 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Similarity between Scene Graphs and Images with Transformers
Apr 02, 2023
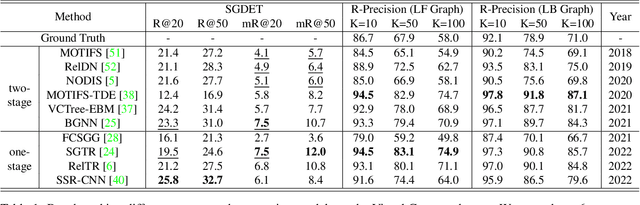
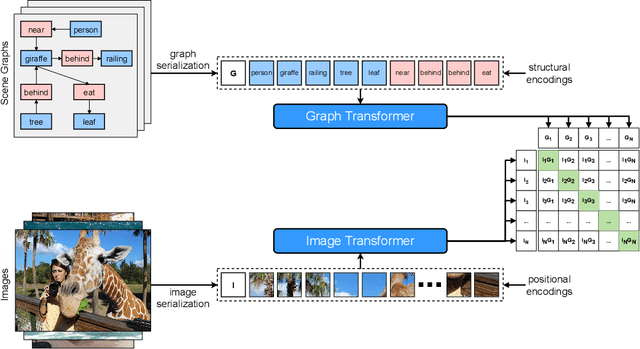

Scene graph generation is conventionally evaluated by (mean) Recall@K, which measures the ratio of correctly predicted triplets that appear in the ground truth. However, such triplet-oriented metrics cannot capture the global semantic information of scene graphs, and measure the similarity between images and generated scene graphs. The usability of scene graphs is therefore limited in downstream tasks. To address this issue, a framework that can measure the similarity of scene graphs and images is urgently required. Motivated by the successful application of Contrastive Language-Image Pre-training (CLIP), we propose a novel contrastive learning framework consisting of a graph Transformer and an image Transformer to align scene graphs and their corresponding images in the shared latent space. To enable the graph Transformer to comprehend the scene graph structure and extract representative features, we introduce a graph serialization technique that transforms a scene graph into a sequence with structural encoding. Based on our framework, we introduce R-Precision measuring image retrieval accuracy as a new evaluation metric for scene graph generation and establish new benchmarks for the Visual Genome and Open Images datasets. A series of experiments are further conducted to demonstrate the effectiveness of the graph Transformer, which shows great potential as a scene graph encoder.
Disentangled Lifespan Face Synthesis
Aug 13, 2021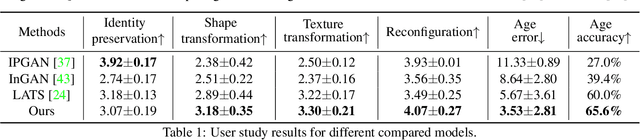
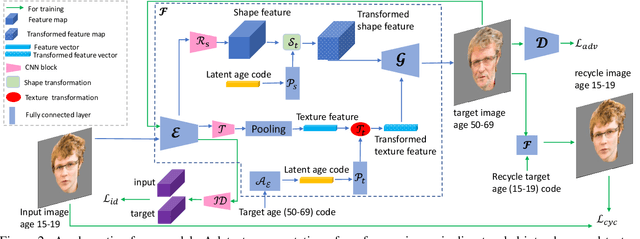

A lifespan face synthesis (LFS) model aims to generate a set of photo-realistic face images of a person's whole life, given only one snapshot as reference. The generated face image given a target age code is expected to be age-sensitive reflected by bio-plausible transformations of shape and texture, while being identity preserving. This is extremely challenging because the shape and texture characteristics of a face undergo separate and highly nonlinear transformations w.r.t. age. Most recent LFS models are based on generative adversarial networks (GANs) whereby age code conditional transformations are applied to a latent face representation. They benefit greatly from the recent advancements of GANs. However, without explicitly disentangling their latent representations into the texture, shape and identity factors, they are fundamentally limited in modeling the nonlinear age-related transformation on texture and shape whilst preserving identity. In this work, a novel LFS model is proposed to disentangle the key face characteristics including shape, texture and identity so that the unique shape and texture age transformations can be modeled effectively. This is achieved by extracting shape, texture and identity features separately from an encoder. Critically, two transformation modules, one conditional convolution based and the other channel attention based, are designed for modeling the nonlinear shape and texture feature transformations respectively. This is to accommodate their rather distinct aging processes and ensure that our synthesized images are both age-sensitive and identity preserving. Extensive experiments show that our LFS model is clearly superior to the state-of-the-art alternatives. Codes and demo are available on our project website: \url{https://senhe.github.io/projects/iccv_2021_lifespan_face}.
Spatial-Temporal Transformer for Dynamic Scene Graph Generation
Aug 08, 2021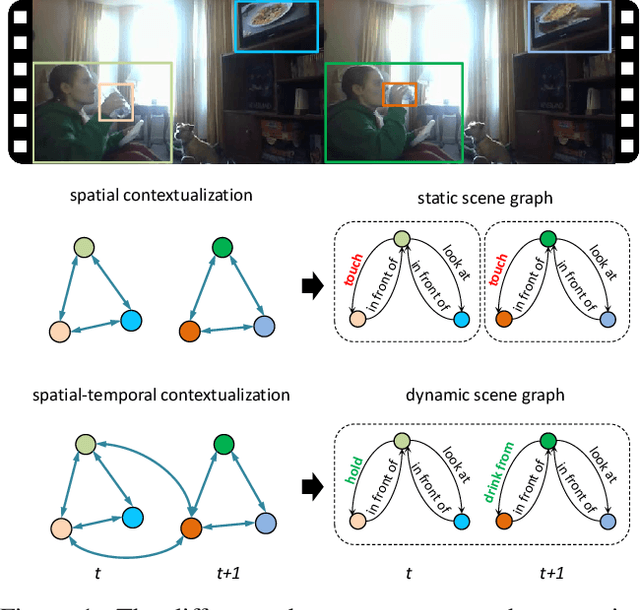

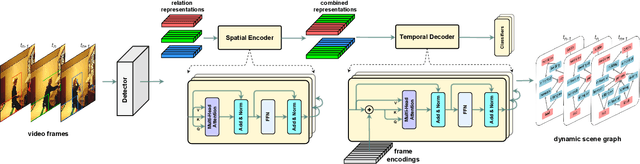
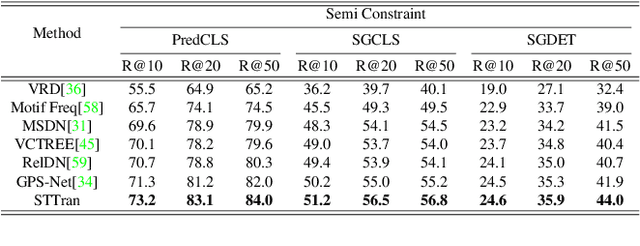
Dynamic scene graph generation aims at generating a scene graph of the given video. Compared to the task of scene graph generation from images, it is more challenging because of the dynamic relationships between objects and the temporal dependencies between frames allowing for a richer semantic interpretation. In this paper, we propose Spatial-temporal Transformer (STTran), a neural network that consists of two core modules: (1) a spatial encoder that takes an input frame to extract spatial context and reason about the visual relationships within a frame, and (2) a temporal decoder which takes the output of the spatial encoder as input in order to capture the temporal dependencies between frames and infer the dynamic relationships. Furthermore, STTran is flexible to take varying lengths of videos as input without clipping, which is especially important for long videos. Our method is validated on the benchmark dataset Action Genome (AG). The experimental results demonstrate the superior performance of our method in terms of dynamic scene graphs. Moreover, a set of ablative studies is conducted and the effect of each proposed module is justified. Code available at: https://github.com/yrcong/STTran.
Text to Image Generation with Semantic-Spatial Aware GAN
Apr 24, 2021
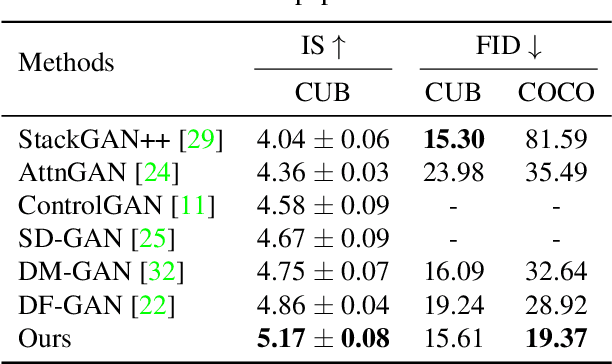


A text to image generation (T2I) model aims to generate photo-realistic images which are semantically consistent with the text descriptions. Built upon the recent advances in generative adversarial networks (GANs), existing T2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) The condition batch normalization methods are applied on the whole image feature maps equally, ignoring the local semantics; (2) The text encoder is fixed during training, which should be trained with the image generator jointly to learn better text representations for image generation. To address these limitations, we propose a novel framework Semantic-Spatial Aware GAN, which is trained in an end-to-end fashion so that the text encoder can exploit better text information. Concretely, we introduce a novel Semantic-Spatial Aware Convolution Network, which (1) learns semantic-adaptive transformation conditioned on text to effectively fuse text features and image features, and (2) learns a mask map in a weakly-supervised way that depends on the current text-image fusion process in order to guide the transformation spatially. Experiments on the challenging COCO and CUB bird datasets demonstrate the advantage of our method over the recent state-of-the-art approaches, regarding both visual fidelity and alignment with input text description. Code is available at https://github.com/wtliao/text2image.
Context-Aware Layout to Image Generation with Enhanced Object Appearance
Mar 22, 2021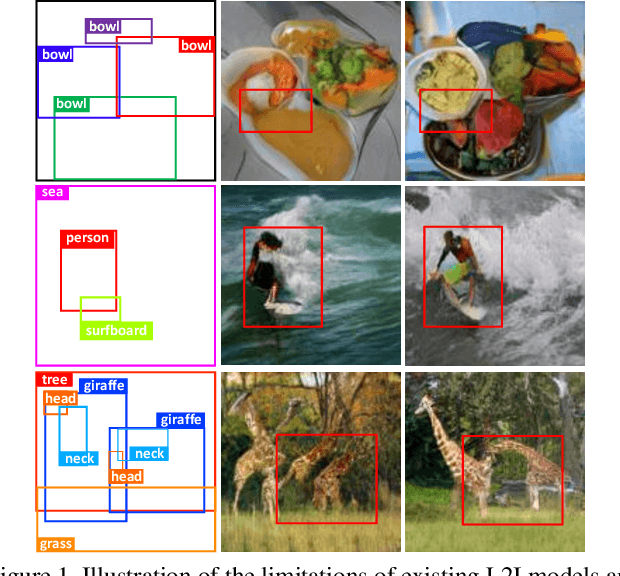
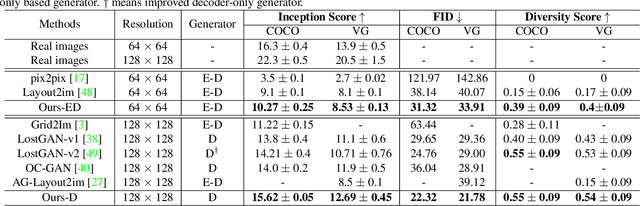


A layout to image (L2I) generation model aims to generate a complicated image containing multiple objects (things) against natural background (stuff), conditioned on a given layout. Built upon the recent advances in generative adversarial networks (GANs), existing L2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) the object-to-object as well as object-to-stuff relations are often broken and (2) each object's appearance is typically distorted lacking the key defining characteristics associated with the object class. We argue that these are caused by the lack of context-aware object and stuff feature encoding in their generators, and location-sensitive appearance representation in their discriminators. To address these limitations, two new modules are proposed in this work. First, a context-aware feature transformation module is introduced in the generator to ensure that the generated feature encoding of either object or stuff is aware of other co-existing objects/stuff in the scene. Second, instead of feeding location-insensitive image features to the discriminator, we use the Gram matrix computed from the feature maps of the generated object images to preserve location-sensitive information, resulting in much enhanced object appearance. Extensive experiments show that the proposed method achieves state-of-the-art performance on the COCO-Thing-Stuff and Visual Genome benchmarks.
Exploring Dynamic Context for Multi-path Trajectory Prediction
Nov 02, 2020
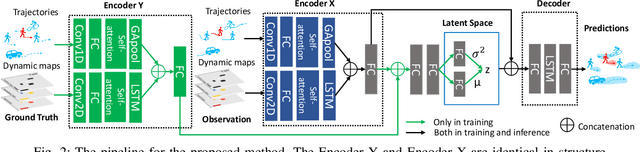
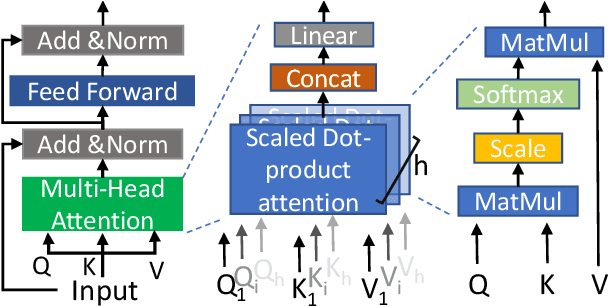
To accurately predict future positions of different agents in traffic scenarios is crucial for safely deploying intelligent autonomous systems in the real-world environment. However, it remains a challenge due to the behavior of a target agent being affected by other agents dynamically, and there being more than one socially possible paths the agent could take. In this paper, we propose a novel framework, named Dynamic Context Encoder Network (DCENet). In our framework, first, the spatial context between agents is explored by using self-attention architectures. Then, two LSTM encoders are trained to learn temporal context between steps by taking the observed trajectories and the extracted dynamic spatial context as input, respectively. The spatial-temporal context is encoded into a latent space using a Conditional Variational Auto-Encoder (CVAE) module. Finally, a set of future trajectories for each agent is predicted conditioned on the learned spatial-temporal context by sampling from the latent space, repeatedly. DCENet is evaluated on the largest and most challenging trajectory forecasting benchmark Trajnet and reports a new state-of-the-art performance. It also demonstrates superior performance evaluated on the benchmark InD for mixed traffic at intersections. A series of ablation studies are conducted to validate the effectiveness of each proposed module. Our code is available at https://github.com/wtliao/DCENet.
AMENet: Attentive Maps Encoder Network for Trajectory Prediction
Jun 15, 2020
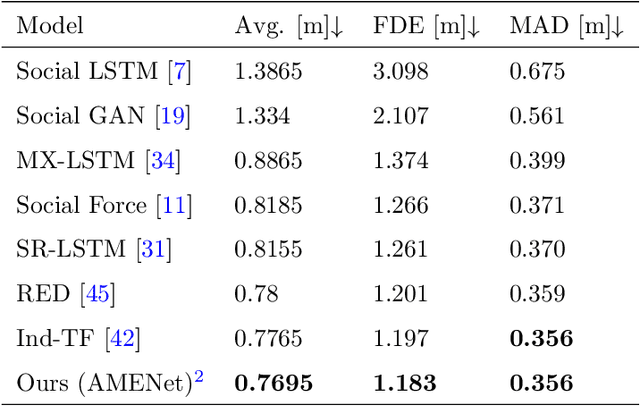
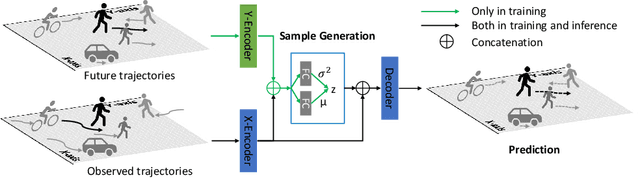
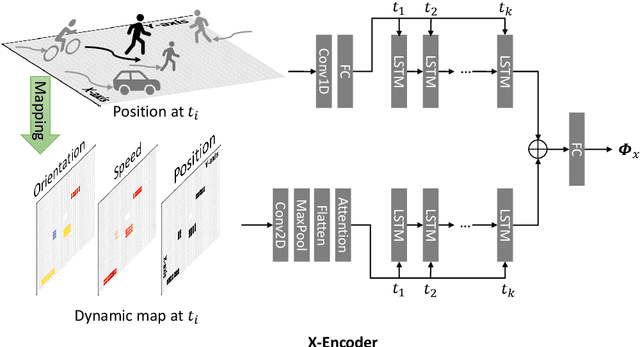
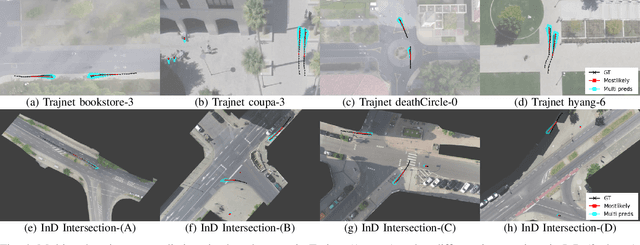
Trajectory prediction is a crucial task in different communities, such as intelligent transportation systems, photogrammetry, computer vision, and mobile robot applications. However, there are many challenges to predict the trajectories of heterogeneous road agents (e.g. pedestrians, cyclists and vehicles) at a microscopical level. For example, an agent might be able to choose multiple plausible paths in complex interactions with other agents in varying environments, and the behavior of each agent is affected by the various behaviors of its neighboring agents. To this end, we propose an end-to-end generative model named Attentive Maps Encoder Network (AMENet) for accurate and realistic multi-path trajectory prediction. Our method leverages the target road user's motion information (i.e. movement in xy-axis in a Cartesian space) and the interaction information with the neighboring road users at each time step, which is encoded as dynamic maps that are centralized on the target road user. A conditional variational auto-encoder module is trained to learn the latent space of possible future paths based on the dynamic maps and then used to predict multiple plausible future trajectories conditioned on the observed past trajectories. Our method reports the new state-of-the-art performance (final/mean average displacement (FDE/MDE) errors 1.183/0.356 meters) on benchmark datasets and wins the first place in the open challenge of Trajnet.
LR-CNN: Local-aware Region CNN for Vehicle Detection in Aerial Imagery
May 28, 2020
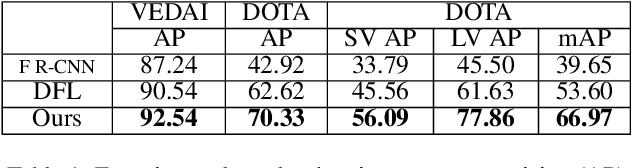

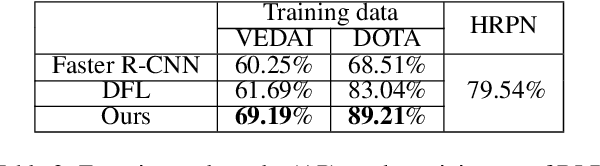
State-of-the-art object detection approaches such as Fast/Faster R-CNN, SSD, or YOLO have difficulties detecting dense, small targets with arbitrary orientation in large aerial images. The main reason is that using interpolation to align RoI features can result in a lack of accuracy or even loss of location information. We present the Local-aware Region Convolutional Neural Network (LR-CNN), a novel two-stage approach for vehicle detection in aerial imagery. We enhance translation invariance to detect dense vehicles and address the boundary quantization issue amongst dense vehicles by aggregating the high-precision RoIs' features. Moreover, we resample high-level semantic pooled features, making them regain location information from the features of a shallower convolutional block. This strengthens the local feature invariance for the resampled features and enables detecting vehicles in an arbitrary orientation. The local feature invariance enhances the learning ability of the focal loss function, and the focal loss further helps to focus on the hard examples. Taken together, our method better addresses the challenges of aerial imagery. We evaluate our approach on several challenging datasets (VEDAI, DOTA), demonstrating a significant improvement over state-of-the-art methods. We demonstrate the good generalization ability of our approach on the DLR 3K dataset.
Image Captioning through Image Transformer
Apr 29, 2020
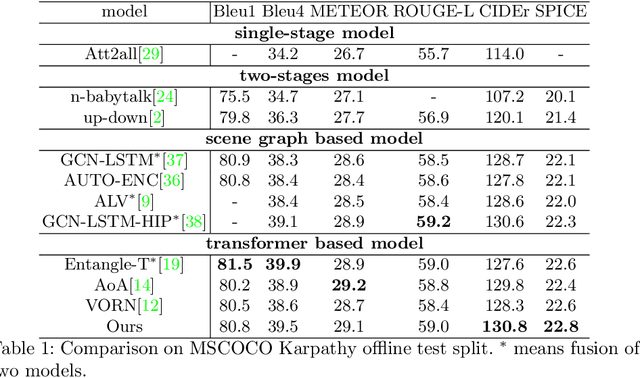
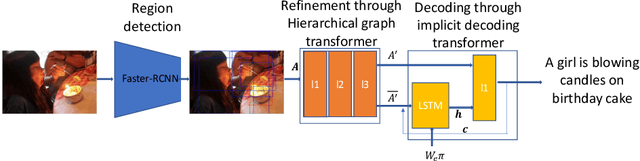
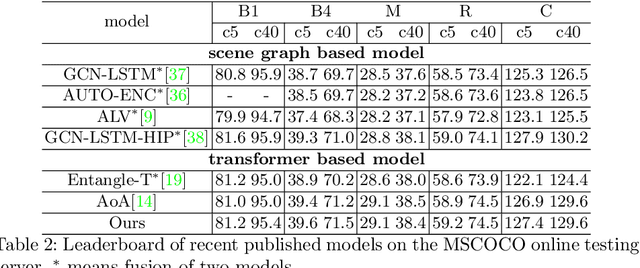
Automatic captioning of images is a task that combines the challenges of image analysis and text generation. One important aspect in captioning is the notion of attention: How to decide what to describe and in which order. Inspired by the successes in text analysis and translation, previous work have proposed the \textit{transformer} architecture for image captioning. However, the structure between the \textit{semantic units} in images (usually the detected regions from object detection model) and sentences (each single word) is different. Limited work has been done to adapt the transformer's internal architecture to images. In this work, we introduce the \textbf{\textit{image transformer}}, which consists of a modified encoding transformer and an implicit decoding transformer, motivated by the relative spatial relationship between image regions. Our design widen the original transformer layer's inner architecture to adapt to the structure of images. With only regions feature as inputs, our model achieves new state-of-the-art performance on both MSCOCO offline and online testing benchmarks.
FairNN- Conjoint Learning of Fair Representations for Fair Decisions
Apr 11, 2020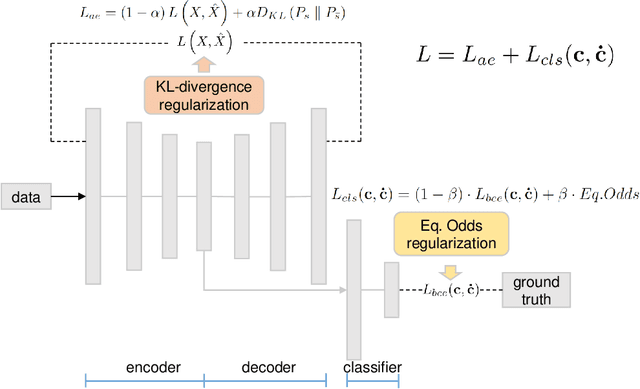

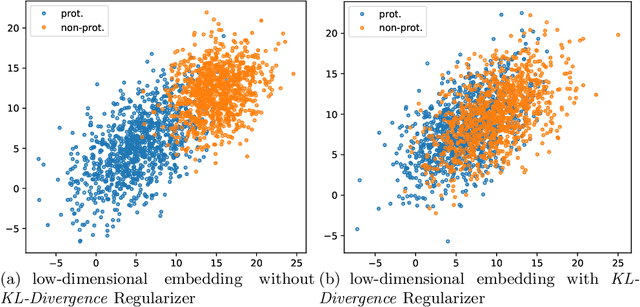
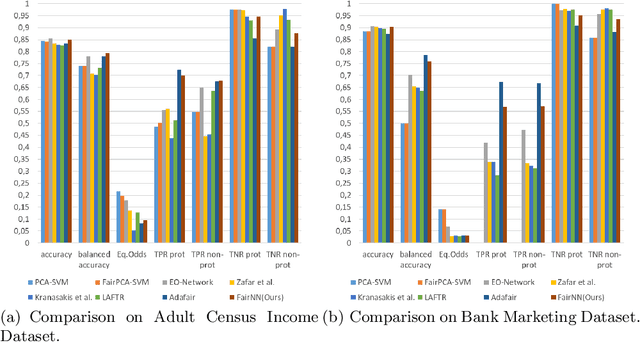
In this paper, we propose FairNN a neural network that performs joint feature representation and classification for fairness-aware learning. Our approach optimizes a multi-objective loss function in which (a) learns a fair representation by suppressing protected attributes (b) maintains the information content by minimizing a reconstruction loss and (c) allows for solving a classification task in a fair manner by minimizing the classification error and respecting the equalized odds-based fairness regularized. Our experiments on a variety of datasets demonstrate that such a joint approach is superior to separate treatment of unfairness in representation learning or supervised learning. Additionally, our regularizers can be adaptively weighted to balance the different components of the loss function, thus allowing for a very general framework for conjoint fair representation learning and decision making.