 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning through Image Transformer
Paper and Code

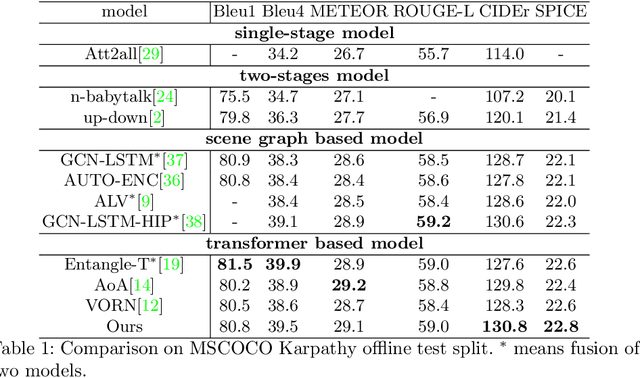
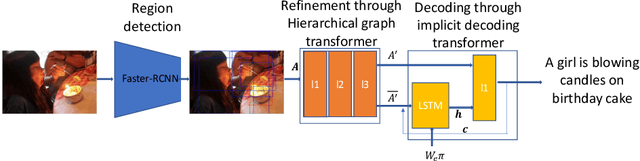
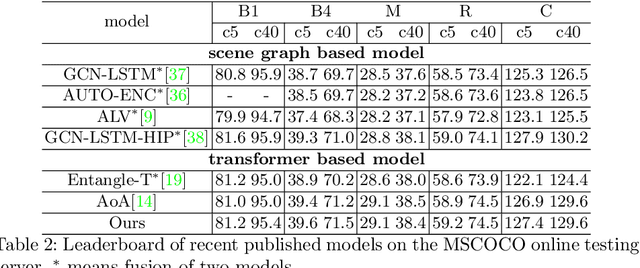
Automatic captioning of images is a task that combines the challenges of image analysis and text generation. One important aspect in captioning is the notion of attention: How to decide what to describe and in which order. Inspired by the successes in text analysis and translation, previous work have proposed the \textit{transformer} architecture for image captioning. However, the structure between the \textit{semantic units} in images (usually the detected regions from object detection model) and sentences (each single word) is different. Limited work has been done to adapt the transformer's internal architecture to images. In this work, we introduce the \textbf{\textit{image transformer}}, which consists of a modified encoding transformer and an implicit decoding transformer, motivated by the relative spatial relationship between image regions. Our design widen the original transformer layer's inner architecture to adapt to the structure of images. With only regions feature as inputs, our model achieves new state-of-the-art performance on both MSCOCO offline and online testing benchmarks.