 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Shoot The Breeze: Topic Continuity Model Using Nonlinear Naive Bayes With Attention
Feb 10, 2026Utilizing Large Language Models (LLM) as chatbots in diverse business scenarios often presents the challenge of maintaining topic continuity. Abrupt shifts in topics can lead to poor user experiences and inefficient utilization of computational resources. In this paper, we present a topic continuity model aimed at assessing whether a response aligns with the initial conversation topic. Our model is built upon the expansion of the corresponding natural language understanding (NLU) model into quantifiable terms using a Naive Bayes approach. Subsequently, we have introduced an attention mechanism and logarithmic nonlinearity to enhance its capability to capture topic continuity. This approach allows us to convert the NLU model into an interpretable analytical formula. In contrast to many NLU models constrained by token limits, our proposed model can seamlessly handle conversations of any length with linear time complexity. Furthermore, the attention mechanism significantly improves the model's ability to identify topic continuity in complex conversations. According to our experiments, our model consistently outperforms traditional methods, particularly in handling lengthy and intricate conversations. This unique capability offers us an opportunity to ensure the responsible and interpretable use of LLMs.
* EMNLP 2024: Industry Track; 8 pages, 2 figures, 1 table
Contact Complexity in Customer Service
Feb 24, 2024Customers who reach out for customer service support may face a range of issues that vary in complexity. Routing high-complexity contacts to junior agents can lead to multiple transfers or repeated contacts, while directing low-complexity contacts to senior agents can strain their capacity to assist customers who need professional help. To tackle this, a machine learning model that accurately predicts the complexity of customer issues is highly desirable. However, defining the complexity of a contact is a difficult task as it is a highly abstract concept. While consensus-based data annotation by experienced agents is a possible solution, it is time-consuming and costly. To overcome these challenges, we have developed a novel machine learning approach to define contact complexity. Instead of relying on human annotation, we trained an AI expert model to mimic the behavior of agents and evaluate each contact's complexity based on how the AI expert responds. If the AI expert is uncertain or lacks the skills to comprehend the contact transcript, it is considered a high-complexity contact. Our method has proven to be reliable, scalable, and cost-effective based on the collected data.
Teacher-Student Learning on Complexity in Intelligent Routing
Feb 24, 2024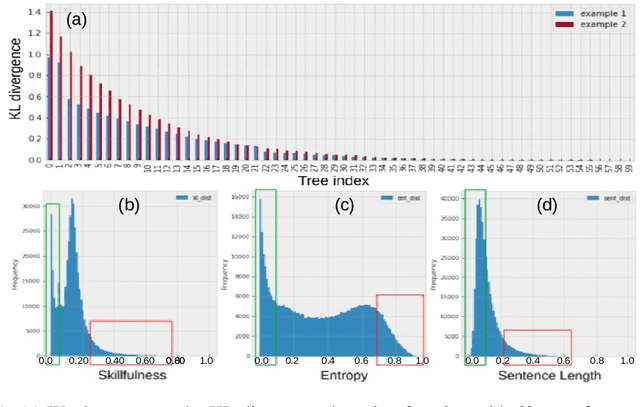
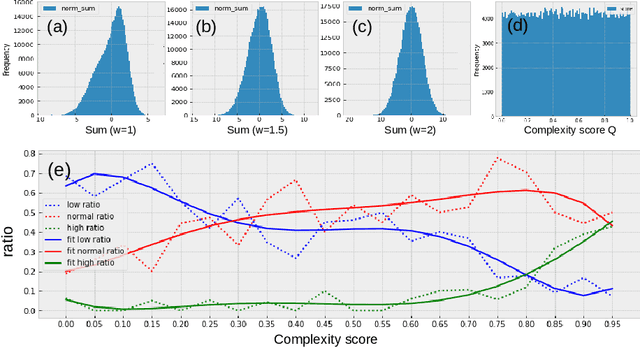
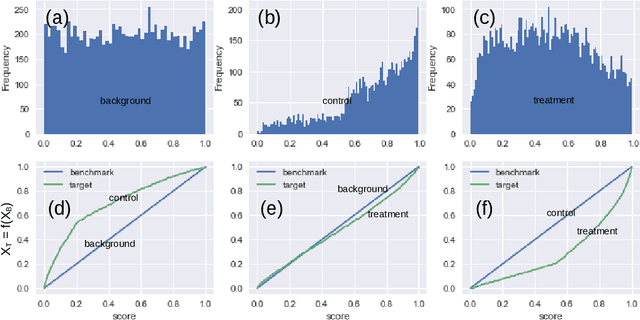

Customer service is often the most time-consuming aspect for e-commerce websites, with each contact typically taking 10-15 minutes. Effectively routing customers to appropriate agents without transfers is therefore crucial for e-commerce success. To this end, we have developed a machine learning framework that predicts the complexity of customer contacts and routes them to appropriate agents accordingly. The framework consists of two parts. First, we train a teacher model to score the complexity of a contact based on the post-contact transcripts. Then, we use the teacher model as a data annotator to provide labels to train a student model that predicts the complexity based on pre-contact data only. Our experiments show that such a framework is successful and can significantly improve customer experience. We also propose a useful metric called complexity AUC that evaluates the effectiveness of customer service at a statistical level.
Uncovering Customer Issues through Topological Natural Language Analysis
Feb 24, 2024E-commerce companies deal with a high volume of customer service requests daily. While a simple annotation system is often used to summarize the topics of customer contacts, thoroughly exploring each specific issue can be challenging. This presents a critical concern, especially during an emerging outbreak where companies must quickly identify and address specific issues. To tackle this challenge, we propose a novel machine learning algorithm that leverages natural language techniques and topological data analysis to monitor emerging and trending customer issues. Our approach involves an end-to-end deep learning framework that simultaneously tags the primary question sentence of each customer's transcript and generates sentence embedding vectors. We then whiten the embedding vectors and use them to construct an undirected graph. From there, we define trending and emerging issues based on the topological properties of each transcript. We have validated our results through various methods and found that they are highly consistent with news sources.
Universal Model in Online Customer Service
Feb 24, 2024



Building machine learning models can be a time-consuming process that often takes several months to implement in typical business scenarios. To ensure consistent model performance and account for variations in data distribution, regular retraining is necessary. This paper introduces a solution for improving online customer service in e-commerce by presenting a universal model for predict-ing labels based on customer questions, without requiring training. Our novel approach involves using machine learning techniques to tag customer questions in transcripts and create a repository of questions and corresponding labels. When a customer requests assistance, an information retrieval model searches the repository for similar questions, and statistical analysis is used to predict the corresponding label. By eliminating the need for individual model training and maintenance, our approach reduces both the model development cycle and costs. The repository only requires periodic updating to maintain accuracy.