalable architecture for multimodal hate content detection called transformer-based multilevel attention (STMA) to address these shortcomings. This architecture consists of three main parts: a combined attention-based deep learning mechanism, a vision attention mechanism encoder, and a caption attention-mechanism encoder. To identify hate content, each component uses various attention processes and uniquely handles multimodal data. Several studies employing multiple assessment criteria on three hate speech datasets: Hateful memes, MultiOff, and MMHS150K, validate the suggested architecture's efficacy. The outcomes demonstrate that on all three datasets, the suggested strategy performs better than the baseline approaches.
Hate Content Detection via Novel Pre-Processing Sequencing and Ensemble Methods
Sep 08, 2024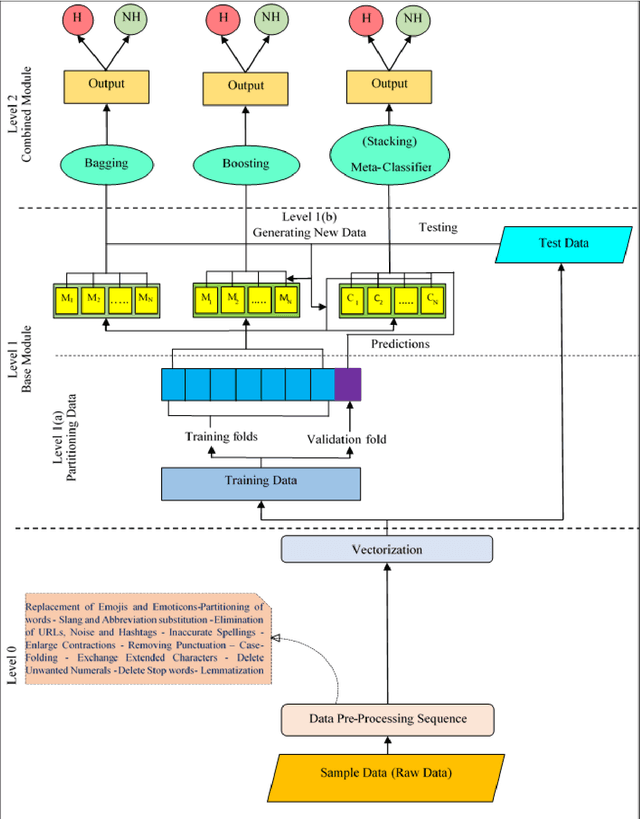

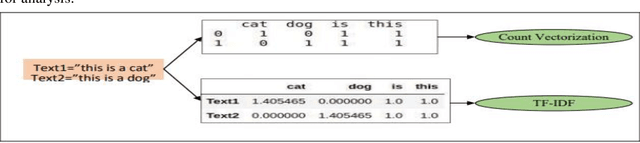

Social media, particularly Twitter, has seen a significant increase in incidents like trolling and hate speech. Thus, identifying hate speech is the need of the hour. This paper introduces a computational framework to curb the hate content on the web. Specifically, this study presents an exhaustive study of pre-processing approaches by studying the impact of changing the sequence of text pre-processing operations for the identification of hate content. The best-performing pre-processing sequence, when implemented with popular classification approaches like Support Vector Machine, Random Forest, Decision Tree, Logistic Regression and K-Neighbor provides a considerable boost in performance. Additionally, the best pre-processing sequence is used in conjunction with different ensemble methods, such as bagging, boosting and stacking to improve the performance further. Three publicly available benchmark datasets (WZ-LS, DT, and FOUNTA), were used to evaluate the proposed approach for hate speech identification. The proposed approach achieves a maximum accuracy of 95.14% highlighting the effectiveness of the unique pre-processing approach along with an ensemble classifier.