Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-12BERT: BERT for K-12 education
Paper and Code
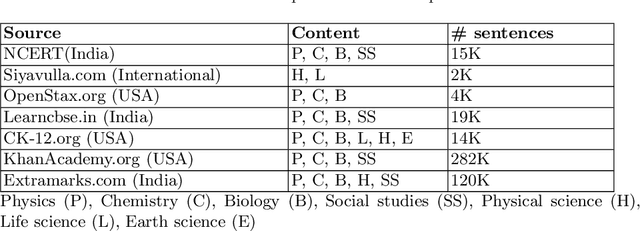
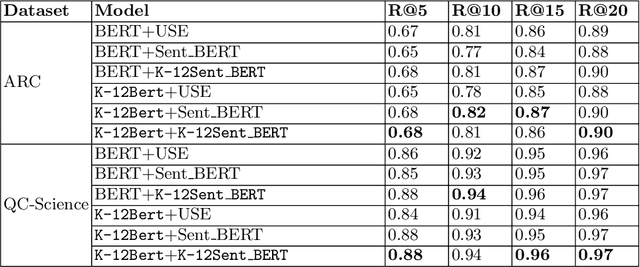
Online education platforms are powered by various NLP pipelines, which utilize models like BERT to aid in content curation. Since the inception of the pre-trained language models like BERT, there have also been many efforts toward adapting these pre-trained models to specific domains. However, there has not been a model specifically adapted for the education domain (particularly K-12) across subjects to the best of our knowledge. In this work, we propose to train a language model on a corpus of data curated by us across multiple subjects from various sources for K-12 education. We also evaluate our model, K12-BERT, on downstream tasks like hierarchical taxonomy tagging.
* 4 pages
View paper on