 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevAccSOL: Efficient and Transparent AI Vision Offloading for Mobile Robots
Mar 17, 2026Mobile robots are increasingly deployed for inspection, patrol, and search-and-rescue operations, relying on computer vision for perception, navigation, and autonomous decision-making. However, executing modern vision workloads onboard is challenging due to limited compute resources and strict energy constraints. While some platforms include embedded accelerators, these are typically tied to proprietary software stacks, leaving user-defined workloads to run on resource-constrained companion computers. We present vAccSOL, a framework for efficient and transparent execution of AI-based vision workloads across heterogeneous robotic and edge platforms. vAccSOL integrates two components: SOL, a neural network compiler that generates optimized inference libraries with minimal runtime dependencies, and vAccel, a lightweight execution framework that transparently dispatches inference locally on the robot or to nearby edge infrastructure. This combination enables hardware-optimized inference and flexible execution placement without requiring modifications to robot applications. We evaluate vAccSOL on a real-world testbed with a commercial quadruped robot and twelve deep learning models covering image classification, video classification, and semantic segmentation. Compared to a PyTorch compiler baseline, SOL achieves comparable or better inference performance. With edge offloading, vAccSOL reduces robot-side power consumption by up to 80% and edge-side power by up to 60% compared to PyTorch, while increasing vision pipeline frame rate by up to 24x, extending the operating lifetime of battery-powered robots.
Higher-Rank Irreducible Cartesian Tensors for Equivariant Message Passing
May 23, 2024



The ability to perform fast and accurate atomistic simulations is crucial for advancing the chemical sciences. By learning from high-quality data, machine-learned interatomic potentials achieve accuracy on par with ab initio and first-principles methods at a fraction of their computational cost. The success of machine-learned interatomic potentials arises from integrating inductive biases such as equivariance to group actions on an atomic system, e.g., equivariance to rotations and reflections. In particular, the field has notably advanced with the emergence of equivariant message-passing architectures. Most of these models represent an atomic system using spherical tensors, tensor products of which require complicated numerical coefficients and can be computationally demanding. This work introduces higher-rank irreducible Cartesian tensors as an alternative to spherical tensors, addressing the above limitations. We integrate irreducible Cartesian tensor products into message-passing neural networks and prove the equivariance of the resulting layers. Through empirical evaluations on various benchmark data sets, we consistently observe on-par or better performance than that of state-of-the-art spherical models.
SOL: Reducing the Maintenance Overhead for Integrating Hardware Support into AI Frameworks
May 19, 2022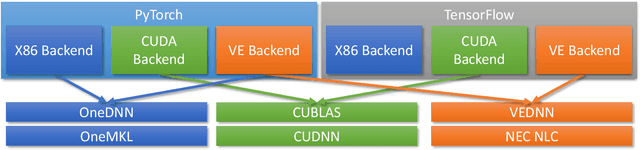
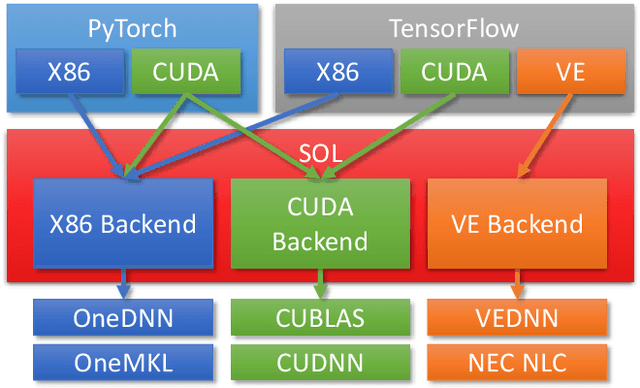
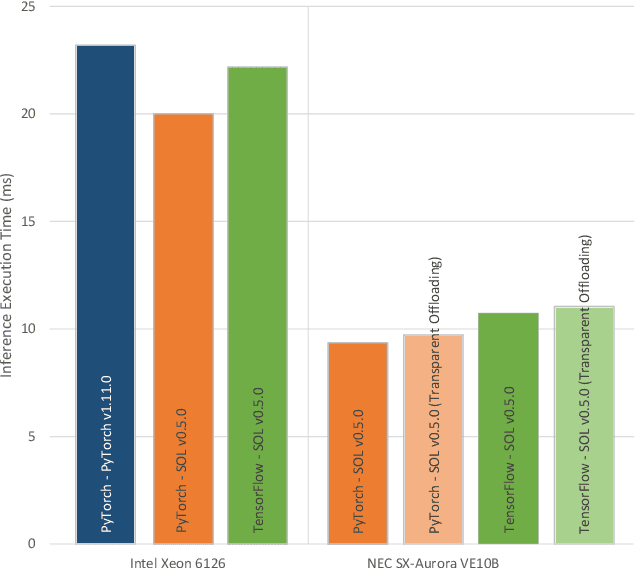

The increased interest in Artificial Intelligence (AI) raised the need for highly optimized and sophisticated AI frameworks. Starting with the Lua-based Torch many frameworks have emerged over time, such as Theano, Caffe, Chainer, CNTK, MxNet, PyTorch, DL4J, or TensorFlow. All of these provide a high level scripting API that allows users to easily design neural networks and run these on various kinds of hardware. What the user usually does not see is the high effort put into these frameworks to provide peak execution performance. While mainstream CPUs and GPUs have the "luxury" to have a wide spread user base in the open source community, less mainstream CPU, GPU or accelerator vendors need to put in a high effort to get their hardware supported by these frameworks. This includes not only the development of highly efficient compute libraries such as CUDNN, OneDNN or VEDNN but also supporting an ever growing number of simpler compute operations such as summation and multiplications. Each of these frameworks, nowadays, supports several hundred of unique operations, with tensors of various sizes, shapes and data types, which end up in thousands of compute kernels required for each device type. And the number of operations keeps increasing. That is why NEC Laboratories Europe started developing the SOL AI Optimization project already years ago, to deliver optimal performance to users while keeping the maintenance burden minimal.
SOL: Effortless Device Support for AI Frameworks without Source Code Changes
Mar 24, 2020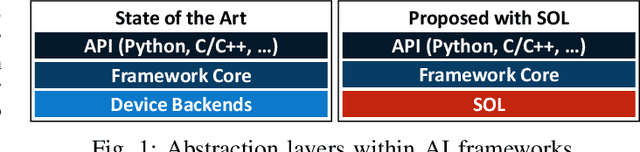
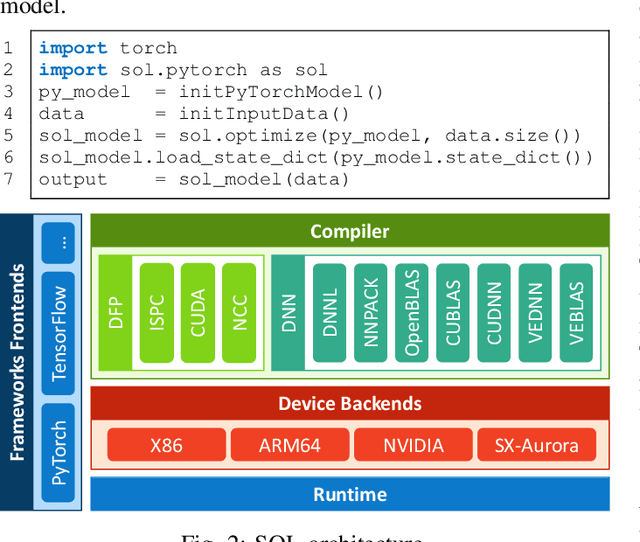
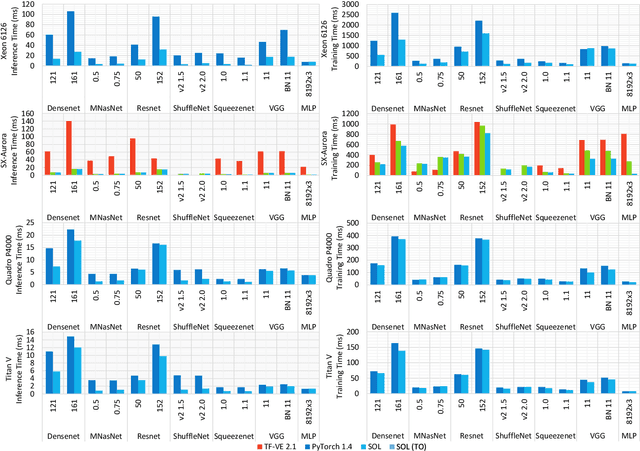
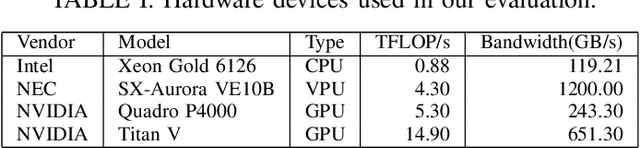
Modern high performance computing clusters heavily rely on accelerators to overcome the limited compute power of CPUs. These supercomputers run various applications from different domains such as simulations, numerical applications or artificial intelligence (AI). As a result, vendors need to be able to efficiently run a wide variety of workloads on their hardware. In the AI domain this is in particular exacerbated by the existence of a number of popular frameworks (e.g, PyTorch, TensorFlow, etc.) that have no common code base, and can vary in functionality. The code of these frameworks evolves quickly, making it expensive to keep up with all changes and potentially forcing developers to go through constant rounds of upstreaming. In this paper we explore how to provide hardware support in AI frameworks without changing the framework's source code in order to minimize maintenance overhead. We introduce SOL, an AI acceleration middleware that provides a hardware abstraction layer that allows us to transparently support heterogeneous hardware. As a proof of concept, we implemented SOL for PyTorch with three backends: CPUs, GPUs and vector processors.
BrainSlug: Transparent Acceleration of Deep Learning Through Depth-First Parallelism
Apr 23, 2018
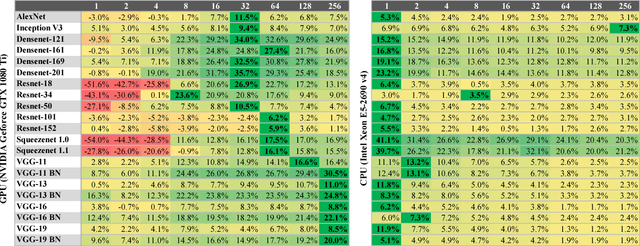
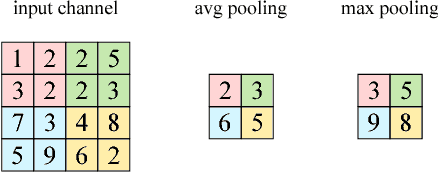
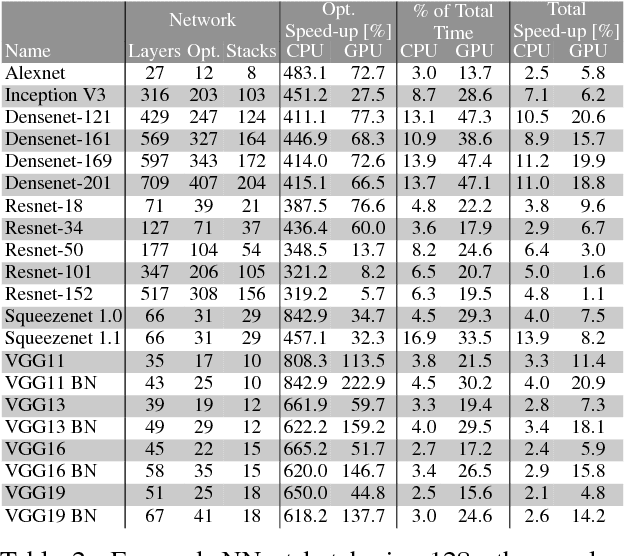
Neural network frameworks such as PyTorch and TensorFlow are the workhorses of numerous machine learning applications ranging from object recognition to machine translation. While these frameworks are versatile and straightforward to use, the training of and inference in deep neural networks is resource (energy, compute, and memory) intensive. In contrast to recent works focusing on algorithmic enhancements, we introduce BrainSlug, a framework that transparently accelerates neural network workloads by changing the default layer-by-layer processing to a depth-first approach, reducing the amount of data required by the computations and thus improving the performance of the available hardware caches. BrainSlug achieves performance improvements of up to 41.1% on CPUs and 35.7% on GPUs. These optimizations come at zero cost to the user as they do not require hardware changes and only need tiny adjustments to the software.
Detail-Preserving Pooling in Deep Networks
Apr 11, 2018
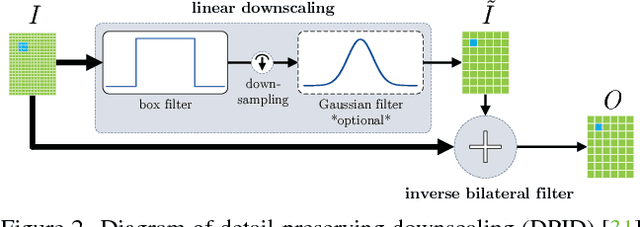
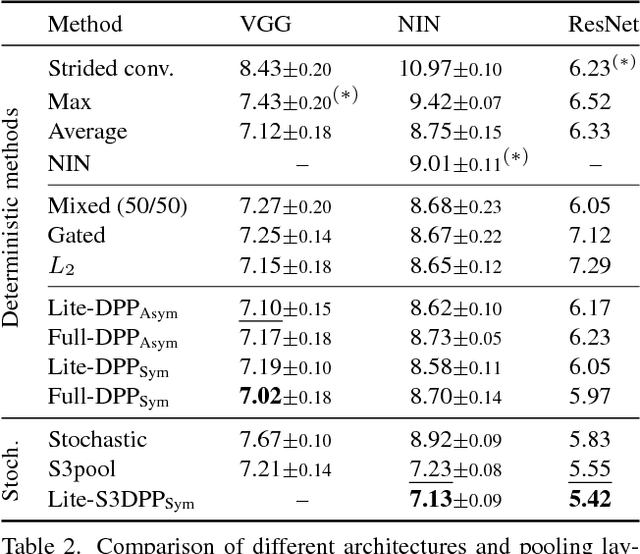
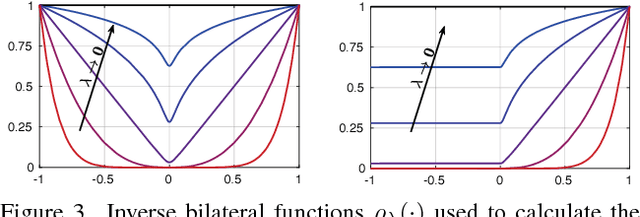
Most convolutional neural networks use some method for gradually downscaling the size of the hidden layers. This is commonly referred to as pooling, and is applied to reduce the number of parameters, improve invariance to certain distortions, and increase the receptive field size. Since pooling by nature is a lossy process, it is crucial that each such layer maintains the portion of the activations that is most important for the network's discriminability. Yet, simple maximization or averaging over blocks, max or average pooling, or plain downsampling in the form of strided convolutions are the standard. In this paper, we aim to leverage recent results on image downscaling for the purposes of deep learning. Inspired by the human visual system, which focuses on local spatial changes, we propose detail-preserving pooling (DPP), an adaptive pooling method that magnifies spatial changes and preserves important structural detail. Importantly, its parameters can be learned jointly with the rest of the network. We analyze some of its theoretical properties and show its empirical benefits on several datasets and networks, where DPP consistently outperforms previous pooling approaches.