 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
Community Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025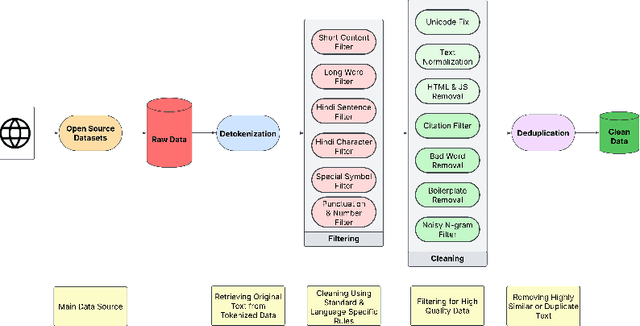

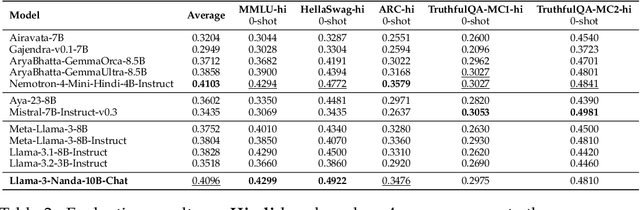

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Hatemongers ride on echo chambers to escalate hate speech diffusion
Feb 05, 2023



Recent years have witnessed a swelling rise of hateful and abusive content over online social networks. While detection and moderation of hate speech have been the early go-to countermeasures, the solution requires a deeper exploration of the dynamics of hate generation and propagation. We analyze more than 32 million posts from over 6.8 million users across three popular online social networks to investigate the interrelations between hateful behavior, information dissemination, and polarised organization mediated by echo chambers. We find that hatemongers play a more crucial role in governing the spread of information compared to singled-out hateful content. This observation holds for both the growth of information cascades as well as the conglomeration of hateful actors. Dissection of the core-wise distribution of these networks points towards the fact that hateful users acquire a more well-connected position in the social network and often flock together to build up information cascades. We observe that this cohesion is far from mere organized behavior; instead, in these networks, hatemongers dominate the echo chambers -- groups of users actively align themselves to specific ideological positions. The observed dominance of hateful users to inflate information cascades is primarily via user interactions amplified within these echo chambers. We conclude our study with a cautionary note that popularity-based recommendation of content is susceptible to be exploited by hatemongers given their potential to escalate content popularity via echo-chambered interactions.
K-12BERT: BERT for K-12 education
May 24, 2022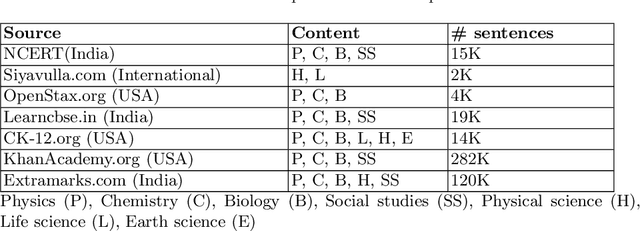
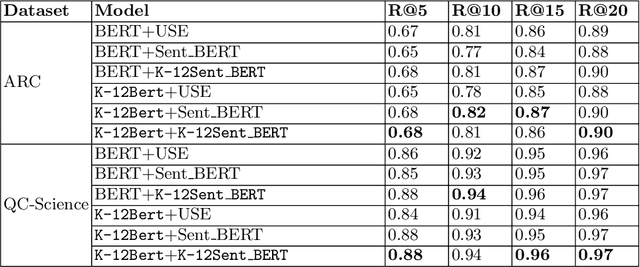
Online education platforms are powered by various NLP pipelines, which utilize models like BERT to aid in content curation. Since the inception of the pre-trained language models like BERT, there have also been many efforts toward adapting these pre-trained models to specific domains. However, there has not been a model specifically adapted for the education domain (particularly K-12) across subjects to the best of our knowledge. In this work, we propose to train a language model on a corpus of data curated by us across multiple subjects from various sources for K-12 education. We also evaluate our model, K12-BERT, on downstream tasks like hierarchical taxonomy tagging.