 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI-Generated Image Detection RewardBench
Nov 15, 2025Conventional, classification-based AI-generated image detection methods cannot explain why an image is considered real or AI-generated in a way a human expert would, which reduces the trustworthiness and persuasiveness of these detection tools for real-world applications. Leveraging Multimodal Large Language Models (MLLMs) has recently become a trending solution to this issue. Further, to evaluate the quality of generated explanations, a common approach is to adopt an "MLLM as a judge" methodology to evaluate explanations generated by other MLLMs. However, how well those MLLMs perform when judging explanations for AI-generated image detection generated by themselves or other MLLMs has not been well studied. We therefore propose \textbf{XAIGID-RewardBench}, the first benchmark designed to evaluate the ability of current MLLMs to judge the quality of explanations about whether an image is real or AI-generated. The benchmark consists of approximately 3,000 annotated triplets sourced from various image generation models and MLLMs as policy models (detectors) to assess the capabilities of current MLLMs as reward models (judges). Our results show that the current best reward model scored 88.76\% on this benchmark (while human inter-annotator agreement reaches 98.30\%), demonstrating that a visible gap remains between the reasoning abilities of today's MLLMs and human-level performance. In addition, we provide an analysis of common pitfalls that these models frequently encounter. Code and benchmark are available at https://github.com/RewardBench/XAIGID-RewardBench.
BLAZER: Bootstrapping LLM-based Manipulation Agents with Zero-Shot Data Generation
Oct 09, 2025Scaling data and models has played a pivotal role in the remarkable progress of computer vision and language. Inspired by these domains, recent efforts in robotics have similarly focused on scaling both data and model size to develop more generalizable and robust policies. However, unlike vision and language, robotics lacks access to internet-scale demonstrations across diverse robotic tasks and environments. As a result, the scale of existing datasets typically suffers from the need for manual data collection and curation. To address this problem, here we propose BLAZER, a framework that learns manipulation policies from automatically generated training data. We build on the zero-shot capabilities of LLM planners and automatically generate demonstrations for diverse manipulation tasks in simulation. Successful examples are then used to finetune an LLM and to improve its planning capabilities without human supervision. Notably, while BLAZER training requires access to the simulator's state, we demonstrate direct transfer of acquired skills to sensor-based manipulation. Through extensive experiments, we show BLAZER to significantly improve zero-shot manipulation in both simulated and real environments. Moreover, BLAZER improves on tasks outside of its training pool and enables downscaling of LLM models. Our code and data will be made publicly available on the project page.
MALMM: Multi-Agent Large Language Models for Zero-Shot Robotics Manipulation
Nov 26, 2024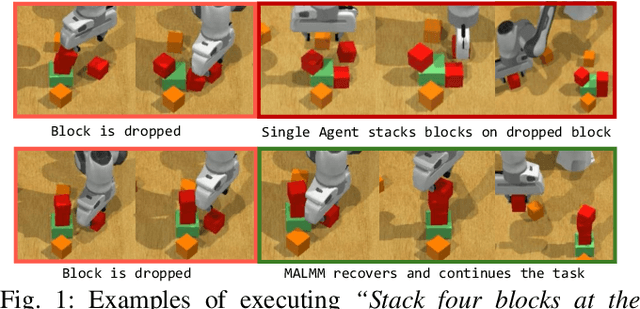
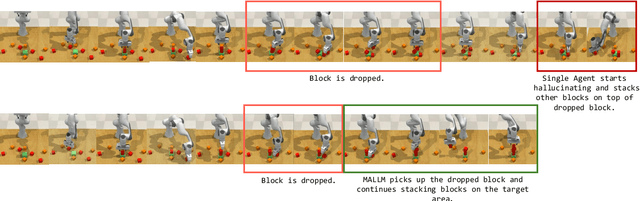
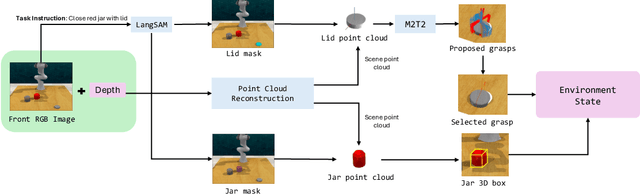

Large Language Models (LLMs) have demonstrated remarkable planning abilities across various domains, including robotics manipulation and navigation. While recent efforts in robotics have leveraged LLMs both for high-level and low-level planning, these approaches often face significant challenges, such as hallucinations in long-horizon tasks and limited adaptability due to the generation of plans in a single pass without real-time feedback. To address these limitations, we propose a novel multi-agent LLM framework, Multi-Agent Large Language Model for Manipulation (MALMM) that distributes high-level planning and low-level control code generation across specialized LLM agents, supervised by an additional agent that dynamically manages transitions. By incorporating observations from the environment after each step, our framework effectively handles intermediate failures and enables adaptive re-planning. Unlike existing methods, our approach does not rely on pre-trained skill policies or in-context learning examples and generalizes to a variety of new tasks. We evaluate our approach on nine RLBench tasks, including long-horizon tasks, and demonstrate its ability to solve robotics manipulation in a zero-shot setting, thereby overcoming key limitations of existing LLM-based manipulation methods.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.