 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAT-Phys: Fast Material Property Field Prediction from Structured 3D Latents
Mar 25, 2026Estimating the material property field of 3D assets is critical for physics-based simulation, robotics, and digital twin generation. Existing vision-based approaches are either too expensive and slow or rely on 3D information. We present SLAT-Phys, an end-to-end method that predicts spatially varying material property fields of 3D assets directly from a single RGB image without explicit 3D reconstruction. Our approach leverages spatially organised latent features from a pretrained 3D asset generation model that encodes rich geometry and semantic prior, and trains a lightweight neural decoder to estimate Young's modulus, density, and Poisson's ratio. The coarse volumetric layout and semantic cues of the latent representation about object geometry and appearance enable accurate material estimation. Our experiments demonstrate that our method provides competitive accuracy in predicting continuous material parameters when compared against prior approaches, while significantly reducing computation time. In particular, SLAT-Phys requires only 9.9 seconds per object on an NVIDIA RTXA5000 GPU and avoids reconstruction and voxelization preprocessing. This results in 120x speedup compared to prior methods and enables faster material property estimation from a single image.
BLAZER: Bootstrapping LLM-based Manipulation Agents with Zero-Shot Data Generation
Oct 09, 2025Scaling data and models has played a pivotal role in the remarkable progress of computer vision and language. Inspired by these domains, recent efforts in robotics have similarly focused on scaling both data and model size to develop more generalizable and robust policies. However, unlike vision and language, robotics lacks access to internet-scale demonstrations across diverse robotic tasks and environments. As a result, the scale of existing datasets typically suffers from the need for manual data collection and curation. To address this problem, here we propose BLAZER, a framework that learns manipulation policies from automatically generated training data. We build on the zero-shot capabilities of LLM planners and automatically generate demonstrations for diverse manipulation tasks in simulation. Successful examples are then used to finetune an LLM and to improve its planning capabilities without human supervision. Notably, while BLAZER training requires access to the simulator's state, we demonstrate direct transfer of acquired skills to sensor-based manipulation. Through extensive experiments, we show BLAZER to significantly improve zero-shot manipulation in both simulated and real environments. Moreover, BLAZER improves on tasks outside of its training pool and enables downscaling of LLM models. Our code and data will be made publicly available on the project page.
Llama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025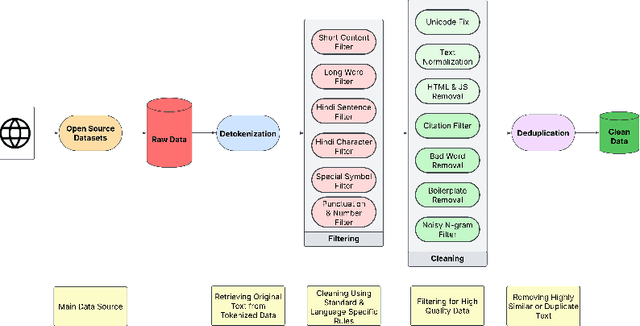

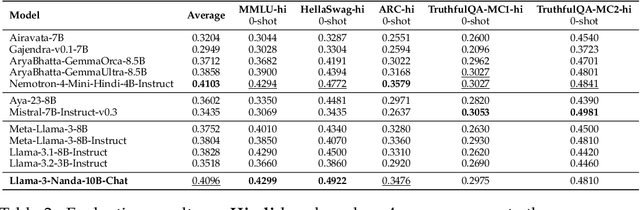

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
MALT: Improving Reasoning with Multi-Agent LLM Training
Dec 02, 2024


Enabling effective collaboration among LLMs is a crucial step toward developing autonomous systems capable of solving complex problems. While LLMs are typically used as single-model generators, where humans critique and refine their outputs, the potential for jointly-trained collaborative models remains largely unexplored. Despite promising results in multi-agent communication and debate settings, little progress has been made in training models to work together on tasks. In this paper, we present a first step toward "Multi-agent LLM training" (MALT) on reasoning problems. Our approach employs a sequential multi-agent setup with heterogeneous LLMs assigned specialized roles: a generator, verifier, and refinement model iteratively solving problems. We propose a trajectory-expansion-based synthetic data generation process and a credit assignment strategy driven by joint outcome based rewards. This enables our post-training setup to utilize both positive and negative trajectories to autonomously improve each model's specialized capabilities as part of a joint sequential system. We evaluate our approach across MATH, GSM8k, and CQA, where MALT on Llama 3.1 8B models achieves relative improvements of 14.14%, 7.12%, and 9.40% respectively over the same baseline model. This demonstrates an early advance in multi-agent cooperative capabilities for performance on mathematical and common sense reasoning questions. More generally, our work provides a concrete direction for research around multi-agent LLM training approaches.
MALMM: Multi-Agent Large Language Models for Zero-Shot Robotics Manipulation
Nov 26, 2024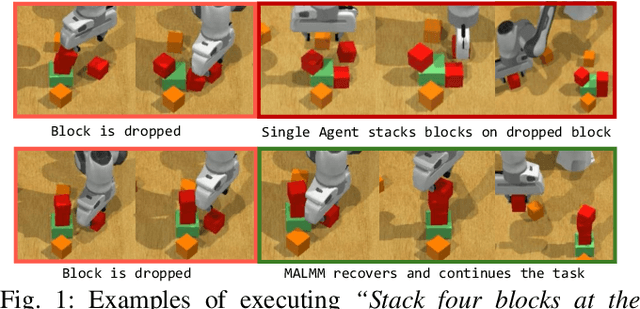
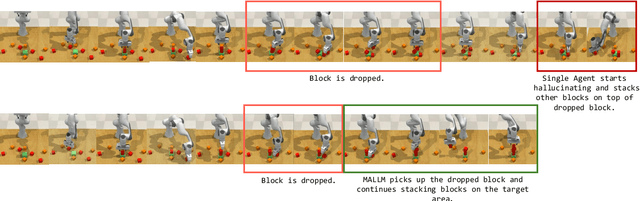
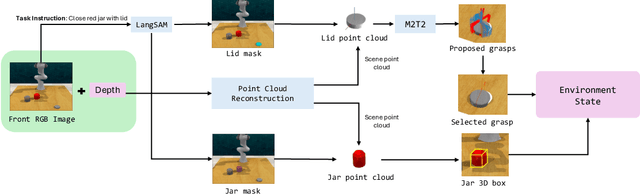

Large Language Models (LLMs) have demonstrated remarkable planning abilities across various domains, including robotics manipulation and navigation. While recent efforts in robotics have leveraged LLMs both for high-level and low-level planning, these approaches often face significant challenges, such as hallucinations in long-horizon tasks and limited adaptability due to the generation of plans in a single pass without real-time feedback. To address these limitations, we propose a novel multi-agent LLM framework, Multi-Agent Large Language Model for Manipulation (MALMM) that distributes high-level planning and low-level control code generation across specialized LLM agents, supervised by an additional agent that dynamically manages transitions. By incorporating observations from the environment after each step, our framework effectively handles intermediate failures and enables adaptive re-planning. Unlike existing methods, our approach does not rely on pre-trained skill policies or in-context learning examples and generalizes to a variety of new tasks. We evaluate our approach on nine RLBench tasks, including long-horizon tasks, and demonstrate its ability to solve robotics manipulation in a zero-shot setting, thereby overcoming key limitations of existing LLM-based manipulation methods.
MediTOD: An English Dialogue Dataset for Medical History Taking with Comprehensive Annotations
Oct 18, 2024

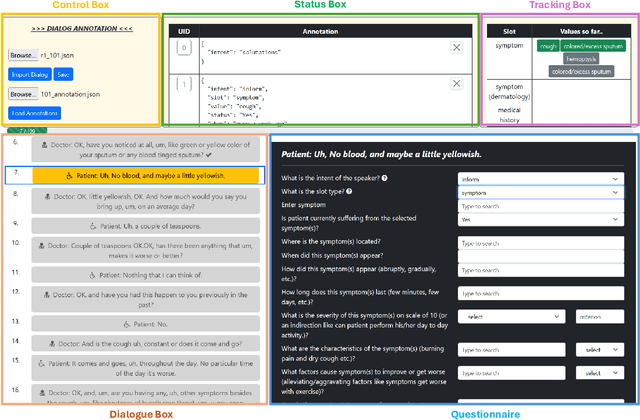

Medical task-oriented dialogue systems can assist doctors by collecting patient medical history, aiding in diagnosis, or guiding treatment selection, thereby reducing doctor burnout and expanding access to medical services. However, doctor-patient dialogue datasets are not readily available, primarily due to privacy regulations. Moreover, existing datasets lack comprehensive annotations involving medical slots and their different attributes, such as symptoms and their onset, progression, and severity. These comprehensive annotations are crucial for accurate diagnosis. Finally, most existing datasets are non-English, limiting their utility for the larger research community. In response, we introduce MediTOD, a new dataset of doctor-patient dialogues in English for the medical history-taking task. Collaborating with doctors, we devise a questionnaire-based labeling scheme tailored to the medical domain. Then, medical professionals create the dataset with high-quality comprehensive annotations, capturing medical slots and their attributes. We establish benchmarks in supervised and few-shot settings on MediTOD for natural language understanding, policy learning, and natural language generation subtasks, evaluating models from both TOD and biomedical domains. We make MediTOD publicly available for future research.
Synergizing In-context Learning with Hints for End-to-end Task-oriented Dialog Systems
May 24, 2024Large language models (LLM) based end-to-end task-oriented dialog (TOD) systems built using few-shot (in-context) learning perform better than supervised models only when the train data is limited. This is due to the inherent ability of LLMs to learn any task with just a few demonstrations. As the number of train dialogs increases, supervised SoTA models surpass in-context learning LLMs as they learn to better align with the style of the system responses in the training data, which LLMs struggle to mimic. In response, we propose SyncTOD, which synergizes LLMs with useful hints about the task for improved alignment. At a high level, SyncTOD trains auxiliary models to provide these hints and select exemplars for the in-context prompts. With ChatGPT, SyncTOD achieves superior performance compared to LLM-based baselines and SoTA models in low-data settings, while retaining competitive performance in full-data settings
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024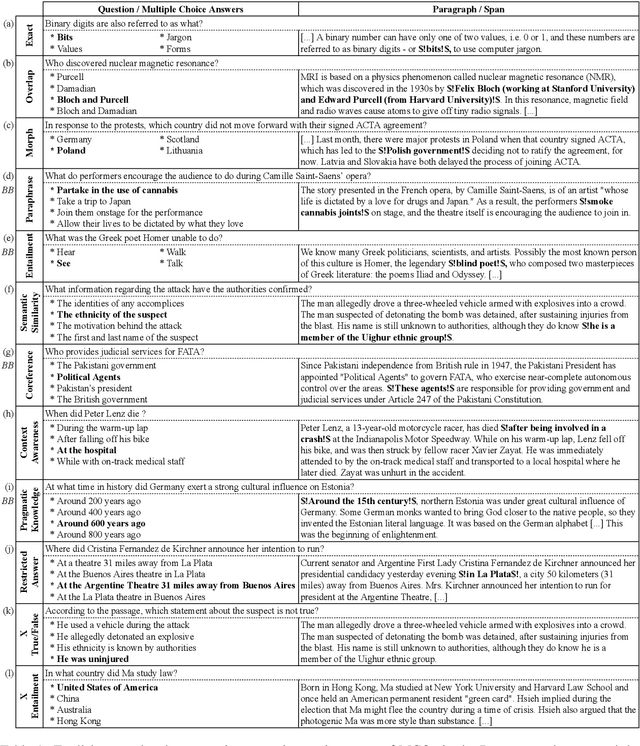

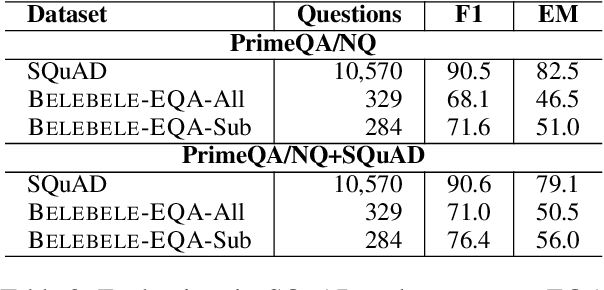
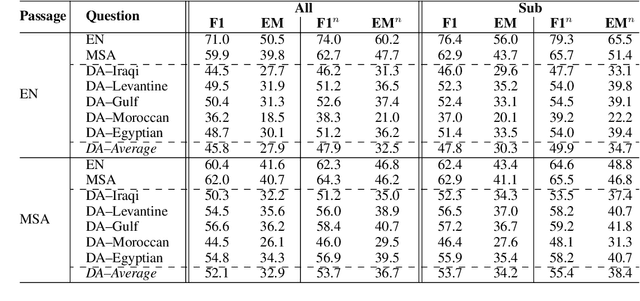
The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
EXAMS-V: A Multi-Discipline Multilingual Multimodal Exam Benchmark for Evaluating Vision Language Models
Mar 15, 2024



We introduce EXAMS-V, a new challenging multi-discipline multimodal multilingual exam benchmark for evaluating vision language models. It consists of 20,932 multiple-choice questions across 20 school disciplines covering natural science, social science, and other miscellaneous studies, e.g., religion, fine arts, business, etc. EXAMS-V includes a variety of multimodal features such as text, images, tables, figures, diagrams, maps, scientific symbols, and equations. The questions come in 11 languages from 7 language families. Unlike existing benchmarks, EXAMS-V is uniquely curated by gathering school exam questions from various countries, with a variety of education systems. This distinctive approach calls for intricate reasoning across diverse languages and relies on region-specific knowledge. Solving the problems in the dataset requires advanced perception and joint reasoning over the text and the visual content of the image. Our evaluation results demonstrate that this is a challenging dataset, which is difficult even for advanced vision-text models such as GPT-4V and Gemini; this underscores the inherent complexity of the dataset and its significance as a future benchmark.
Factuality of Large Language Models in the Year 2024
Feb 09, 2024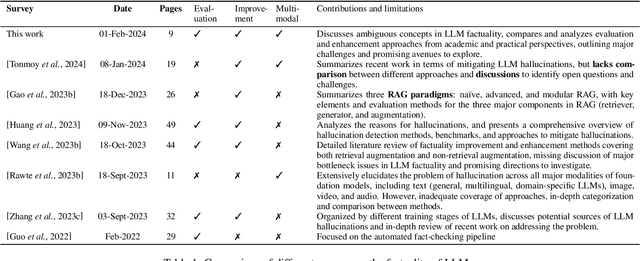
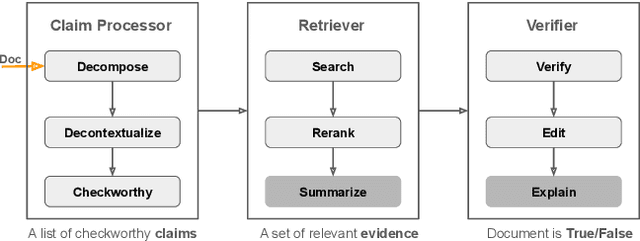
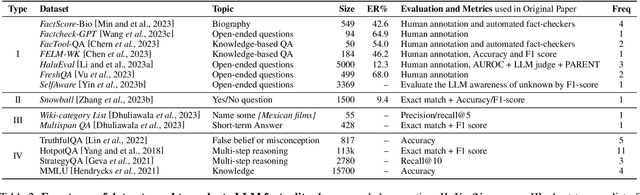
Large language models (LLMs), especially when instruction-tuned for chat, have become part of our daily lives, freeing people from the process of searching, extracting, and integrating information from multiple sources by offering a straightforward answer to a variety of questions in a single place. Unfortunately, in many cases, LLM responses are factually incorrect, which limits their applicability in real-world scenarios. As a result, research on evaluating and improving the factuality of LLMs has attracted a lot of research attention recently. In this survey, we critically analyze existing work with the aim to identify the major challenges and their associated causes, pointing out to potential solutions for improving the factuality of LLMs, and analyzing the obstacles to automated factuality evaluation for open-ended text generation. We further offer an outlook on where future research should go.