 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoreal Scene Reconstruction from an Egocentric Device
Jun 04, 2025In this paper, we investigate the challenges associated with using egocentric devices to photorealistic reconstruct the scene in high dynamic range. Existing methodologies typically assume using frame-rate 6DoF pose estimated from the device's visual-inertial odometry system, which may neglect crucial details necessary for pixel-accurate reconstruction. This study presents two significant findings. Firstly, in contrast to mainstream work treating RGB camera as global shutter frame-rate camera, we emphasize the importance of employing visual-inertial bundle adjustment (VIBA) to calibrate the precise timestamps and movement of the rolling shutter RGB sensing camera in a high frequency trajectory format, which ensures an accurate calibration of the physical properties of the rolling-shutter camera. Secondly, we incorporate a physical image formation model based into Gaussian Splatting, which effectively addresses the sensor characteristics, including the rolling-shutter effect of RGB cameras and the dynamic ranges measured by sensors. Our proposed formulation is applicable to the widely-used variants of Gaussian Splats representation. We conduct a comprehensive evaluation of our pipeline using the open-source Project Aria device under diverse indoor and outdoor lighting conditions, and further validate it on a Meta Quest3 device. Across all experiments, we observe a consistent visual enhancement of +1 dB in PSNR by incorporating VIBA, with an additional +1 dB achieved through our proposed image formation model. Our complete implementation, evaluation datasets, and recording profile are available at http://www.projectaria.com/photoreal-reconstruction/
Imaging for All-Day Wearable Smart Glasses
Apr 17, 2025In recent years smart glasses technology has rapidly advanced, opening up entirely new areas for mobile computing. We expect future smart glasses will need to be all-day wearable, adopting a small form factor to meet the requirements of volume, weight, fashionability and social acceptability, which puts significant constraints on the space of possible solutions. Additional challenges arise due to the fact that smart glasses are worn in arbitrary environments while their wearer moves and performs everyday activities. In this paper, we systematically analyze the space of imaging from smart glasses and derive several fundamental limits that govern this imaging domain. We discuss the impact of these limits on achievable image quality and camera module size -- comparing in particular to related devices such as mobile phones. We then propose a novel distributed imaging approach that allows to minimize the size of the individual camera modules when compared to a standard monolithic camera design. Finally, we demonstrate the properties of this novel approach in a series of experiments using synthetic data as well as images captured with two different prototype implementations.
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Sep 12, 2023



Egocentric, multi-modal data as available on future augmented reality (AR) devices provides unique challenges and opportunities for machine perception. These future devices will need to be all-day wearable in a socially acceptable form-factor to support always available, context-aware and personalized AI applications. Our team at Meta Reality Labs Research built the Aria device, an egocentric, multi-modal data recording and streaming device with the goal to foster and accelerate research in this area. In this paper, we describe the Aria device hardware including its sensor configuration and the corresponding software tools that enable recording and processing of such data.
ERF: Explicit Radiance Field Reconstruction From Scratch
Feb 28, 2022

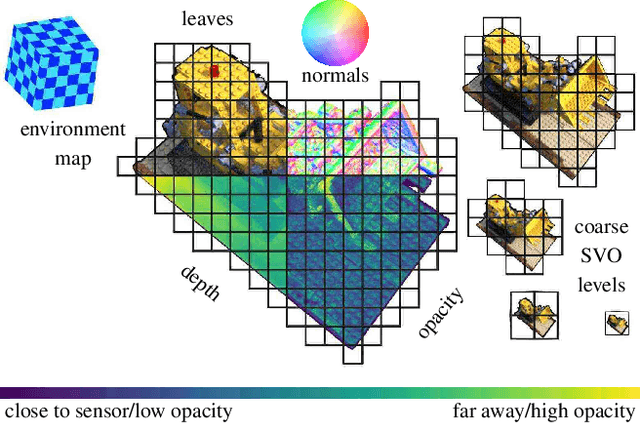

We propose a novel explicit dense 3D reconstruction approach that processes a set of images of a scene with sensor poses and calibrations and estimates a photo-real digital model. One of the key innovations is that the underlying volumetric representation is completely explicit in contrast to neural network-based (implicit) alternatives. We encode scenes explicitly using clear and understandable mappings of optimization variables to scene geometry and their outgoing surface radiance. We represent them using hierarchical volumetric fields stored in a sparse voxel octree. Robustly reconstructing such a volumetric scene model with millions of unknown variables from registered scene images only is a highly non-convex and complex optimization problem. To this end, we employ stochastic gradient descent (Adam) which is steered by an inverse differentiable renderer. We demonstrate that our method can reconstruct models of high quality that are comparable to state-of-the-art implicit methods. Importantly, we do not use a sequential reconstruction pipeline where individual steps suffer from incomplete or unreliable information from previous stages, but start our optimizations from uniformed initial solutions with scene geometry and radiance that is far off from the ground truth. We show that our method is general and practical. It does not require a highly controlled lab setup for capturing, but allows for reconstructing scenes with a vast variety of objects, including challenging ones, such as outdoor plants or furry toys. Finally, our reconstructed scene models are versatile thanks to their explicit design. They can be edited interactively which is computationally too costly for implicit alternatives.
Neural 3D Video Synthesis
Mar 03, 2021



We propose a novel approach for 3D video synthesis that is able to represent multi-view video recordings of a dynamic real-world scene in a compact, yet expressive representation that enables high-quality view synthesis and motion interpolation. Our approach takes the high quality and compactness of static neural radiance fields in a new direction: to a model-free, dynamic setting. At the core of our approach is a novel time-conditioned neural radiance fields that represents scene dynamics using a set of compact latent codes. To exploit the fact that changes between adjacent frames of a video are typically small and locally consistent, we propose two novel strategies for efficient training of our neural network: 1) An efficient hierarchical training scheme, and 2) an importance sampling strategy that selects the next rays for training based on the temporal variation of the input videos. In combination, these two strategies significantly boost the training speed, lead to fast convergence of the training process, and enable high quality results. Our learned representation is highly compact and able to represent a 10 second 30 FPS multi-view video recording by 18 cameras with a model size of just 28MB. We demonstrate that our method can render high-fidelity wide-angle novel views at over 1K resolution, even for highly complex and dynamic scenes. We perform an extensive qualitative and quantitative evaluation that shows that our approach outperforms the current state of the art. We include additional video and information at: https://neural-3d-video.github.io/
LR-CNN: Local-aware Region CNN for Vehicle Detection in Aerial Imagery
May 28, 2020
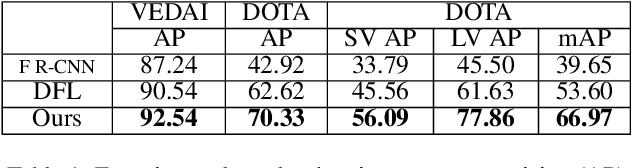

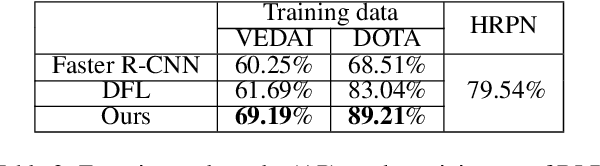
State-of-the-art object detection approaches such as Fast/Faster R-CNN, SSD, or YOLO have difficulties detecting dense, small targets with arbitrary orientation in large aerial images. The main reason is that using interpolation to align RoI features can result in a lack of accuracy or even loss of location information. We present the Local-aware Region Convolutional Neural Network (LR-CNN), a novel two-stage approach for vehicle detection in aerial imagery. We enhance translation invariance to detect dense vehicles and address the boundary quantization issue amongst dense vehicles by aggregating the high-precision RoIs' features. Moreover, we resample high-level semantic pooled features, making them regain location information from the features of a shallower convolutional block. This strengthens the local feature invariance for the resampled features and enables detecting vehicles in an arbitrary orientation. The local feature invariance enhances the learning ability of the focal loss function, and the focal loss further helps to focus on the hard examples. Taken together, our method better addresses the challenges of aerial imagery. We evaluate our approach on several challenging datasets (VEDAI, DOTA), demonstrating a significant improvement over state-of-the-art methods. We demonstrate the good generalization ability of our approach on the DLR 3K dataset.
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019



We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Background Subtraction with Real-time Semantic Segmentation
Dec 12, 2018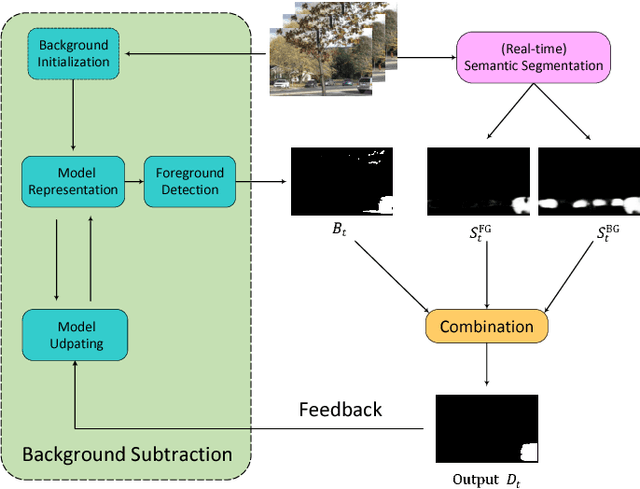
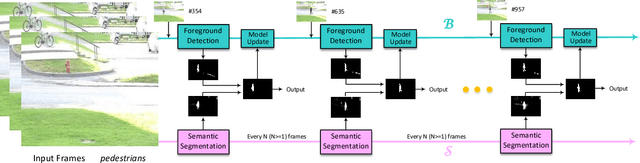


Accurate and fast foreground object extraction is very important for object tracking and recognition in video surveillance. Although many background subtraction (BGS) methods have been proposed in the recent past, it is still regarded as a tough problem due to the variety of challenging situations that occur in real-world scenarios. In this paper, we explore this problem from a new perspective and propose a novel background subtraction framework with real-time semantic segmentation (RTSS). Our proposed framework consists of two components, a traditional BGS segmenter $\mathcal{B}$ and a real-time semantic segmenter $\mathcal{S}$. The BGS segmenter $\mathcal{B}$ aims to construct background models and segments foreground objects. The real-time semantic segmenter $\mathcal{S}$ is used to refine the foreground segmentation outputs as feedbacks for improving the model updating accuracy. $\mathcal{B}$ and $\mathcal{S}$ work in parallel on two threads. For each input frame $I_t$, the BGS segmenter $\mathcal{B}$ computes a preliminary foreground/background (FG/BG) mask $B_t$. At the same time, the real-time semantic segmenter $\mathcal{S}$ extracts the object-level semantics ${S}_t$. Then, some specific rules are applied on ${B}_t$ and ${S}_t$ to generate the final detection ${D}_t$. Finally, the refined FG/BG mask ${D}_t$ is fed back to update the background model. Comprehensive experiments evaluated on the CDnet 2014 dataset demonstrate that our proposed method achieves state-of-the-art performance among all unsupervised background subtraction methods while operating at real-time, and even performs better than some deep learning based supervised algorithms. In addition, our proposed framework is very flexible and has the potential for generalization.
Detail-Preserving Pooling in Deep Networks
Apr 11, 2018
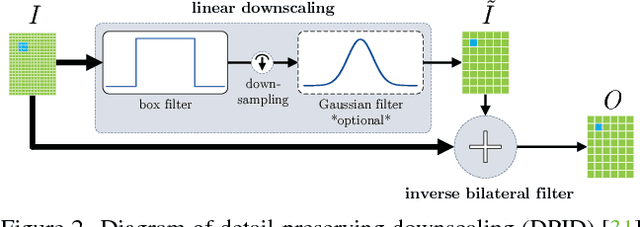
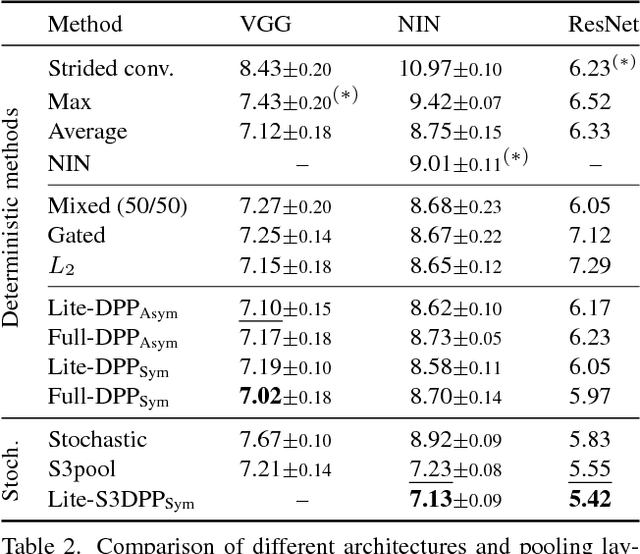
Most convolutional neural networks use some method for gradually downscaling the size of the hidden layers. This is commonly referred to as pooling, and is applied to reduce the number of parameters, improve invariance to certain distortions, and increase the receptive field size. Since pooling by nature is a lossy process, it is crucial that each such layer maintains the portion of the activations that is most important for the network's discriminability. Yet, simple maximization or averaging over blocks, max or average pooling, or plain downsampling in the form of strided convolutions are the standard. In this paper, we aim to leverage recent results on image downscaling for the purposes of deep learning. Inspired by the human visual system, which focuses on local spatial changes, we propose detail-preserving pooling (DPP), an adaptive pooling method that magnifies spatial changes and preserves important structural detail. Importantly, its parameters can be learned jointly with the rest of the network. We analyze some of its theoretical properties and show its empirical benefits on several datasets and networks, where DPP consistently outperforms previous pooling approaches.
Virtual Rephotography: Novel View Prediction Error for 3D Reconstruction
Jan 26, 2016



The ultimate goal of many image-based modeling systems is to render photo-realistic novel views of a scene without visible artifacts. Existing evaluation metrics and benchmarks focus mainly on the geometric accuracy of the reconstructed model, which is, however, a poor predictor of visual accuracy. Furthermore, using only geometric accuracy by itself does not allow evaluating systems that either lack a geometric scene representation or utilize coarse proxy geometry. Examples include light field or image-based rendering systems. We propose a unified evaluation approach based on novel view prediction error that is able to analyze the visual quality of any method that can render novel views from input images. One of the key advantages of this approach is that it does not require ground truth geometry. This dramatically simplifies the creation of test datasets and benchmarks. It also allows us to evaluate the quality of an unknown scene during the acquisition and reconstruction process, which is useful for acquisition planning. We evaluate our approach on a range of methods including standard geometry-plus-texture pipelines as well as image-based rendering techniques, compare it to existing geometry-based benchmarks, and demonstrate its utility for a range of use cases.