 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
Explainable AI-Generated Image Detection RewardBench
Nov 15, 2025Conventional, classification-based AI-generated image detection methods cannot explain why an image is considered real or AI-generated in a way a human expert would, which reduces the trustworthiness and persuasiveness of these detection tools for real-world applications. Leveraging Multimodal Large Language Models (MLLMs) has recently become a trending solution to this issue. Further, to evaluate the quality of generated explanations, a common approach is to adopt an "MLLM as a judge" methodology to evaluate explanations generated by other MLLMs. However, how well those MLLMs perform when judging explanations for AI-generated image detection generated by themselves or other MLLMs has not been well studied. We therefore propose \textbf{XAIGID-RewardBench}, the first benchmark designed to evaluate the ability of current MLLMs to judge the quality of explanations about whether an image is real or AI-generated. The benchmark consists of approximately 3,000 annotated triplets sourced from various image generation models and MLLMs as policy models (detectors) to assess the capabilities of current MLLMs as reward models (judges). Our results show that the current best reward model scored 88.76\% on this benchmark (while human inter-annotator agreement reaches 98.30\%), demonstrating that a visible gap remains between the reasoning abilities of today's MLLMs and human-level performance. In addition, we provide an analysis of common pitfalls that these models frequently encounter. Code and benchmark are available at https://github.com/RewardBench/XAIGID-RewardBench.
Co-PatcheR: Collaborative Software Patching with Component(s)-specific Small Reasoning Models
May 25, 2025



Motivated by the success of general-purpose large language models (LLMs) in software patching, recent works started to train specialized patching models. Most works trained one model to handle the end-to-end patching pipeline (including issue localization, patch generation, and patch validation). However, it is hard for a small model to handle all tasks, as different sub-tasks have different workflows and require different expertise. As such, by using a 70 billion model, SOTA methods can only reach up to 41% resolved rate on SWE-bench-Verified. Motivated by the collaborative nature, we propose Co-PatcheR, the first collaborative patching system with small and specialized reasoning models for individual components. Our key technique novelties are the specific task designs and training recipes. First, we train a model for localization and patch generation. Our localization pinpoints the suspicious lines through a two-step procedure, and our generation combines patch generation and critique. We then propose a hybrid patch validation that includes two models for crafting issue-reproducing test cases with and without assertions and judging patch correctness, followed by a majority vote-based patch selection. Through extensive evaluation, we show that Co-PatcheR achieves 46% resolved rate on SWE-bench-Verified with only 3 x 14B models. This makes Co-PatcheR the best patcher with specialized models, requiring the least training resources and the smallest models. We conduct a comprehensive ablation study to validate our recipes, as well as our choice of training data number, model size, and testing-phase scaling strategy.
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
May 20, 2025Large Vision-Language Models (VLMs) have shown strong capabilities in multimodal understanding and reasoning, yet they are primarily constrained by text-based reasoning processes. However, achieving seamless integration of visual and textual reasoning which mirrors human cognitive processes remains a significant challenge. In particular, effectively incorporating advanced visual input processing into reasoning mechanisms is still an open question. Thus, in this paper, we explore the interleaved multimodal reasoning paradigm and introduce DeepEyes, a model with "thinking with images" capabilities incentivized through end-to-end reinforcement learning without the need for cold-start SFT. Notably, this ability emerges natively within the model itself, leveraging its inherent grounding ability as a tool instead of depending on separate specialized models. Specifically, we propose a tool-use-oriented data selection mechanism and a reward strategy to encourage successful tool-assisted reasoning trajectories. DeepEyes achieves significant performance gains on fine-grained perception and reasoning benchmarks and also demonstrates improvement in grounding, hallucination, and mathematical reasoning tasks. Interestingly, we observe the distinct evolution of tool-calling behavior from initial exploration to efficient and accurate exploitation, and diverse thinking patterns that closely mirror human visual reasoning processes. Code is available at https://github.com/Visual-Agent/DeepEyes.
Contact Complexity in Customer Service
Feb 24, 2024Customers who reach out for customer service support may face a range of issues that vary in complexity. Routing high-complexity contacts to junior agents can lead to multiple transfers or repeated contacts, while directing low-complexity contacts to senior agents can strain their capacity to assist customers who need professional help. To tackle this, a machine learning model that accurately predicts the complexity of customer issues is highly desirable. However, defining the complexity of a contact is a difficult task as it is a highly abstract concept. While consensus-based data annotation by experienced agents is a possible solution, it is time-consuming and costly. To overcome these challenges, we have developed a novel machine learning approach to define contact complexity. Instead of relying on human annotation, we trained an AI expert model to mimic the behavior of agents and evaluate each contact's complexity based on how the AI expert responds. If the AI expert is uncertain or lacks the skills to comprehend the contact transcript, it is considered a high-complexity contact. Our method has proven to be reliable, scalable, and cost-effective based on the collected data.
Teacher-Student Learning on Complexity in Intelligent Routing
Feb 24, 2024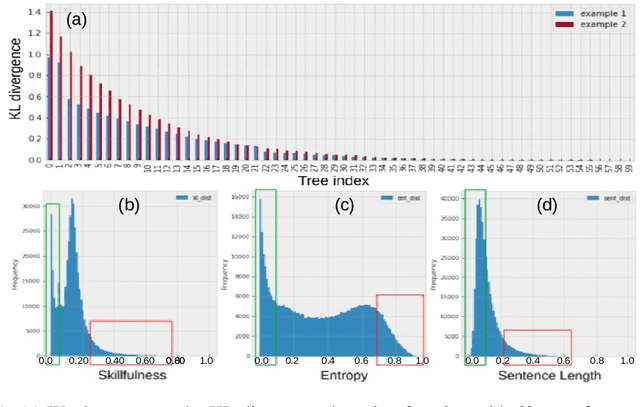
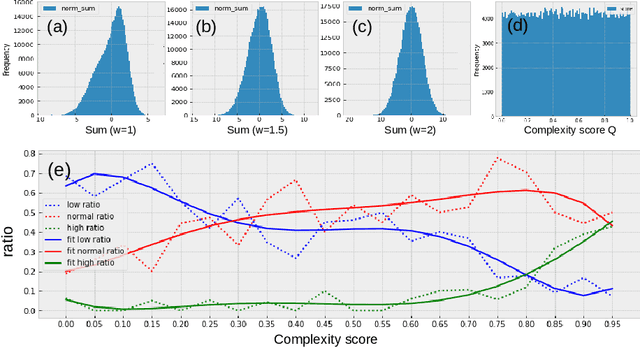

Customer service is often the most time-consuming aspect for e-commerce websites, with each contact typically taking 10-15 minutes. Effectively routing customers to appropriate agents without transfers is therefore crucial for e-commerce success. To this end, we have developed a machine learning framework that predicts the complexity of customer contacts and routes them to appropriate agents accordingly. The framework consists of two parts. First, we train a teacher model to score the complexity of a contact based on the post-contact transcripts. Then, we use the teacher model as a data annotator to provide labels to train a student model that predicts the complexity based on pre-contact data only. Our experiments show that such a framework is successful and can significantly improve customer experience. We also propose a useful metric called complexity AUC that evaluates the effectiveness of customer service at a statistical level.
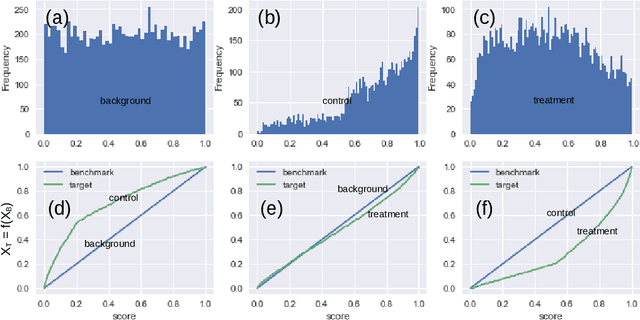
Uncovering Customer Issues through Topological Natural Language Analysis
Feb 24, 2024E-commerce companies deal with a high volume of customer service requests daily. While a simple annotation system is often used to summarize the topics of customer contacts, thoroughly exploring each specific issue can be challenging. This presents a critical concern, especially during an emerging outbreak where companies must quickly identify and address specific issues. To tackle this challenge, we propose a novel machine learning algorithm that leverages natural language techniques and topological data analysis to monitor emerging and trending customer issues. Our approach involves an end-to-end deep learning framework that simultaneously tags the primary question sentence of each customer's transcript and generates sentence embedding vectors. We then whiten the embedding vectors and use them to construct an undirected graph. From there, we define trending and emerging issues based on the topological properties of each transcript. We have validated our results through various methods and found that they are highly consistent with news sources.
Event Camera-based Visual Odometry for Dynamic Motion Tracking of a Legged Robot Using Adaptive Time Surface
May 15, 2023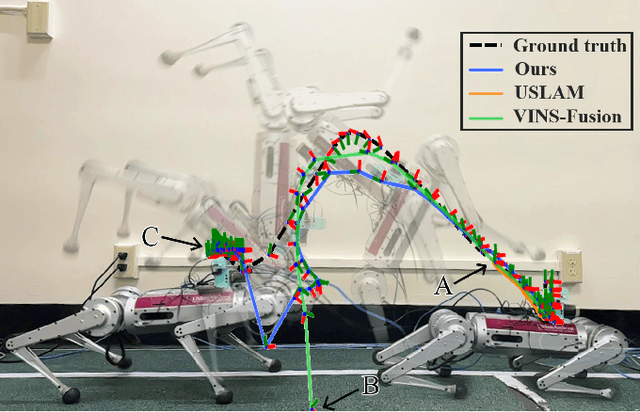
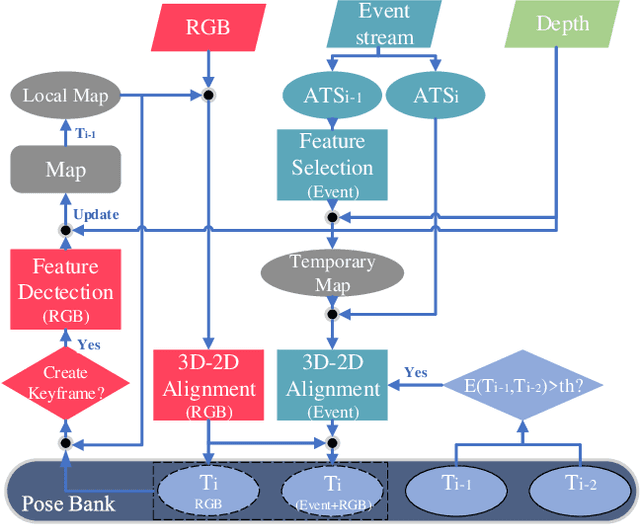
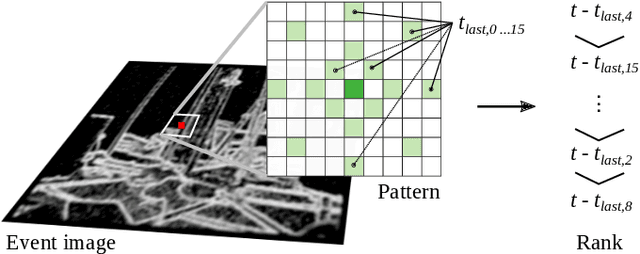

Our paper proposes a direct sparse visual odometry method that combines event and RGB-D data to estimate the pose of agile-legged robots during dynamic locomotion and acrobatic behaviors. Event cameras offer high temporal resolution and dynamic range, which can eliminate the issue of blurred RGB images during fast movements. This unique strength holds a potential for accurate pose estimation of agile-legged robots, which has been a challenging problem to tackle. Our framework leverages the benefits of both RGB-D and event cameras to achieve robust and accurate pose estimation, even during dynamic maneuvers such as jumping and landing a quadruped robot, the Mini-Cheetah. Our major contributions are threefold: Firstly, we introduce an adaptive time surface (ATS) method that addresses the whiteout and blackout issue in conventional time surfaces by formulating pixel-wise decay rates based on scene complexity and motion speed. Secondly, we develop an effective pixel selection method that directly samples from event data and applies sample filtering through ATS, enabling us to pick pixels on distinct features. Lastly, we propose a nonlinear pose optimization formula that simultaneously performs 3D-2D alignment on both RGB-based and event-based maps and images, allowing the algorithm to fully exploit the benefits of both data streams. We extensively evaluate the performance of our framework on both public datasets and our own quadruped robot dataset, demonstrating its effectiveness in accurately estimating the pose of agile robots during dynamic movements.
A Masked Bounding-Box Selection Based ResNet Predictor for Text Rotation Prediction
Sep 06, 2022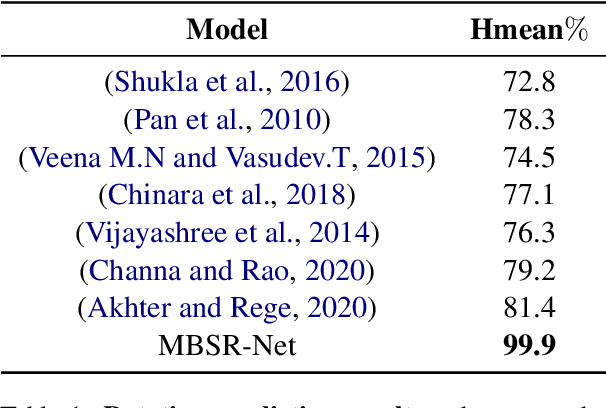
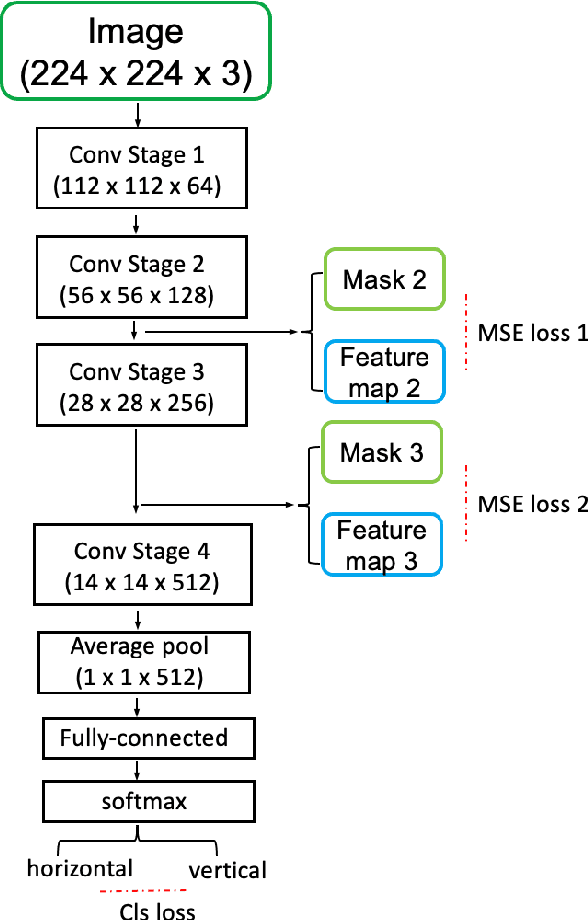
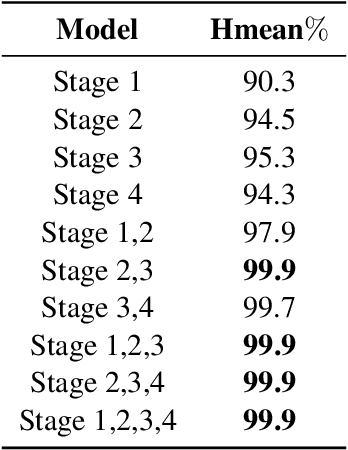

The existing Optical Character Recognition (OCR) systems are capable of recognizing images with horizontal texts. However, when the rotation of the texts increases, it becomes harder to recognizing these texts. The performance of the OCR systems decreases. Thus predicting the rotations of the texts and correcting the images are important. Previous work mainly uses traditional Computer Vision methods like Hough Transform and Deep Learning methods like Convolutional Neural Network. However, all of these methods are prone to background noises commonly existing in general images with texts. To tackle this problem, in this work, we introduce a new masked bounding-box selection method, that incorporating the bounding box information into the system. By training a ResNet predictor to focus on the bounding box as the region of interest (ROI), the predictor learns to overlook the background noises. Evaluations on the text rotation prediction tasks show that our method improves the performance by a large margin.