 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIDE: Training-Free Diversity Guidance via PCA-Directed Feature Perturbation in Single-Step Diffusion Models
May 12, 2026Distilled one-step (T=1) or few-step (T$\leq$4) diffusion models enable real-time image generation but often exhibit reduced sample diversity compared to their multi-step counterparts. In multi-step diffusion, diversity can be introduced through schedules, trajectories, or iterative optimization; however, these mechanisms are unavailable in the few-step or single-step setting, limiting the effectiveness of existing diversity-enhancing methods. A natural alternative is to perturb intermediate features, but naive feature perturbation is often ineffective, either yielding limited diversity gains or degrading generation quality. We argue that effective diversity injection in few-step models requires perturbations that respect the model's learned feature geometry. Based on this insight, we propose STRIDE, a training-free and optimization-free method that operates in a single forward pass. STRIDE injects spatially coherent (pink) noise into intermediate transformer features, projected onto the principal components of the model's own activations, ensuring that perturbations lie on the learned feature manifold. This design enables controlled variation along meaningful directions in the representation space. Extensive experiments on FLUX.1-schnell and SD3.5 Turbo across COCO, DrawBench, PartiPrompts, and GenEval show that STRIDE consistently improves diversity while maintaining strong text alignment. In particular, STRIDE reduces intra-batch similarity with minimal impact on CLIP score, and Pareto-dominates existing training-free baselines on the diversity-fidelity frontier. These results highlight that, in the absence of iterative refinement, improving diversity in few-step and one-step diffusion depends not on increasing perturbation strength, but on aligning perturbations with the model's internal representation structure.
EMAG: Self-Rectifying Diffusion Sampling with Exponential Moving Average Guidance
Dec 19, 2025
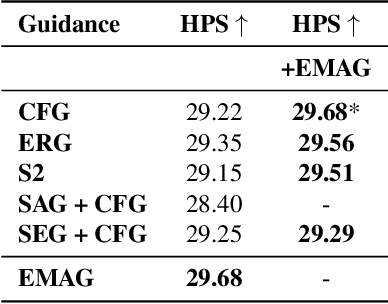

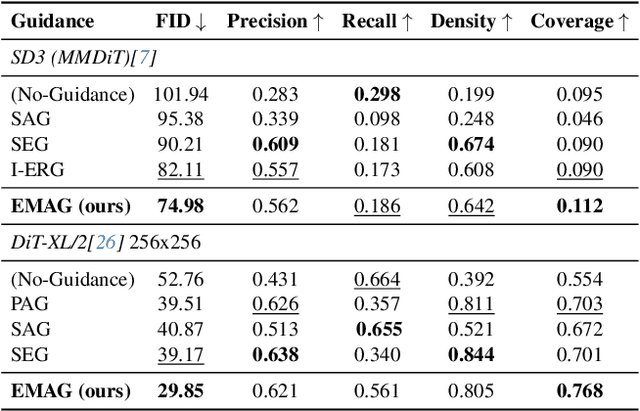
In diffusion and flow-matching generative models, guidance techniques are widely used to improve sample quality and consistency. Classifier-free guidance (CFG) is the de facto choice in modern systems and achieves this by contrasting conditional and unconditional samples. Recent work explores contrasting negative samples at inference using a weaker model, via strong/weak model pairs, attention-based masking, stochastic block dropping, or perturbations to the self-attention energy landscape. While these strategies refine the generation quality, they still lack reliable control over the granularity or difficulty of the negative samples, and target-layer selection is often fixed. We propose Exponential Moving Average Guidance (EMAG), a training-free mechanism that modifies attention at inference time in diffusion transformers, with a statistics-based, adaptive layer-selection rule. Unlike prior methods, EMAG produces harder, semantically faithful negatives (fine-grained degradations), surfacing difficult failure modes, enabling the denoiser to refine subtle artifacts, boosting the quality and human preference score (HPS) by +0.46 over CFG. We further demonstrate that EMAG naturally composes with advanced guidance techniques, such as APG and CADS, further improving HPS.
Exploring Primitive Visual Measurement Understanding and the Role of Output Format in Learning in Vision-Language Models
Jan 25, 2025



This work investigates the capabilities of current vision-language models (VLMs) in visual understanding and attribute measurement of primitive shapes using a benchmark focused on controlled 2D shape configurations with variations in spatial positioning, occlusion, rotation, size, and shape attributes such as type, quadrant, center-coordinates, rotation, occlusion status, and color as shown in Figure 1 and supplementary Figures S3-S81. We fine-tune state-of-the-art VLMs (2B-8B parameters) using Low-Rank Adaptation (LoRA) and validate them on multiple out-of-domain (OD) scenarios from our proposed benchmark. Our findings reveal that coherent sentence-based outputs outperform tuple formats, particularly in OD scenarios with large domain gaps. Additionally, we demonstrate that scaling numeric tokens during loss computation enhances numerical approximation capabilities, further improving performance on spatial and measurement tasks. These results highlight the importance of output format design, loss scaling strategies, and robust generalization techniques in enhancing the training and fine-tuning of VLMs, particularly for tasks requiring precise spatial approximations and strong OD generalization.
Towards Effective Image Forensics via A Novel Computationally Efficient Framework and A New Image Splice Dataset
Jan 13, 2024Splice detection models are the need of the hour since splice manipulations can be used to mislead, spread rumors and create disharmony in society. However, there is a severe lack of image splicing datasets, which restricts the capabilities of deep learning models to extract discriminative features without overfitting. This manuscript presents two-fold contributions toward splice detection. Firstly, a novel splice detection dataset is proposed having two variants. The two variants include spliced samples generated from code and through manual editing. Spliced images in both variants have corresponding binary masks to aid localization approaches. Secondly, a novel Spatio-Compression Lightweight Splice Detection Framework is proposed for accurate splice detection with minimum computational cost. The proposed dual-branch framework extracts discriminative spatial features from a lightweight spatial branch. It uses original resolution compression data to extract double compression artifacts from the second branch, thereby making it 'information preserving.' Several CNNs are tested in combination with the proposed framework on a composite dataset of images from the proposed dataset and the CASIA v2.0 dataset. The best model accuracy of 0.9382 is achieved and compared with similar state-of-the-art methods, demonstrating the superiority of the proposed framework.
A Visually Attentive Splice Localization Network with Multi-Domain Feature Extractor and Multi-Receptive Field Upsampler
Jan 13, 2024Image splice manipulation presents a severe challenge in today's society. With easy access to image manipulation tools, it is easier than ever to modify images that can mislead individuals, organizations or society. In this work, a novel, "Visually Attentive Splice Localization Network with Multi-Domain Feature Extractor and Multi-Receptive Field Upsampler" has been proposed. It contains a unique "visually attentive multi-domain feature extractor" (VA-MDFE) that extracts attentional features from the RGB, edge and depth domains. Next, a "visually attentive downsampler" (VA-DS) is responsible for fusing and downsampling the multi-domain features. Finally, a novel "visually attentive multi-receptive field upsampler" (VA-MRFU) module employs multiple receptive field-based convolutions to upsample attentional features by focussing on different information scales. Experimental results conducted on the public benchmark dataset CASIA v2.0 prove the potency of the proposed model. It comfortably beats the existing state-of-the-arts by achieving an IoU score of 0.851, pixel F1 score of 0.9195 and pixel AUC score of 0.8989.
Datasets, Clues and State-of-the-Arts for Multimedia Forensics: An Extensive Review
Jan 13, 2024With the large chunks of social media data being created daily and the parallel rise of realistic multimedia tampering methods, detecting and localising tampering in images and videos has become essential. This survey focusses on approaches for tampering detection in multimedia data using deep learning models. Specifically, it presents a detailed analysis of benchmark datasets for malicious manipulation detection that are publicly available. It also offers a comprehensive list of tampering clues and commonly used deep learning architectures. Next, it discusses the current state-of-the-art tampering detection methods, categorizing them into meaningful types such as deepfake detection methods, splice tampering detection methods, copy-move tampering detection methods, etc. and discussing their strengths and weaknesses. Top results achieved on benchmark datasets, comparison of deep learning approaches against traditional methods and critical insights from the recent tampering detection methods are also discussed. Lastly, the research gaps, future direction and conclusion are discussed to provide an in-depth understanding of the tampering detection research arena.
Boldly Going Where No Benchmark Has Gone Before: Exposing Bias and Shortcomings in Code Generation Evaluation
Jan 08, 2024

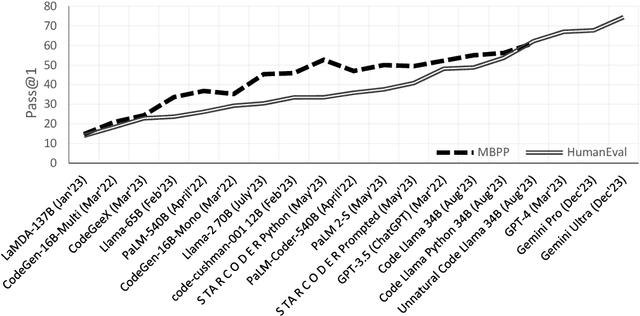
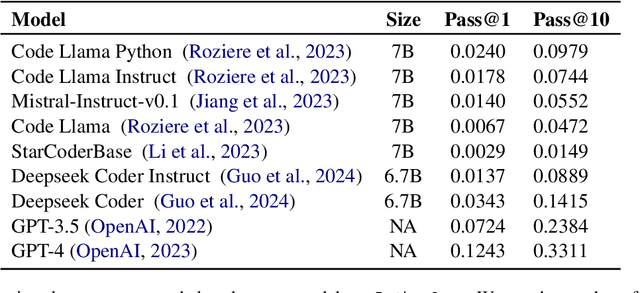
Motivated by the increasing popularity of code generation from human descriptions using large language models (LLMs), several benchmarks have been proposed to assess the capabilities of existing and emerging models. This study presents a large-scale human evaluation of HumanEval and MBPP, two widely used benchmarks for Python code generation, focusing on their diversity and difficulty. Our findings reveal a significant bias towards a limited number of programming concepts, with negligible or no representation of most concepts. Additionally, we identify a concerningly high proportion of easy programming questions, potentially leading to an overestimation of model performance on code generation tasks.
LAHM : Large Annotated Dataset for Multi-Domain and Multilingual Hate Speech Identification
Apr 03, 2023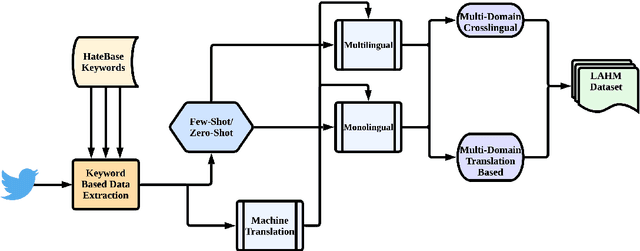
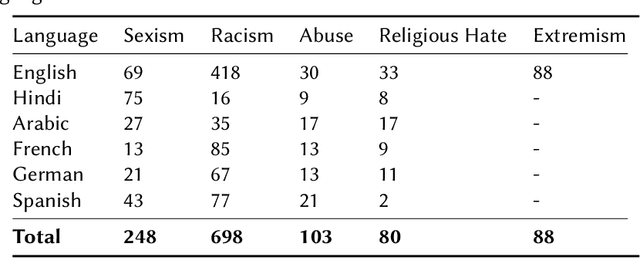
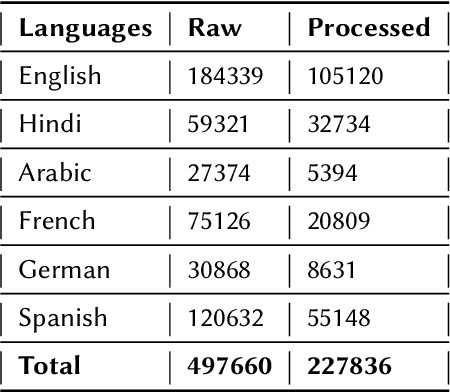
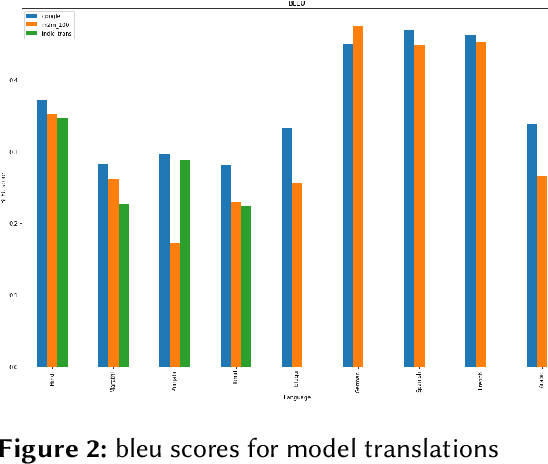
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual hate speech analysis dataset for English, Hindi, Arabic, French, German and Spanish languages for multiple domains across hate speech - Abuse, Racism, Sexism, Religious Hate and Extremism. To the best of our knowledge, this paper is the first to address the problem of identifying various types of hate speech in these five wide domains in these six languages. In this work, we describe how we created the dataset, created annotations at high level and low level for different domains and how we use it to test the current state-of-the-art multilingual and multitask learning approaches. We evaluate our dataset in various monolingual, cross-lingual and machine translation classification settings and compare it against open source English datasets that we aggregated and merged for this task. Then we discuss how this approach can be used to create large scale hate-speech datasets and how to leverage our annotations in order to improve hate speech detection and classification in general.
Person Re-Identification using Deep Learning Networks: A Systematic Review
Dec 24, 2020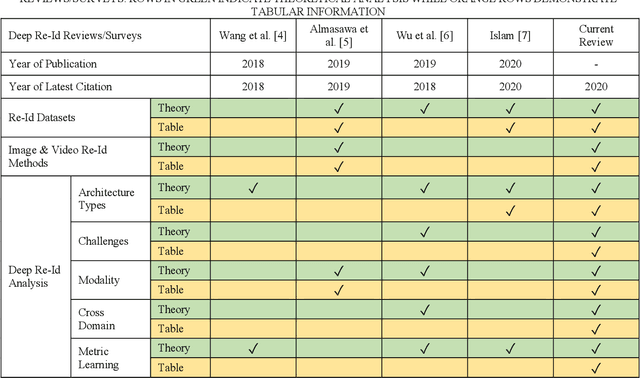
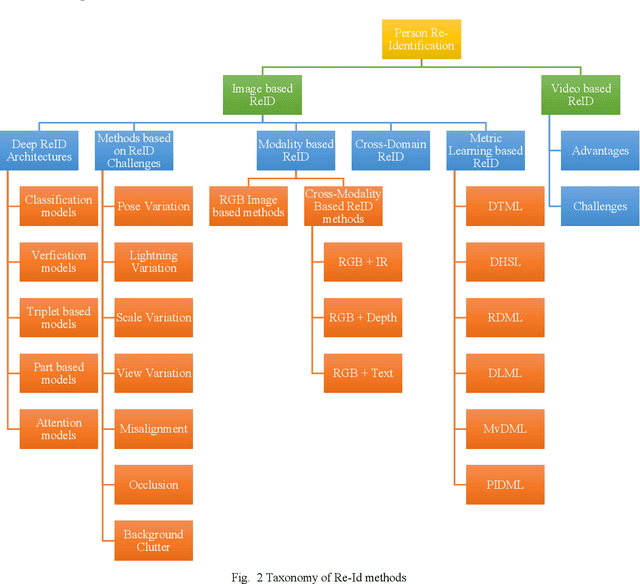
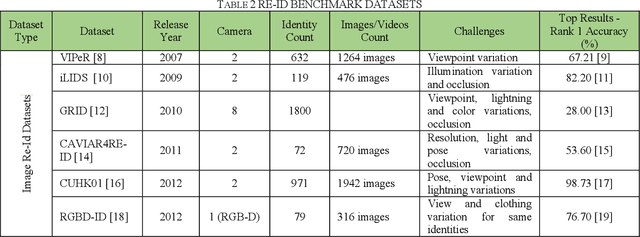
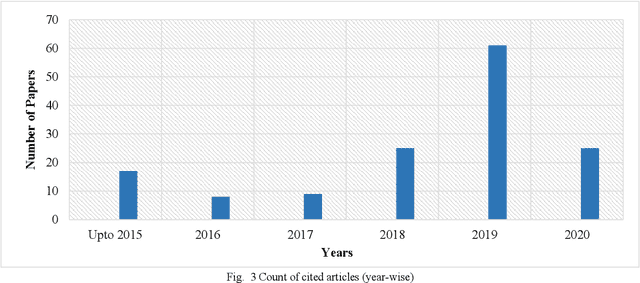
Person re-identification has received a lot of attention from the research community in recent times. Due to its vital role in security based applications, person re-identification lies at the heart of research relevant to tracking robberies, preventing terrorist attacks and other security critical events. While the last decade has seen tremendous growth in re-id approaches, very little review literature exists to comprehend and summarize this progress. This review deals with the latest state-of-the-art deep learning based approaches for person re-identification. While the few existing re-id review works have analysed re-id techniques from a singular aspect, this review evaluates numerous re-id techniques from multiple deep learning aspects such as deep architecture types, common Re-Id challenges (variation in pose, lightning, view, scale, partial or complete occlusion, background clutter), multi-modal Re-Id, cross-domain Re-Id challenges, metric learning approaches and video Re-Id contributions. This review also includes several re-id benchmarks collected over the years, describing their characteristics, specifications and top re-id results obtained on them. The inclusion of the latest deep re-id works makes this a significant contribution to the re-id literature. Lastly, the conclusion and future directions are included.