 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterspeech the ultimate shield! Multi-Conditioned Counterspeech Generation through Attributed Prefix Learning
May 17, 2025Counterspeech has proven to be a powerful tool to combat hate speech online. Previous studies have focused on generating counterspeech conditioned only on specific intents (single attributed). However, a holistic approach considering multiple attributes simultaneously can yield more nuanced and effective responses. Here, we introduce HiPPrO, Hierarchical Prefix learning with Preference Optimization, a novel two-stage framework that utilizes the effectiveness of attribute-specific prefix embedding spaces hierarchically optimized during the counterspeech generation process in the first phase. Thereafter, we incorporate both reference and reward-free preference optimization to generate more constructive counterspeech. Furthermore, we extend IntentCONANv2 by annotating all 13,973 counterspeech instances with emotion labels by five annotators. HiPPrO leverages hierarchical prefix optimization to integrate these dual attributes effectively. An extensive evaluation demonstrates that HiPPrO achieves a ~38 % improvement in intent conformity and a ~3 %, ~2 %, ~3 % improvement in Rouge-1, Rouge-2, and Rouge-L, respectively, compared to several baseline models. Human evaluations further substantiate the superiority of our approach, highlighting the enhanced relevance and appropriateness of the generated counterspeech. This work underscores the potential of multi-attribute conditioning in advancing the efficacy of counterspeech generation systems.
CSEval: Towards Automated, Multi-Dimensional, and Reference-Free Counterspeech Evaluation using Auto-Calibrated LLMs
Jan 29, 2025



Counterspeech has been popular as an effective approach to counter online hate speech, leading to increasing research interest in automated counterspeech generation using language models. However, this field lacks standardised evaluation protocols and robust automated evaluation metrics that align with human judgement. Current automatic evaluation methods, primarily based on similarity metrics, do not effectively capture the complex and independent attributes of counterspeech quality, such as contextual relevance, aggressiveness, or argumentative coherence. This has led to an increased dependency on labor-intensive human evaluations to assess automated counter-speech generation methods. To address these challenges, we introduce CSEval, a novel dataset and framework for evaluating counterspeech quality across four dimensions: contextual-relevance, aggressiveness, argument-coherence, and suitableness. Furthermore, we propose Auto-Calibrated COT for Counterspeech Evaluation (ACE), a prompt-based method with auto-calibrated chain-of-thoughts (CoT) for scoring counterspeech using large language models. Our experiments show that ACE outperforms traditional metrics like ROUGE, METEOR, and BertScore in correlating with human judgement, indicating a significant advancement in automated counterspeech evaluation.
Intent-conditioned and Non-toxic Counterspeech Generation using Multi-Task Instruction Tuning with RLAIF
Mar 15, 2024Counterspeech, defined as a response to mitigate online hate speech, is increasingly used as a non-censorial solution. Addressing hate speech effectively involves dispelling the stereotypes, prejudices, and biases often subtly implied in brief, single-sentence statements or abuses. These implicit expressions challenge language models, especially in seq2seq tasks, as model performance typically excels with longer contexts. Our study introduces CoARL, a novel framework enhancing counterspeech generation by modeling the pragmatic implications underlying social biases in hateful statements. CoARL's first two phases involve sequential multi-instruction tuning, teaching the model to understand intents, reactions, and harms of offensive statements, and then learning task-specific low-rank adapter weights for generating intent-conditioned counterspeech. The final phase uses reinforcement learning to fine-tune outputs for effectiveness and non-toxicity. CoARL outperforms existing benchmarks in intent-conditioned counterspeech generation, showing an average improvement of 3 points in intent-conformity and 4 points in argument-quality metrics. Extensive human evaluation supports CoARL's efficacy in generating superior and more context-appropriate responses compared to existing systems, including prominent LLMs like ChatGPT.
Counterspeeches up my sleeve! Intent Distribution Learning and Persistent Fusion for Intent-Conditioned Counterspeech Generation
May 23, 2023



Counterspeech has been demonstrated to be an efficacious approach for combating hate speech. While various conventional and controlled approaches have been studied in recent years to generate counterspeech, a counterspeech with a certain intent may not be sufficient in every scenario. Due to the complex and multifaceted nature of hate speech, utilizing multiple forms of counter-narratives with varying intents may be advantageous in different circumstances. In this paper, we explore intent-conditioned counterspeech generation. At first, we develop IntentCONAN, a diversified intent-specific counterspeech dataset with 6831 counterspeeches conditioned on five intents, i.e., informative, denouncing, question, positive, and humour. Subsequently, we propose QUARC, a two-stage framework for intent-conditioned counterspeech generation. QUARC leverages vector-quantized representations learned for each intent category along with PerFuMe, a novel fusion module to incorporate intent-specific information into the model. Our evaluation demonstrates that QUARC outperforms several baselines by an average of 10% across evaluation metrics. An extensive human evaluation supplements our hypothesis of better and more appropriate responses than comparative systems.
LAHM : Large Annotated Dataset for Multi-Domain and Multilingual Hate Speech Identification
Apr 03, 2023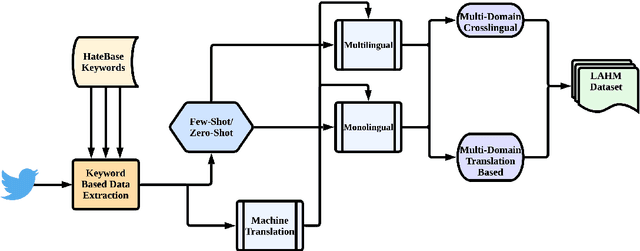
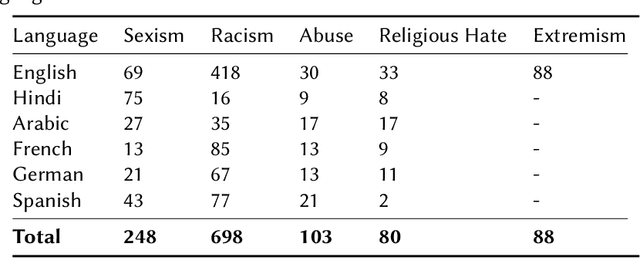
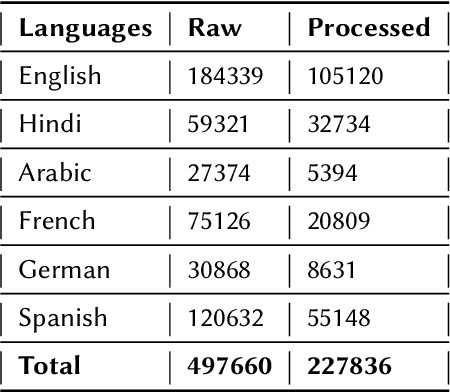
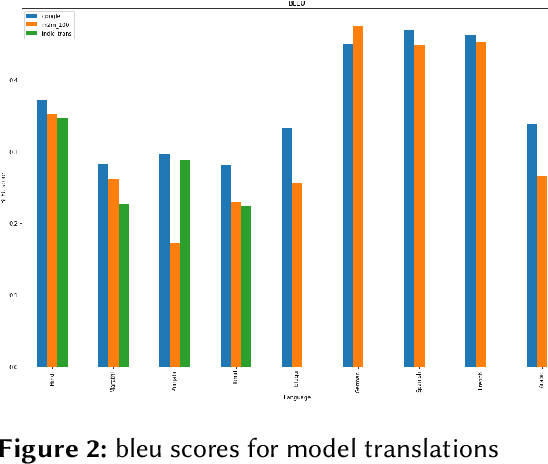
Current research on hate speech analysis is typically oriented towards monolingual and single classification tasks. In this paper, we present a new multilingual hate speech analysis dataset for English, Hindi, Arabic, French, German and Spanish languages for multiple domains across hate speech - Abuse, Racism, Sexism, Religious Hate and Extremism. To the best of our knowledge, this paper is the first to address the problem of identifying various types of hate speech in these five wide domains in these six languages. In this work, we describe how we created the dataset, created annotations at high level and low level for different domains and how we use it to test the current state-of-the-art multilingual and multitask learning approaches. We evaluate our dataset in various monolingual, cross-lingual and machine translation classification settings and compare it against open source English datasets that we aggregated and merged for this task. Then we discuss how this approach can be used to create large scale hate-speech datasets and how to leverage our annotations in order to improve hate speech detection and classification in general.
Hatemongers ride on echo chambers to escalate hate speech diffusion
Feb 05, 2023



Recent years have witnessed a swelling rise of hateful and abusive content over online social networks. While detection and moderation of hate speech have been the early go-to countermeasures, the solution requires a deeper exploration of the dynamics of hate generation and propagation. We analyze more than 32 million posts from over 6.8 million users across three popular online social networks to investigate the interrelations between hateful behavior, information dissemination, and polarised organization mediated by echo chambers. We find that hatemongers play a more crucial role in governing the spread of information compared to singled-out hateful content. This observation holds for both the growth of information cascades as well as the conglomeration of hateful actors. Dissection of the core-wise distribution of these networks points towards the fact that hateful users acquire a more well-connected position in the social network and often flock together to build up information cascades. We observe that this cohesion is far from mere organized behavior; instead, in these networks, hatemongers dominate the echo chambers -- groups of users actively align themselves to specific ideological positions. The observed dominance of hateful users to inflate information cascades is primarily via user interactions amplified within these echo chambers. We conclude our study with a cautionary note that popularity-based recommendation of content is susceptible to be exploited by hatemongers given their potential to escalate content popularity via echo-chambered interactions.
Logically at Factify 2023: A Multi-Modal Fact Checking System Based on Evidence Retrieval techniques and Transformer Encoder Architecture
Jan 09, 2023


In this paper, we present the Logically submissions to De-Factify 2 challenge (DE-FACTIFY 2023) on the task 1 of Multi-Modal Fact Checking. We describes our submissions to this challenge including explored evidence retrieval and selection techniques, pre-trained cross-modal and unimodal models, and a cross-modal veracity model based on the well established Transformer Encoder (TE) architecture which is heavily relies on the concept of self-attention. Exploratory analysis is also conducted on this Factify 2 data set that uncovers the salient multi-modal patterns and hypothesis motivating the architecture proposed in this work. A series of preliminary experiments were done to investigate and benchmarking different pre-trained embedding models, evidence retrieval settings and thresholds. The final system, a standard two-stage evidence based veracity detection system, yields weighted avg. 0.79 on both val set and final blind test set on the task 1, which achieves 3rd place with a small margin to the top performing system on the leaderboard among 9 participants.
Logically at the Factify 2022: Multimodal Fact Verification
Dec 16, 2021
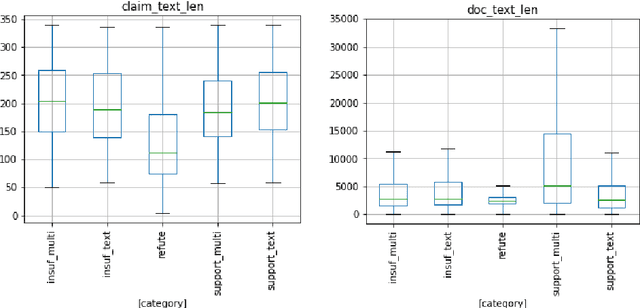

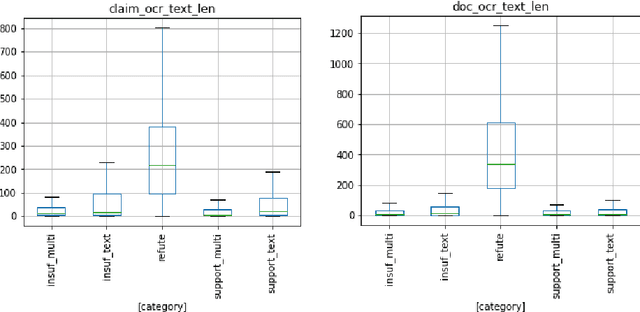
This paper describes our participant system for the multi-modal fact verification (Factify) challenge at AAAI 2022. Despite the recent advance in text based verification techniques and large pre-trained multimodal models cross vision and language, very limited work has been done in applying multimodal techniques to automate fact checking process, particularly considering the increasing prevalence of claims and fake news about images and videos on social media. In our work, the challenge is treated as multimodal entailment task and framed as multi-class classification. Two baseline approaches are proposed and explored including an ensemble model (combining two uni-modal models) and a multi-modal attention network (modeling the interaction between image and text pair from claim and evidence document). We conduct several experiments investigating and benchmarking different SoTA pre-trained transformers and vision models in this work. Our best model is ranked first in leaderboard which obtains a weighted average F-measure of 0.77 on both validation and test set. Exploratory analysis of dataset is also carried out on the Factify data set and uncovers salient patterns and issues (e.g., word overlapping, visual entailment correlation, source bias) that motivates our hypothesis. Finally, we highlight challenges of the task and multimodal dataset for future research.